
OP is correct that SD VAE deviates from typical behavior.
but there are several things wrong with their line of reasoning and the really unnecessary sounding of alarms. I did some investigations in this thread to show you can rest assured, its really not a big deal.
but there are several things wrong with their line of reasoning and the really unnecessary sounding of alarms. I did some investigations in this thread to show you can rest assured, its really not a big deal.
https://twitter.com/Norod78/status/1753032815401107491

first of all, the irregularity of the VAE is mostly intentional. Typically the KL term allows for more navigable latent spaces and more semantic compression. It ensures that nearby points map to similar images. In the extreme, it itself can actually be a generative model.

This article shows an example of a more semantic latent space.
the LDM authors seem to opt for the low KL term as it favors better 1:1 reconstruction rather than semantic generation, which we offshore to the diffusion model anyway medium.com/mlearning-ai/l…
the LDM authors seem to opt for the low KL term as it favors better 1:1 reconstruction rather than semantic generation, which we offshore to the diffusion model anyway medium.com/mlearning-ai/l…

the SD VAE latent space, i would really call, a glamorized pixel space... spatial relations are almost perfectly preserved, altering values in channels correspond to similar changes you'd see in adjusting RGB channels as shown here
huggingface.co/blog/TimothyAl…
huggingface.co/blog/TimothyAl…
OP mentions that vae latent spaces should be robust to noise, this is a bit unintutive as if we couldn't noise our data effectively then we wouldn't be able to actually train a diffusion model to reverse noising.
plus images aren't robust to noise yet pixel diffusion models work
plus images aren't robust to noise yet pixel diffusion models work
lets go through some of OPs claims, as there are some interesting things, but also a quick jump to a conclusion i couldn't really follow
first of all OP is correct that all images encoded have this "black hole" in their logvar outputs, across all channels
first of all OP is correct that all images encoded have this "black hole" in their logvar outputs, across all channels




i've found that most values in these maps sit around -17 to -23, the "black holes" are all -30 on the dot somehow. the largest values go up to -13
however, these are all insanely small numbers.
e^-13 comes out to 2^-6
e^-17 comes out to 4^-8
however, these are all insanely small numbers.
e^-13 comes out to 2^-6
e^-17 comes out to 4^-8
meanwhile mean predictions are all 1 to 2 digit numbers.
our largest logvar value, e^-13 turns into 0.0014 STD when we sample
if we take the top left value -5.6355 and skew that by 2 std, we have 5.6327
depending on the precision (bf16) you use, this might not even do anything
our largest logvar value, e^-13 turns into 0.0014 STD when we sample
if we take the top left value -5.6355 and skew that by 2 std, we have 5.6327
depending on the precision (bf16) you use, this might not even do anything

when you instead plot the STDs, the maps dont look so scary anymore,
if anything! both of these show some strange pathologically large single pixel values in strange places like the hat of the woman and bottom right corner of the man. but even then this doesnt follow
if anything! both of these show some strange pathologically large single pixel values in strange places like the hat of the woman and bottom right corner of the man. but even then this doesnt follow


