“Animate Anyone” was released last night for making pose guide videos. Lets dive in.
Paper:
Project:
🧵1/ arxiv.org/abs/2311.17117
humanaigc.github.io/animate-anyone/

Paper:
Project:
🧵1/ arxiv.org/abs/2311.17117
humanaigc.github.io/animate-anyone/

First some examples because they are very good 2/
Okay so how did the pull this off? They made a bunch of modifications to the AnimateDiff architecture. First their arch overview 3/
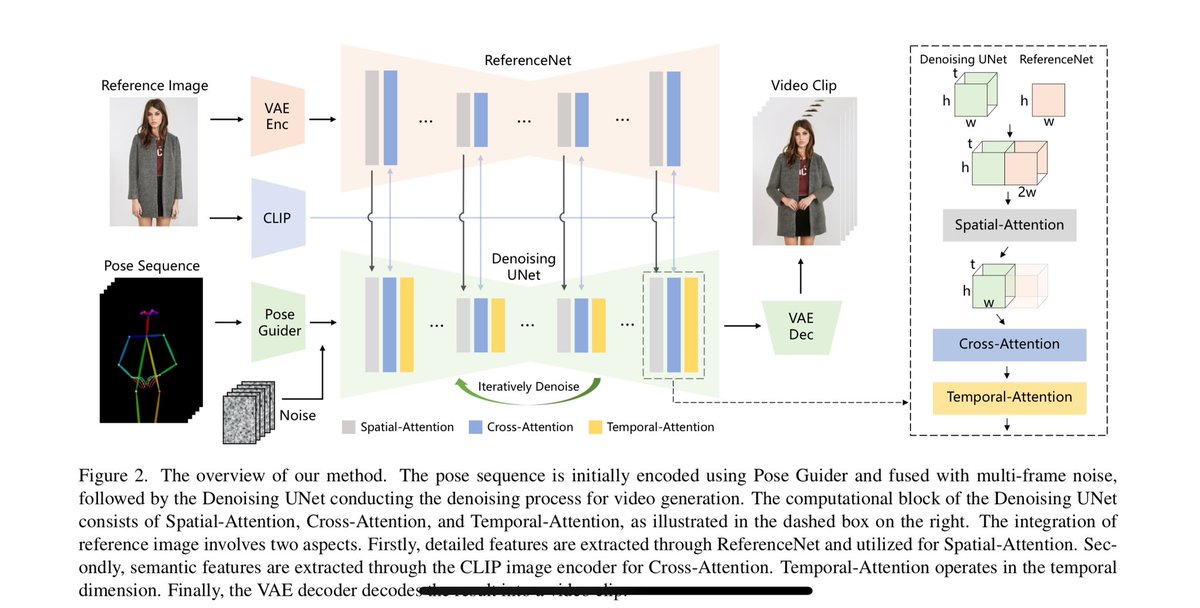
You input a picture of a character and then drive it with a sequence of poses.
To make sure the reference image is represent with high fidelity they CLIP encode it and send the embeddings to the cross-attention of denoising U-Net but that is not enough 4/
To make sure the reference image is represent with high fidelity they CLIP encode it and send the embeddings to the cross-attention of denoising U-Net but that is not enough 4/

They train an auxiliary “ReferenceNet” version of SD. This network is used to provide high fidelity information about the input image to the denoising AnimateDiff version of SD.
Here is how they do, but I’ll try to break this down 5/
Here is how they do, but I’ll try to break this down 5/

The self-attention features of the ReferenceNet are concatenated width-wise to the denoising network features. Then they perform self-attention, but the output features are too wide, so they chop off the extra width before passing them to the next block.
Perf hit not bad 6/
Perf hit not bad 6/

The poses are encoded using a ControlNet convolution network instead of VAE, called the “Pose Guider”. Fine, but not sure why that is better than a VAE oh well. 7/

Two stage training. First, initialize both the denoising U-Net and ReferenceNet to a SD checkpoint. The Pose Guider is gaussian initialized with zero’d projection portion as is standard for ControlNet
The goal of stage one is spatial training so reconstruction of the frames 8/
The goal of stage one is spatial training so reconstruction of the frames 8/

Then they train the temporal attention in isolation as is standard for AnimateDiff training.
During inference they resize the poses to the size of the input character. For longer generation they use a trick from “Editable Dance Generation From Music” () 9/ arxiv.org/abs/2211.10658
During inference they resize the poses to the size of the input character. For longer generation they use a trick from “Editable Dance Generation From Music” () 9/ arxiv.org/abs/2211.10658

I’m still unclear on that final bit about long duration animations. They are generating more than 24 frames in the examples and they are incredibly coherent so it obviously works well.
Hopefully the code comes out soon, but if not the paper is detailed enough to repro. 10/
Hopefully the code comes out soon, but if not the paper is detailed enough to repro. 10/
Digging into the EDGE paper more, I think they are using in-painting to generate longer animations. I've tried an in-painting like approach with AnimateDiff to make longer animations, it doesn't work well in general. Maybe it works here because of the extra conditioning 🤷♂️11/
• • •
Missing some Tweet in this thread? You can try to
force a refresh