Heute hab ich für Freunde der Think Tanks eine Kleinigkeit.
Ein Tool, mit denen wir die Tweets von Agenda Austria und Momentum Institut ein bissl genauer anschauen können.
Agenda Austria:
Momentum Institut:
🧵 exxpress.marioslab.io/twitter/agenda…
exxpress.marioslab.io/twitter/mom_in…

Ein Tool, mit denen wir die Tweets von Agenda Austria und Momentum Institut ein bissl genauer anschauen können.
Agenda Austria:
Momentum Institut:
🧵 exxpress.marioslab.io/twitter/agenda…
exxpress.marioslab.io/twitter/mom_in…


In den folgenden Tweets ist Agenda Austria immer links, und Momentum Institut rechts. Höhö.
Die Datensätze beinhalten alle Tweets, Retweets und Threads der beiden "Institute".
Agenda Austria: 11.5.2023 - heute, 823 Tweets
Momentum Institut: 7.7.2023 - heute, 573 Tweets
Die Datensätze beinhalten alle Tweets, Retweets und Threads der beiden "Institute".
Agenda Austria: 11.5.2023 - heute, 823 Tweets
Momentum Institut: 7.7.2023 - heute, 573 Tweets
Die Rohdaten könnt ihr hier runterladen:
Agenda Austria
Momentum Institut
Diese wurden mit Tixo und Spucke aus den Twitter Frontend Requests handgeschöpft (aka manuell) extrahiert. Lemon Suk will $100 dafür. Nope.exxpress.marioslab.io/data/agendaaus…
exxpress.marioslab.io/data/mom_inst.…
Agenda Austria
Momentum Institut
Diese wurden mit Tixo und Spucke aus den Twitter Frontend Requests handgeschöpft (aka manuell) extrahiert. Lemon Suk will $100 dafür. Nope.exxpress.marioslab.io/data/agendaaus…
exxpress.marioslab.io/data/mom_inst.…
Diese Rohdaten sind ein bissl suboptimal zur einfachen Verarbeitung, drum gibts auch aufgeräumte Daten, falls sich wer spielen will:
(Ignore the warnings :p)
Soda, schau ma amal was wir so finden. gist.github.com/badlogic/3870d…
(Ignore the warnings :p)
Soda, schau ma amal was wir so finden. gist.github.com/badlogic/3870d…
Zuerst schauen wir uns die social media Arbeitsmoral an.
