Introducing Nomic Embed - the first fully open long context text embedder to beat OpenAI
- Open source, open weights, open data
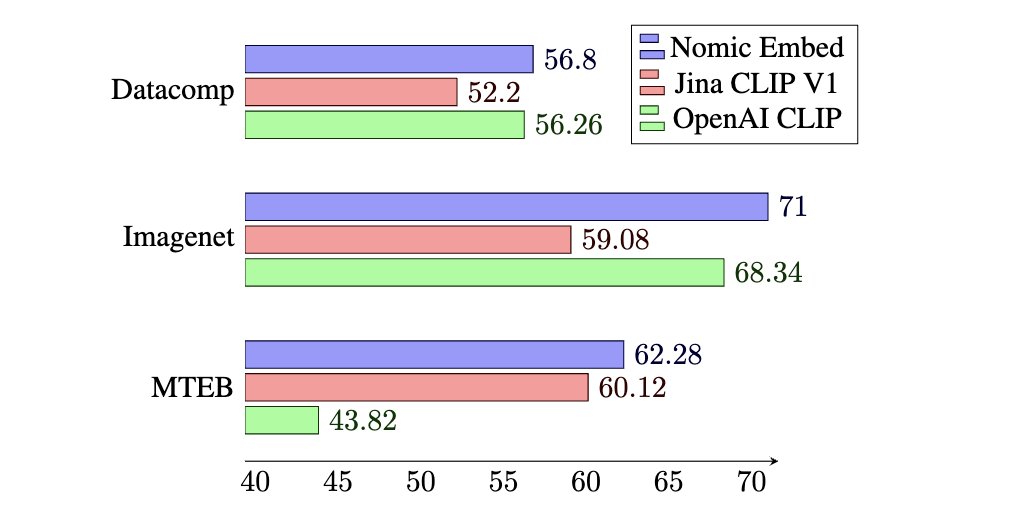
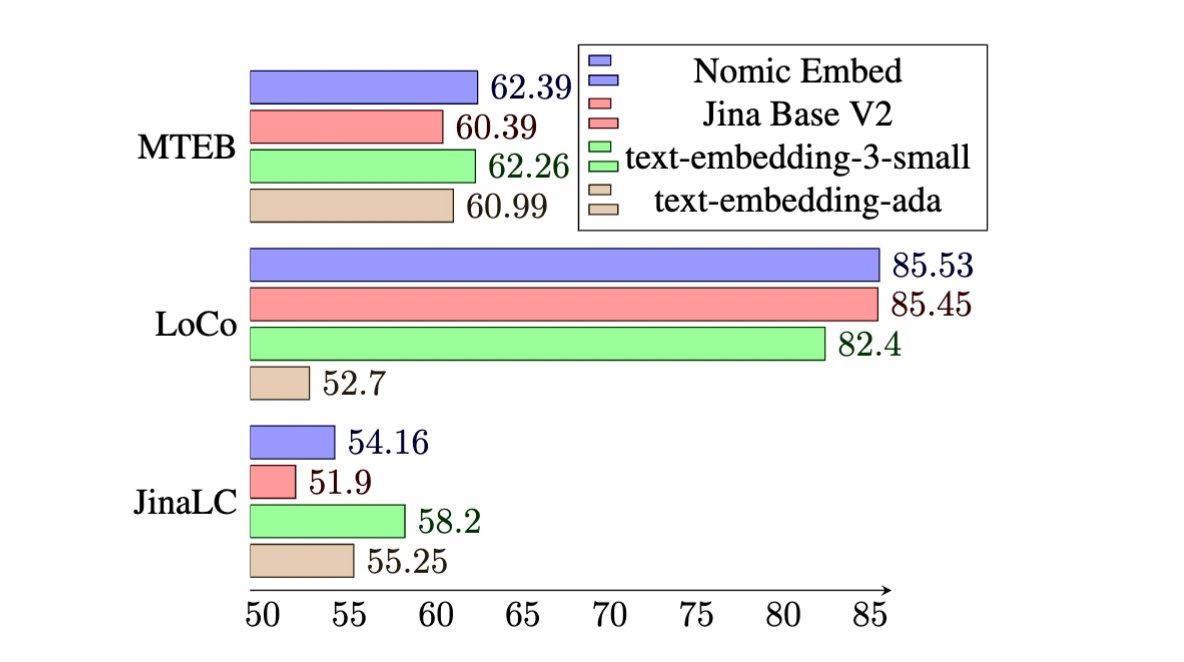
- Beats OpenAI text-embeding-3-small and Ada on short and long context benchmarks
- Day 1 integrations with @langchain, @llama-index, @MongoDB
- Open source, open weights, open data
- Beats OpenAI text-embeding-3-small and Ada on short and long context benchmarks
- Day 1 integrations with @langchain, @llama-index, @MongoDB
Open source models are not replicable unless you have access to their training data.
