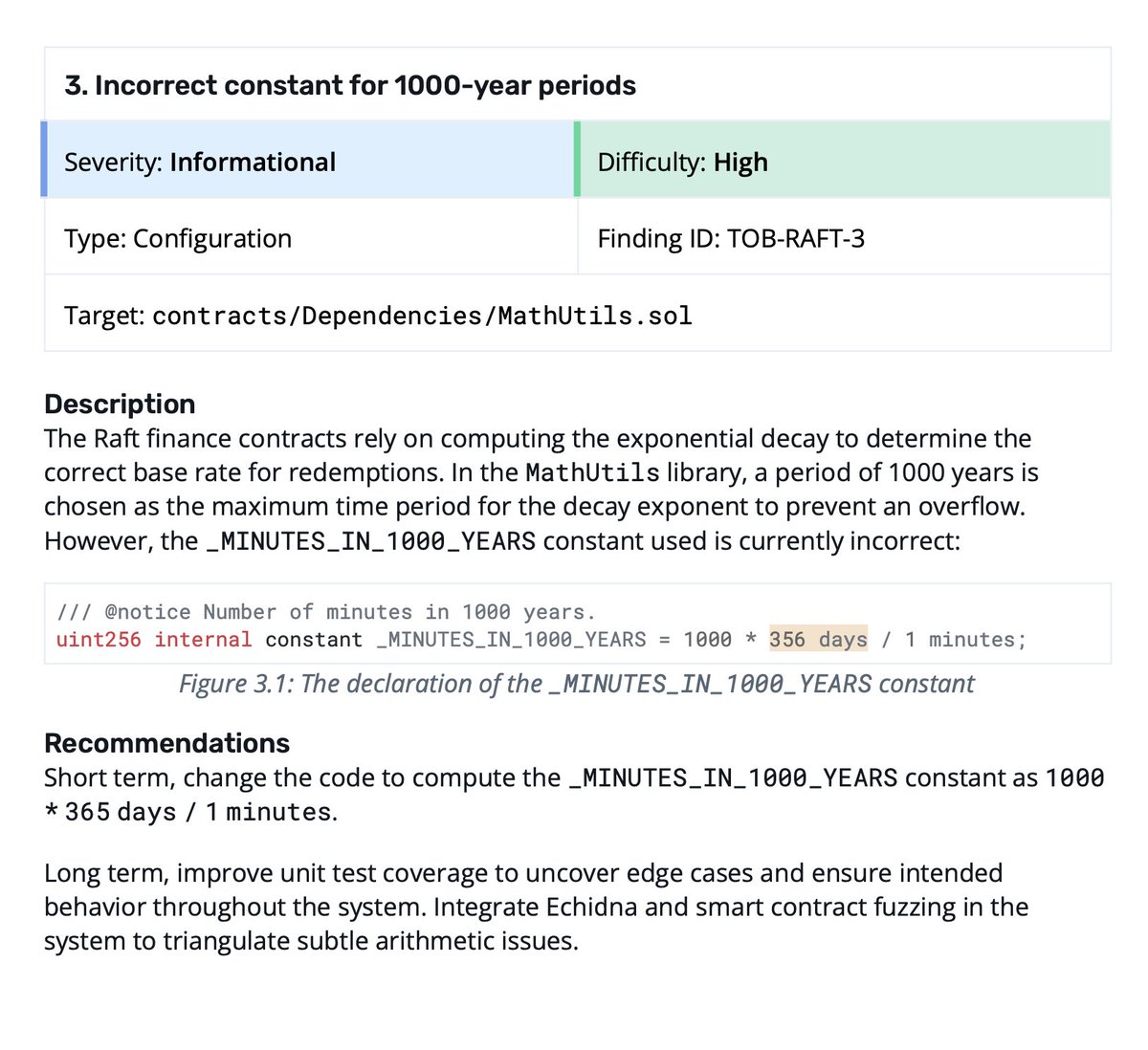
Today, we are disclosing LeftoverLocals, a vulnerability that allows listening to LLM responses through leaked GPU local memory created by another process on Apple, Qualcomm, AMD, and Imagination GPUs (CVE-2023-4969) buff.ly/48RDP68
Our PoC can listen to another user's llama.cpp session across process or container boundaries. LeftoverLocals can leak ~5.5 MB per GPU invocation on an AMD Radeon RX 7900 XT running a 7B model on llama.cpp, adding up to ~181 MB for each LLM query. buff.ly/41WKaLf
LeftoverLocals impacts the security posture of GPU applications, especially LLMs and ML models that run on impacted GPU platforms. It highlights that many parts of the ML development stack, specifically GPUs, have unknown security risks. Read more: buff.ly/3SjHYu0


We encourage you to reach out if you are affected by these issues or want our help discovering more like them in your company. Our team has new and novel expertise to attack and secure ML systems, and we are here to help. buff.ly/40W1jUV
• • •
Missing some Tweet in this thread? You can try to
force a refresh