Trotzem die Agenda Austria (AA) ihre 24/7 Öffnungszeiten haben will, ist sie eher eine 9-5 Bude. Nur wenn der Chef im Fernsehen ist, gibts Überstunden.
Beim Momentum Institut (MI) gibts Gleitzeit und Stechuhr.
Trotzem die Agenda Austria (AA) ihre 24/7 Öffnungszeiten haben will, ist sie eher eine 9-5 Bude. Nur wenn der Chef im Fernsehen ist, gibts Überstunden.
Beim Momentum Institut (MI) gibts Gleitzeit und Stechuhr.
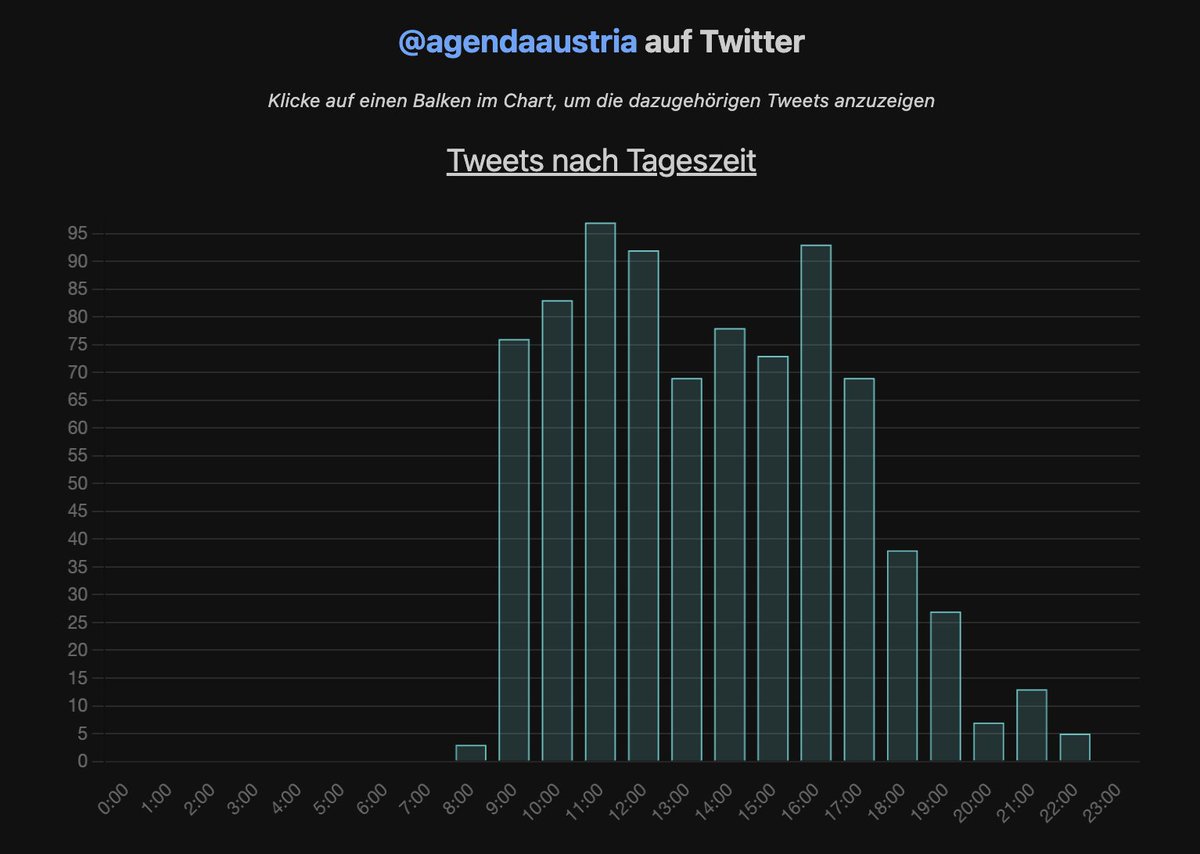
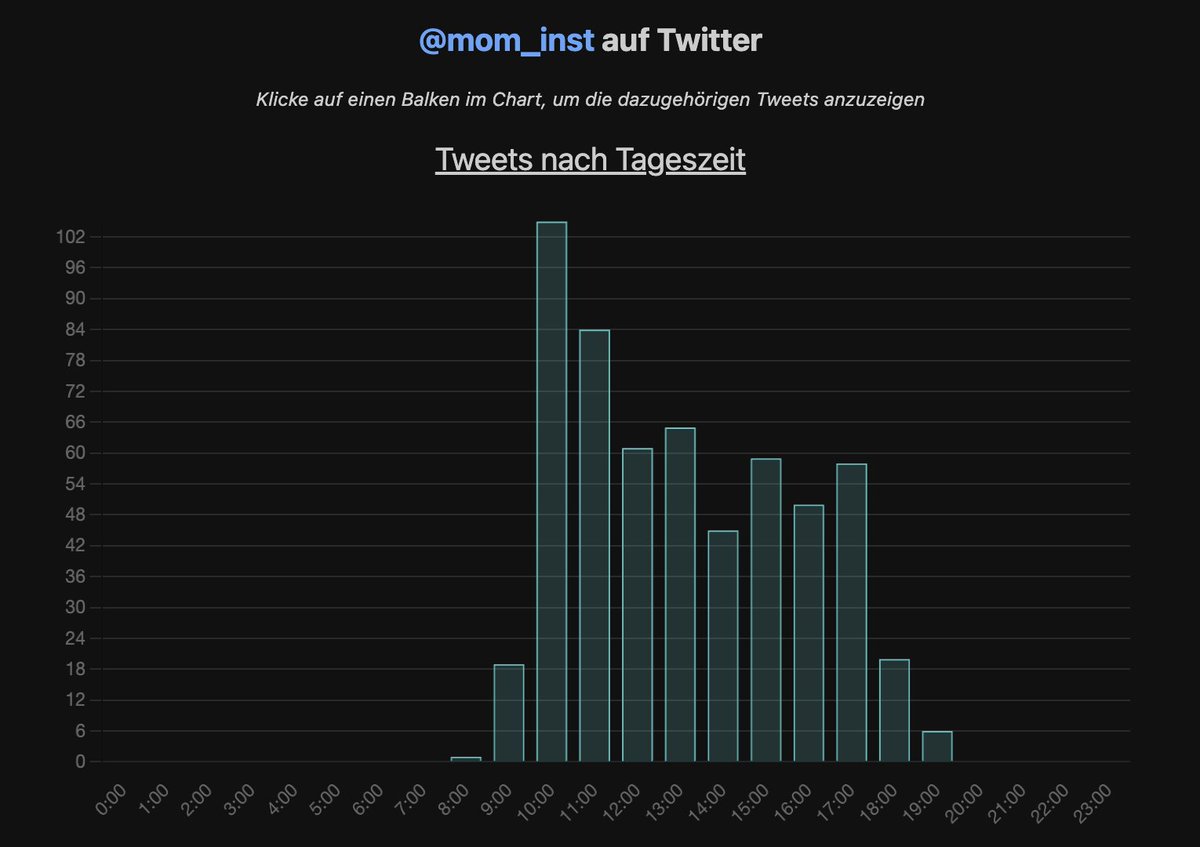
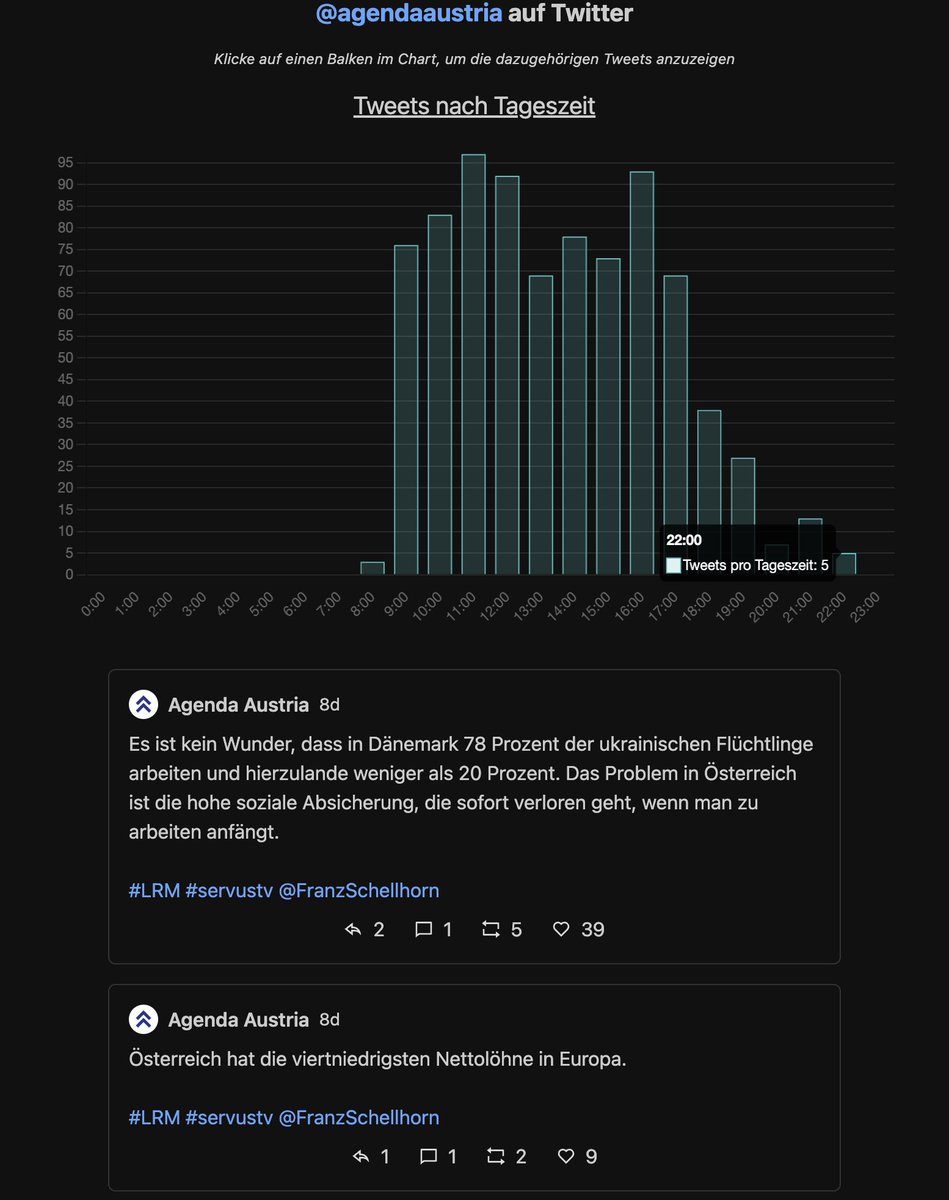
Klickts auf einen Balken, um euch die dazugehörigen Tweets anzeigen zu lassen.
Das bestätigt für AA warum sie auch nach 22:00 noch tweeten: Der Chef im Fernsehen muss besungen werden. Auf Servus TV.
Bei Frau Blaha passiert das nicht. Vll. weil sie weniger eingeladen wird.
Das bestätigt für AA warum sie auch nach 22:00 noch tweeten: Der Chef im Fernsehen muss besungen werden. Auf Servus TV.
Bei Frau Blaha passiert das nicht. Vll. weil sie weniger eingeladen wird.