We release our training dataset of 235M curated text pairs to enable anyone to replicate Nomic Embed from scratch.
Blog: blog.nomic.ai/posts/nomic-em…

We release our training dataset of 235M curated text pairs to enable anyone to replicate Nomic Embed from scratch.
Blog: blog.nomic.ai/posts/nomic-em…
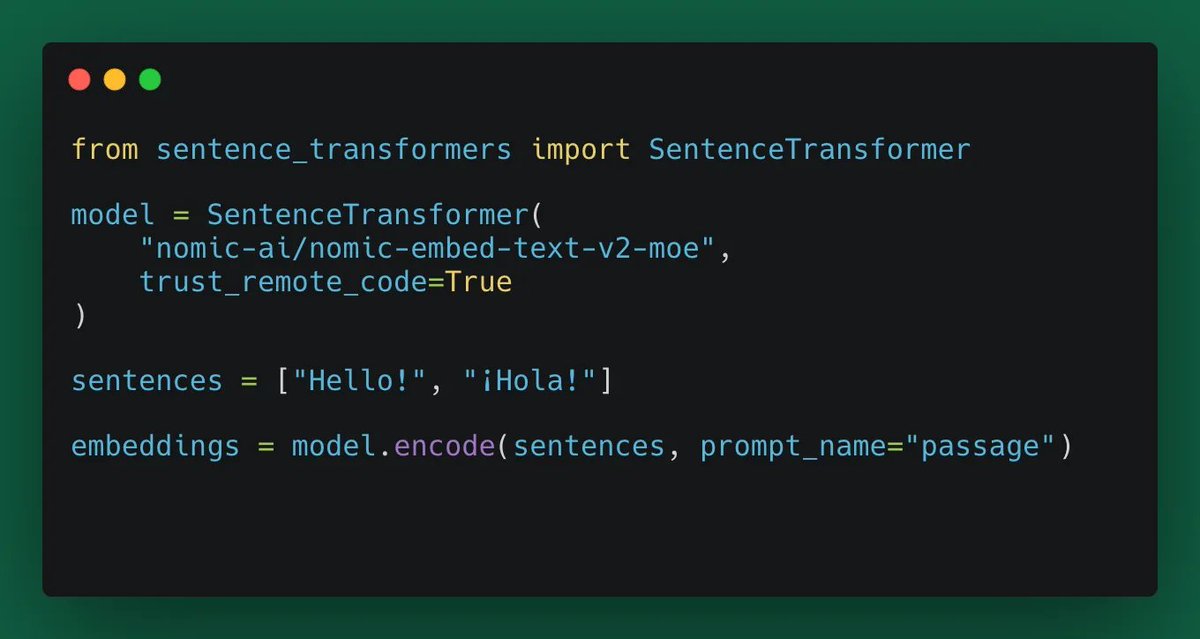
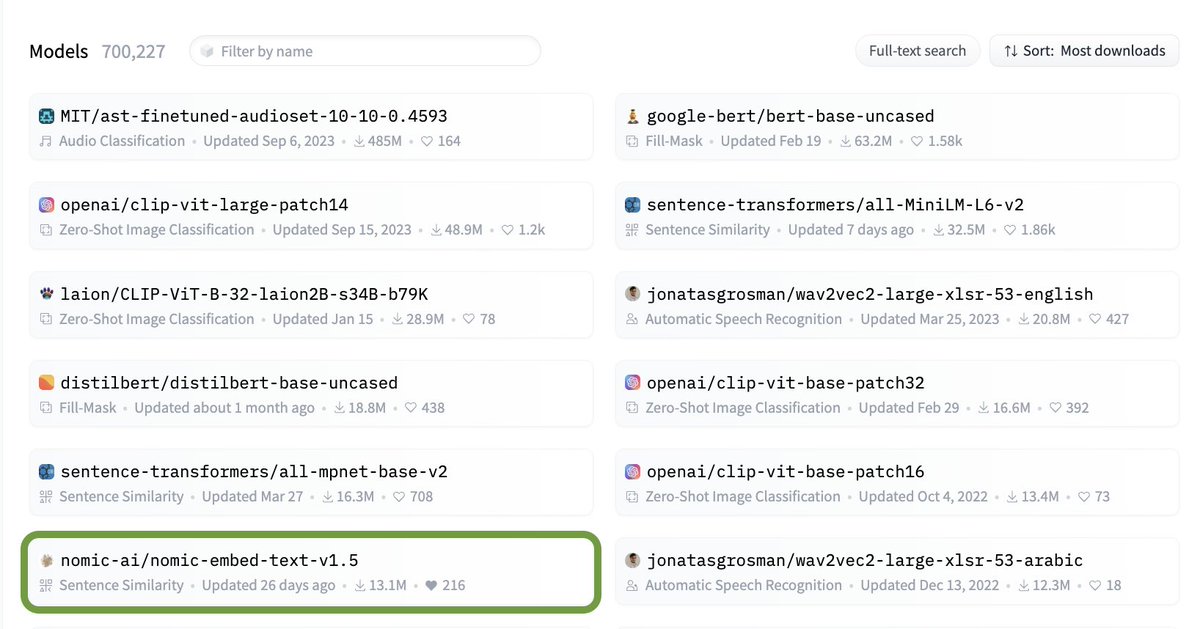
You can find the model on @huggingface:
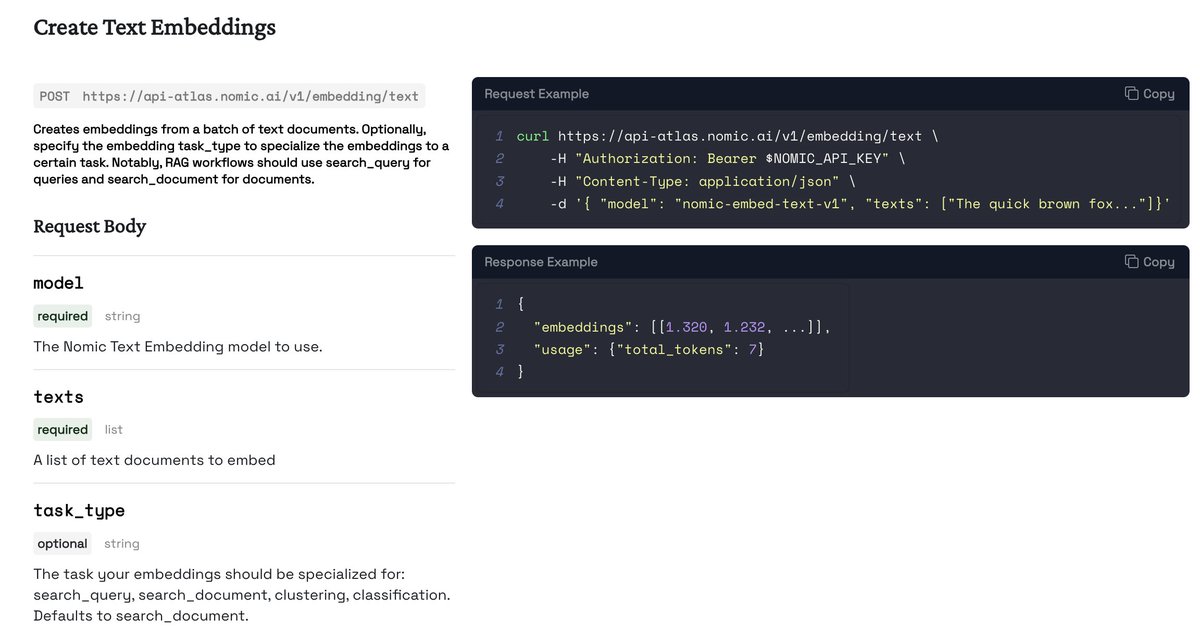
The easiest way to use Nomic Embed in a managed service is through the Nomic Embedding API:
huggingface.co/nomic-ai/nomic…
docs.nomic.ai/reference/endp…
The easiest way to use Nomic Embed in a managed service is through the Nomic Embedding API:
huggingface.co/nomic-ai/nomic…
docs.nomic.ai/reference/endp…
Model details:
- 137M parameters for easy deployment
- 5 days of 8xH100 time to train
- Code and data:
- Detailed Technical Report:
github.com/nomic-ai/contr…
static.nomic.ai/reports/2024_N…
- 137M parameters for easy deployment
