🧵 The historic NYT v. @OpenAI lawsuit filed this morning, as broken down by me, an IP and AI lawyer, general counsel, and longtime tech person and enthusiast.
Tl;dr - It's the best case yet alleging that generative AI is copyright infringement. Thread. 👇
Tl;dr - It's the best case yet alleging that generative AI is copyright infringement. Thread. 👇

1/ First, the complaint clearly lays out the claim of copyright infringement, highlighting the 'access & substantial similarity' between NYT's articles and ChatGPT's outputs. Key fact: NYT is the single biggest proprietary data set in Common Crawl used to train GPT.

2/ The visual evidence of copying in the complaint is stark. Copied text in red, new GPT words in black—a contrast designed to sway a jury. See Exhibit J here.
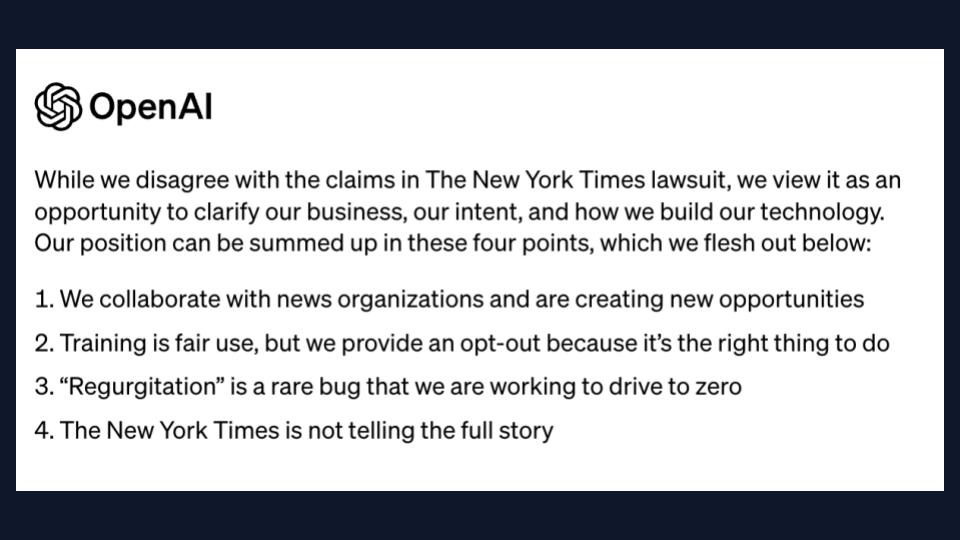
My take? OpenAI can't really defend this practice without some heavy changes to the instructions and a whole lot of litigating about how the tech works. It will be smarter to settle than fight.
My take? OpenAI can't really defend this practice without some heavy changes to the instructions and a whole lot of litigating about how the tech works. It will be smarter to settle than fight.

3/ 🦸 NYT is a great plaintiff. It isn't just about articles; it's about originality and the creative process. Their investigative journalism, like an in-depth taxi lending exposé cited in the complaint, goes beyond mere labor—it’s creativity at its core.
But here's a twist: copyright protects creativity, not effort. While the taxi article's 600 interviews are impressive, it's the innovation in reporting that matters legally. By the way, this is a very sharp contrast with the suit against GitHub Copilot, which cited only a few lines of code that were open source.
But here's a twist: copyright protects creativity, not effort. While the taxi article's 600 interviews are impressive, it's the innovation in reporting that matters legally. By the way, this is a very sharp contrast with the suit against GitHub Copilot, which cited only a few lines of code that were open source.
4/ ❌ Failed negotiations suggest damages for NYT. OpenAI's already licensed from other media outlets like Politico.
OAI's refusal to strike a deal with NYT (who says they reached out in April) may prove costly, especially as OpenAI profits grow and more and more examples happen. My spicy hypothesis? OpenAI thought they could get out of it for 7 or 8 figures. NYT is looking for more and an ongoing royalty.
OAI's refusal to strike a deal with NYT (who says they reached out in April) may prove costly, especially as OpenAI profits grow and more and more examples happen. My spicy hypothesis? OpenAI thought they could get out of it for 7 or 8 figures. NYT is looking for more and an ongoing royalty.
5/ 😈 The complaint paints @OpenAI as profit-driven and closed. It contrasts this with the public good of journalism. This narrative could prove powerful in court, weighing the societal value of copyright against tech innovation. Notably, this balance of good v evil has been at issue in every major copyright case - from the Betamax case to the Feist finding telephone books not copyrightable. The complaint even mentions the board and Sam Altman drama.

6/ 🚫 Misinformation allegations add a clever twist. The complaint pulls in something people are scared of - hallucinations - and makes a case out of it, citing examples where elements of NYT articles were made up.
🍊 Most memorable example? Alleging Bing says the NYT published an article orange juice causes lymphoma.
🍊 Most memorable example? Alleging Bing says the NYT published an article orange juice causes lymphoma.
7/ 💼 Another interesting point: NYT got really good lawyers. Susman Godfrey has a great reputation and track record taking on tech. This isn't a quick cash grab like the lawsuits filed a week after ChatGPT; it's a strategic legal challenge.
End/ The case could be a watershed moment for AI and copyright. A lot of folks saying OpenAI should have paid. We'll see!
What's at stake? The future of AI innovation and the protection of creative content. Stay tuned.
#OpenAI #IPLaw #Copyright #NYTimes
What's at stake? The future of AI innovation and the protection of creative content. Stay tuned.
#OpenAI #IPLaw #Copyright #NYTimes
• • •
Missing some Tweet in this thread? You can try to
force a refresh