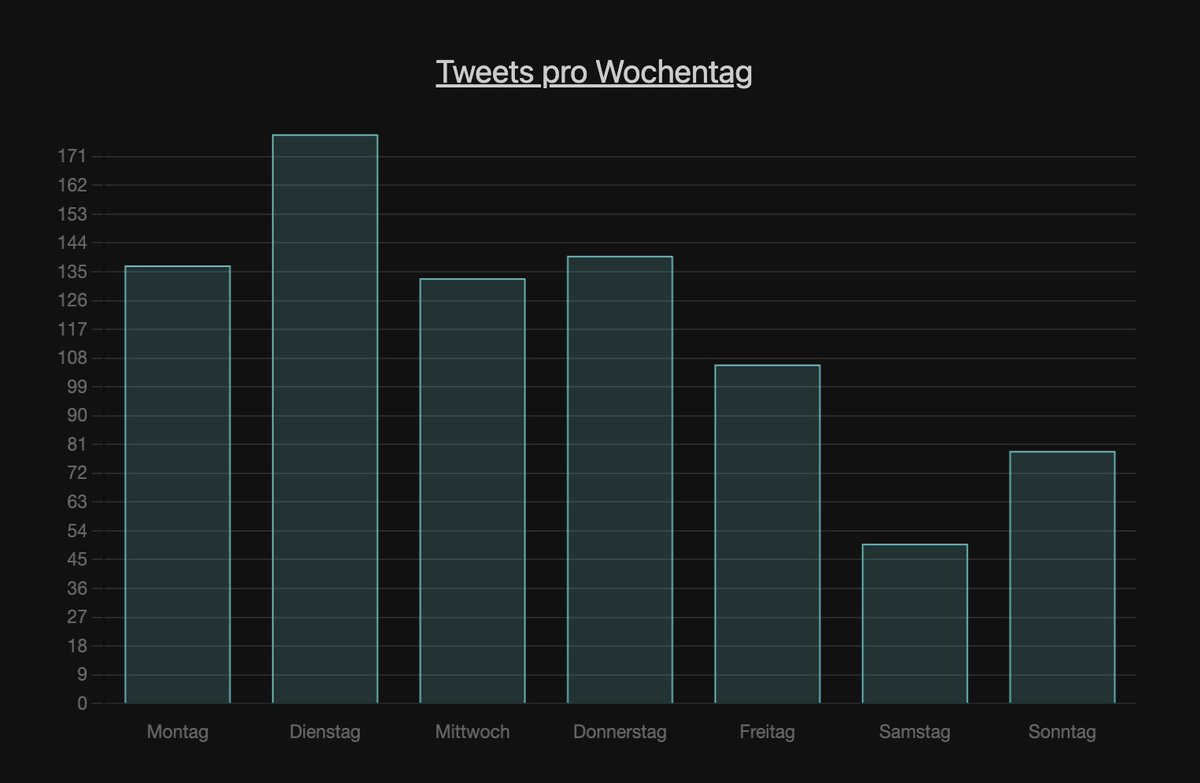
Als nächstes schauen wir uns die Wochentagsarbeitszeit an.
Links AA, rechts MI.
Auch hier doch starke Unterschiede. Bei AA scheint der Samstag der Netflix & Chill Tag zu sein. Entspricht in etwa dem 24/7 Wunsch.
Bei MI ist Wochenende Wochenende!
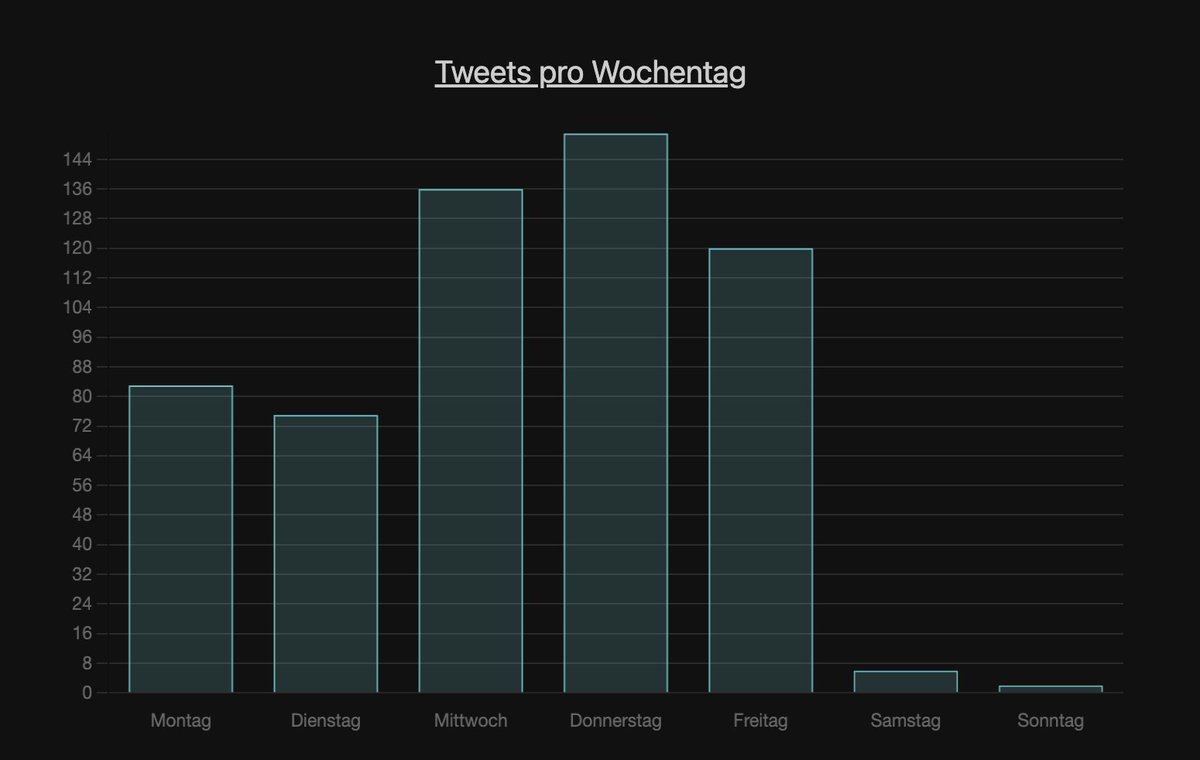
Links AA, rechts MI.
Auch hier doch starke Unterschiede. Bei AA scheint der Samstag der Netflix & Chill Tag zu sein. Entspricht in etwa dem 24/7 Wunsch.
Bei MI ist Wochenende Wochenende!