- 5 days of 8xH100 time to train
- Code and data:
- Detailed Technical Report:
github.com/nomic-ai/contr…
static.nomic.ai/reports/2024_N…

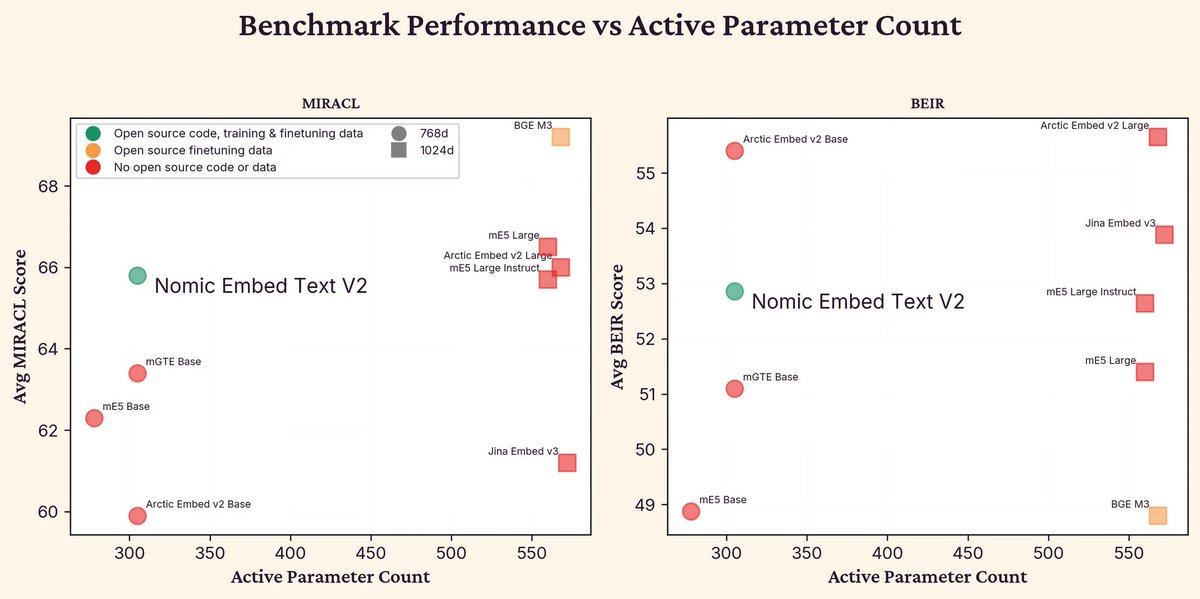
Embedding evaluation is broken. Benchmarks like MTEB are not sufficient for capturing all aspects of model behavior.
You can discover systematic differences in model embedding spaces using Nomic Atlas
Comparing nomic-embed-text-v1 and OpenAI Ada 002 embeddings.
blog.nomic.ai/posts/nomic-em…
You can discover systematic differences in model embedding spaces using Nomic Atlas
Comparing nomic-embed-text-v1 and OpenAI Ada 002 embeddings.
blog.nomic.ai/posts/nomic-em…
Day 1 Integrations:
- Build a RAG app with Nomic Embed, @MongoDB and @NousResearch:
- Build a fully open retriever with Nomic Embed and @llamaindex:
- Integrated with @langchain
blog.nomic.ai/posts/nomic-em…
medium.com/@llama_index
python.langchain.com/docs/integrati…
- Build a RAG app with Nomic Embed, @MongoDB and @NousResearch:
- Build a fully open retriever with Nomic Embed and @llamaindex:
- Integrated with @langchain
blog.nomic.ai/posts/nomic-em…
medium.com/@llama_index
python.langchain.com/docs/integrati…
We also launch the Nomic Embedding API
- 1M Free tokens!
- Production ready embedding inference API including task specific embedding customizations.
- Deep integration with Atlas Datasets
- New models incoming 👀
Sign up at atlas.nomic.ai
- 1M Free tokens!
- Production ready embedding inference API including task specific embedding customizations.
- Deep integration with Atlas Datasets
- New models incoming 👀
Sign up at atlas.nomic.ai
Integrations:
@LangChainAI integration:
@llama_index integration:
@MongoDB :
python.langchain.com/docs/integrati…
medium.com/@llama_index
blog.nomic.ai/posts/nomic-em…
@LangChainAI integration:
@llama_index integration:
@MongoDB :
python.langchain.com/docs/integrati…
medium.com/@llama_index
blog.nomic.ai/posts/nomic-em…
• • •
Missing some Tweet in this thread? You can try to
force a refresh