So a hypothesis could be that information in the mean preds, in the areas covered by the black holes, is critical to the reconstruction, so the STD must be as low as slight perturbations might change the output
first ill explain why this is illogical then show its not the case
first ill explain why this is illogical then show its not the case
1. as i've showed even our largest values very well might not influence the output if you're using half precision
2. if 0.001 decimal movements could reflect drastic changes in output, you would see massive gradients during training that are extremely unstable
now empiricals
2. if 0.001 decimal movements could reflect drastic changes in output, you would see massive gradients during training that are extremely unstable
now empiricals
ive now manually pushed up the values of the black hole to be similar to its neighbors, now lets decode it an see what happens
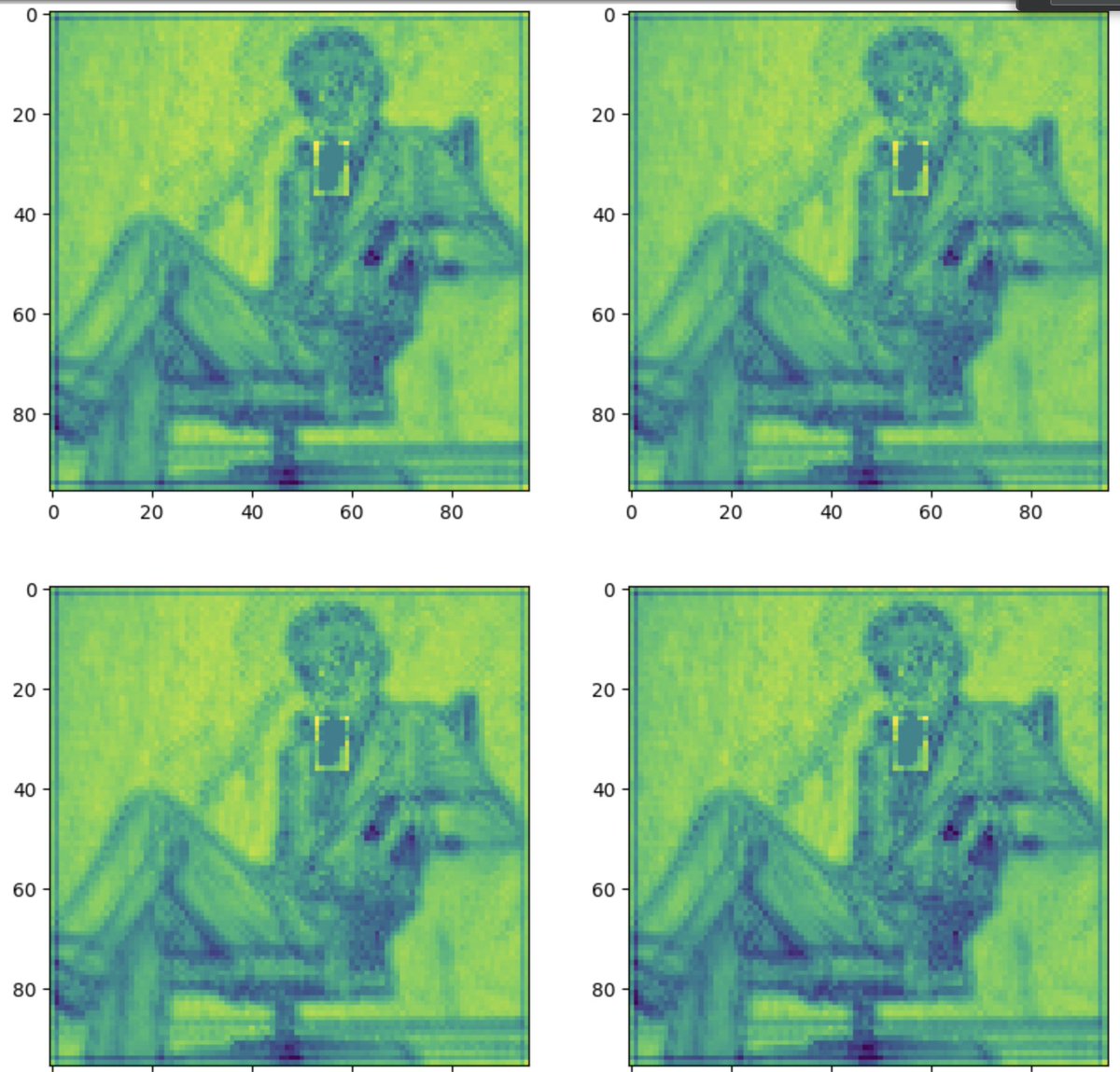
virtually the same image, no sign of global information being stored here

to go the extra mile, you can see there's really little to no difference

i was skeptical as soon as I saw "storing information in the logvar", variance, in our case, is almost like the inverse of information, i'd be more inclined to think VAE is storing global info in its mean predictions, which it probably is to some degree, probably not a bad thing
And to really tie it all up, you don't even have to use the logvar! you can actually remove all stochasticity and take the mean prediction without ever sampling, and the result is still the same!



at the end of the day too, if there was unusual pathological behavior, it would have to be reflected in the end result of the latents, not just the distribution parameters.
• • •
Missing some Tweet in this thread? You can try to
force a refresh