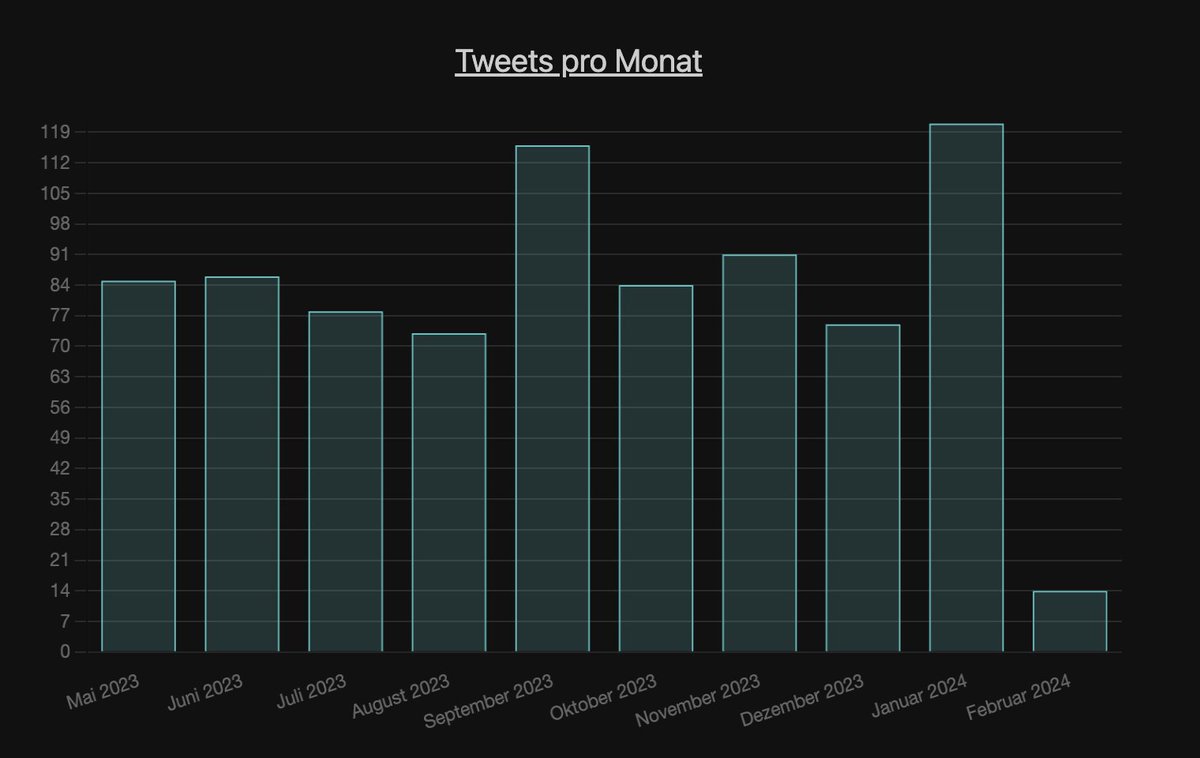
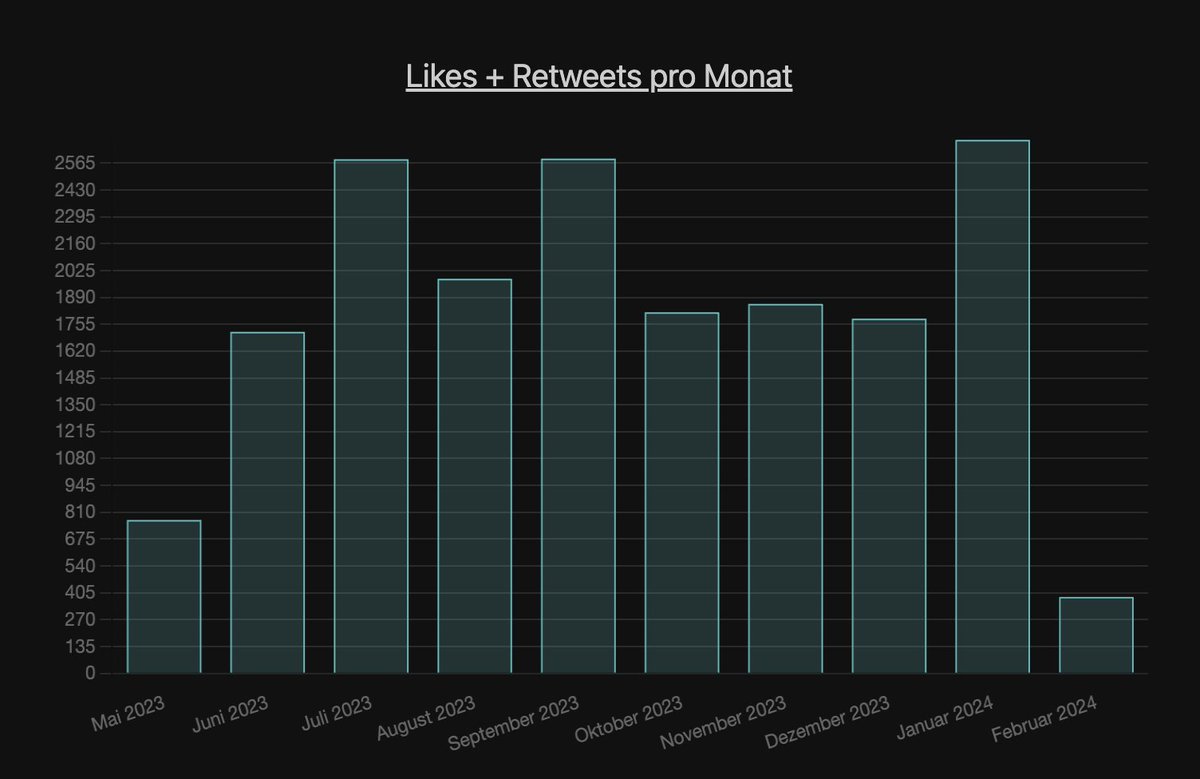
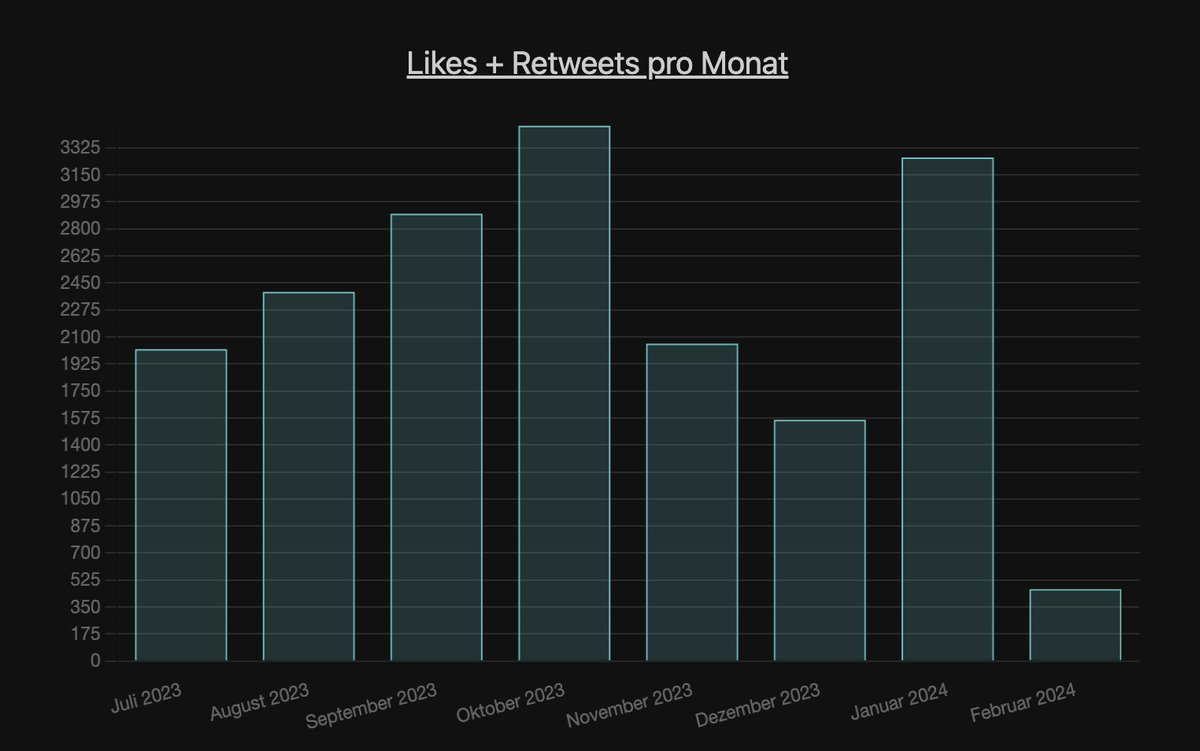
Weiter gehts mit dem monatlichen Tweet Durchsatz. Zu beachten: Mai bei AA, Juli bei MI und Februar bei beiden sind unvollständig.
Sind Urlaubszeiten erkennbar?
Bei AA eher nicht. Gearbeitet wird das ganze Jahr. Zumindest auf Twitter.
Bei MI erkennt man die Urlaubszeit.
Sind Urlaubszeiten erkennbar?
Bei AA eher nicht. Gearbeitet wird das ganze Jahr. Zumindest auf Twitter.
Bei MI erkennt man die Urlaubszeit.
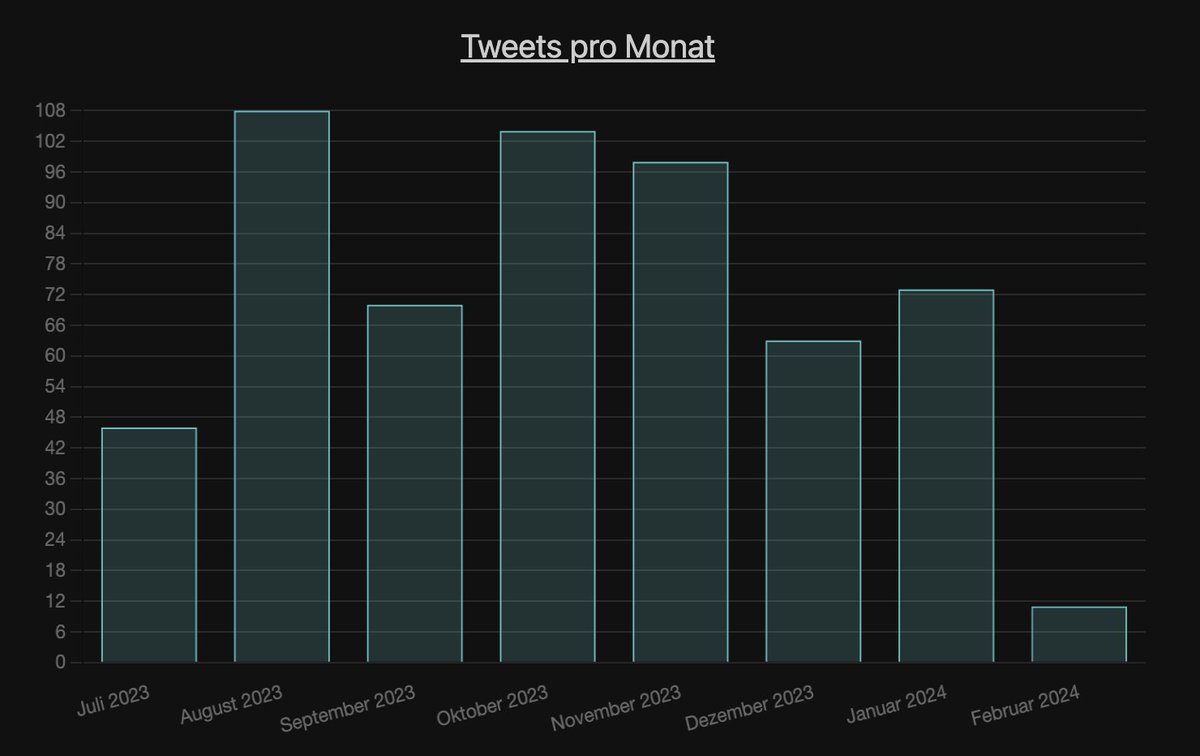
Bei der AA gibts also den neoliberalen Hustle, beim MI wird hingegen ganz ArbeitnehmerInnen-freundlich auf die Zeit schaut.
Schlägt sich das im Twitter Game, aka Likes+Retweets, nieder?
Nope, im Schnitt ziemlich gleich. Wobei MI um einiges weniger postet!
Schlägt sich das im Twitter Game, aka Likes+Retweets, nieder?
Nope, im Schnitt ziemlich gleich. Wobei MI um einiges weniger postet!
Wie schauen wir thematisch aus? Dafür gibts eine schiache, net besonders gute Word Cloud.
Völlig überraschend reden beide vor allem über Österreich. Bei AA ist Herr Schellhorn auch sehr wichtig. Frau Blaha steht im aber um nicht viel nach.
Ansonsten erwartbar.
Völlig überraschend reden beide vor allem über Österreich. Bei AA ist Herr Schellhorn auch sehr wichtig. Frau Blaha steht im aber um nicht viel nach.
Ansonsten erwartbar.


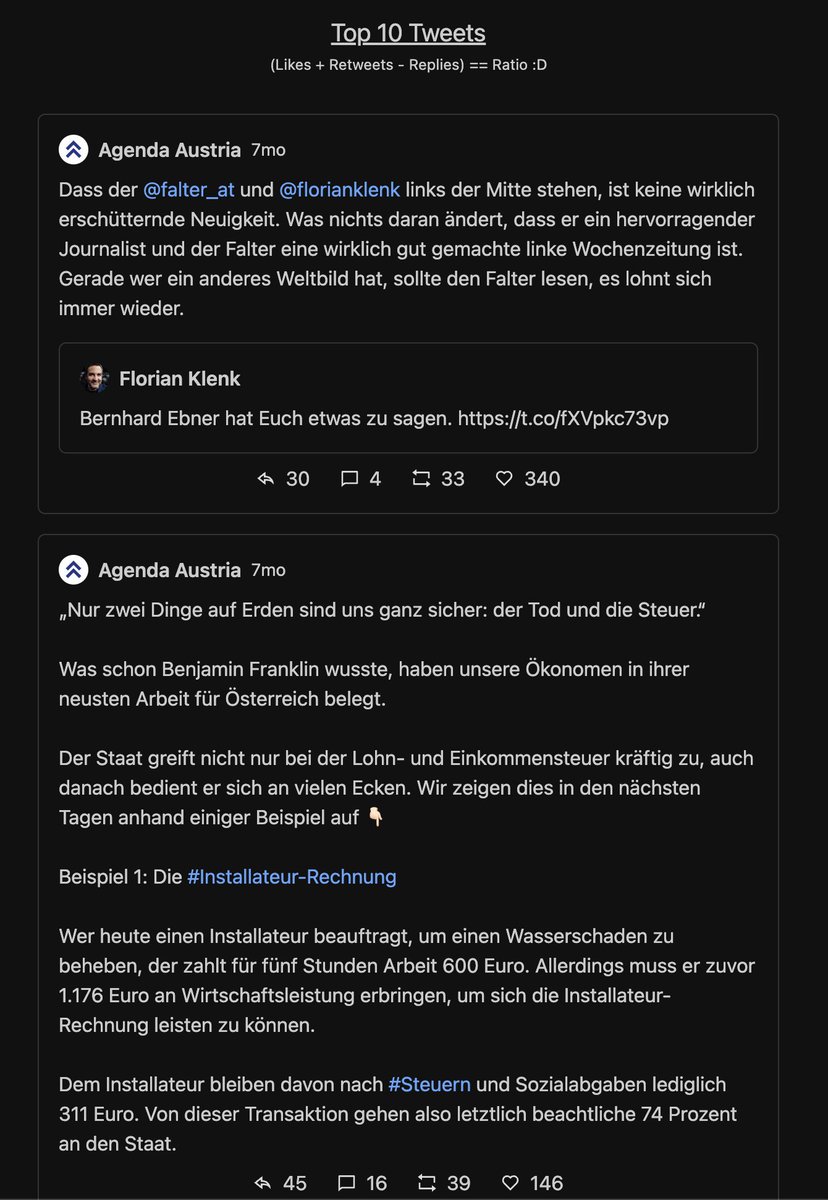
Next, die top Tweets. Jeder Tweet kriegt eine Wertung = Likes+Retweets-Replies = Ratio.
Bei der AA gwinnt ein Lobgesang auf @florianklenk. Mit Abstand.
Natürlich muss drauf hingewiesen werden, dass Klenk "links" ist. Die Welt ist schwarz/weiss knowyourmeme.com/memes/the-rati…
Bei der AA gwinnt ein Lobgesang auf @florianklenk. Mit Abstand.
Natürlich muss drauf hingewiesen werden, dass Klenk "links" ist. Die Welt ist schwarz/weiss knowyourmeme.com/memes/the-rati…
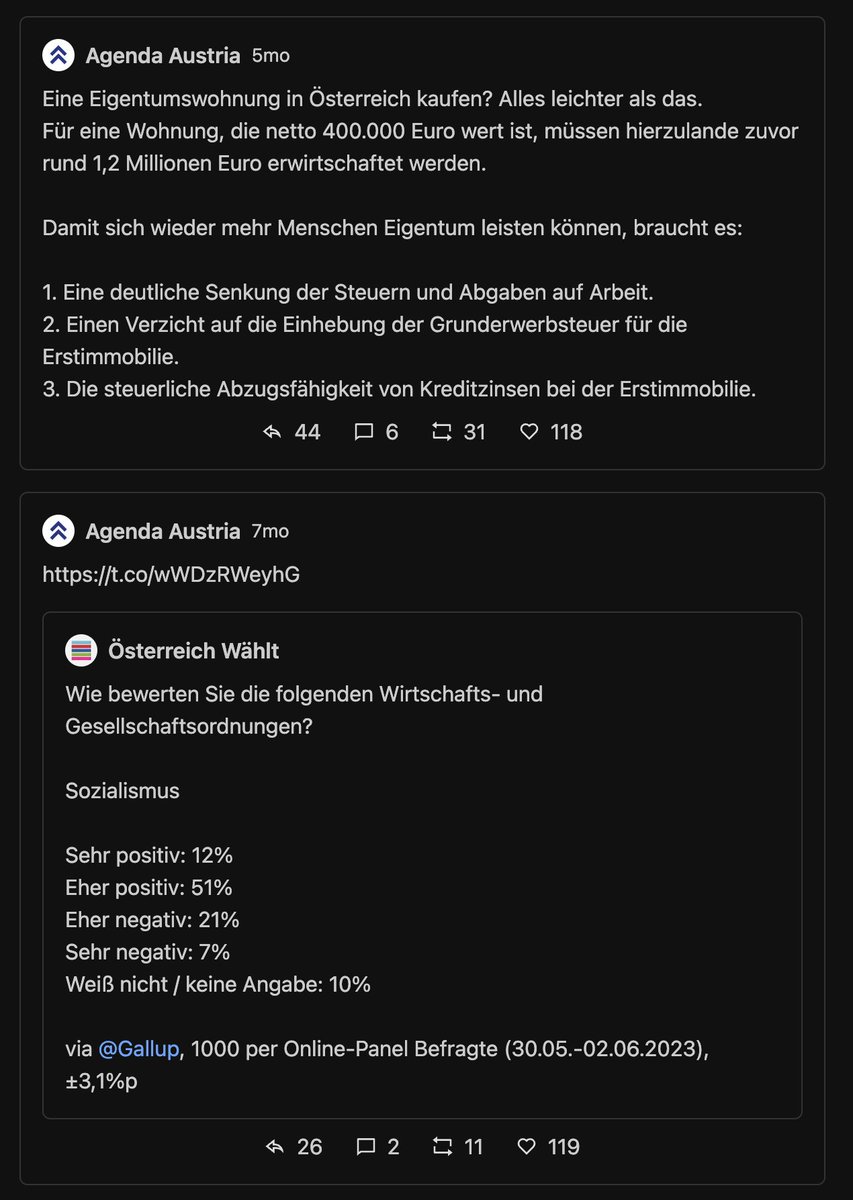
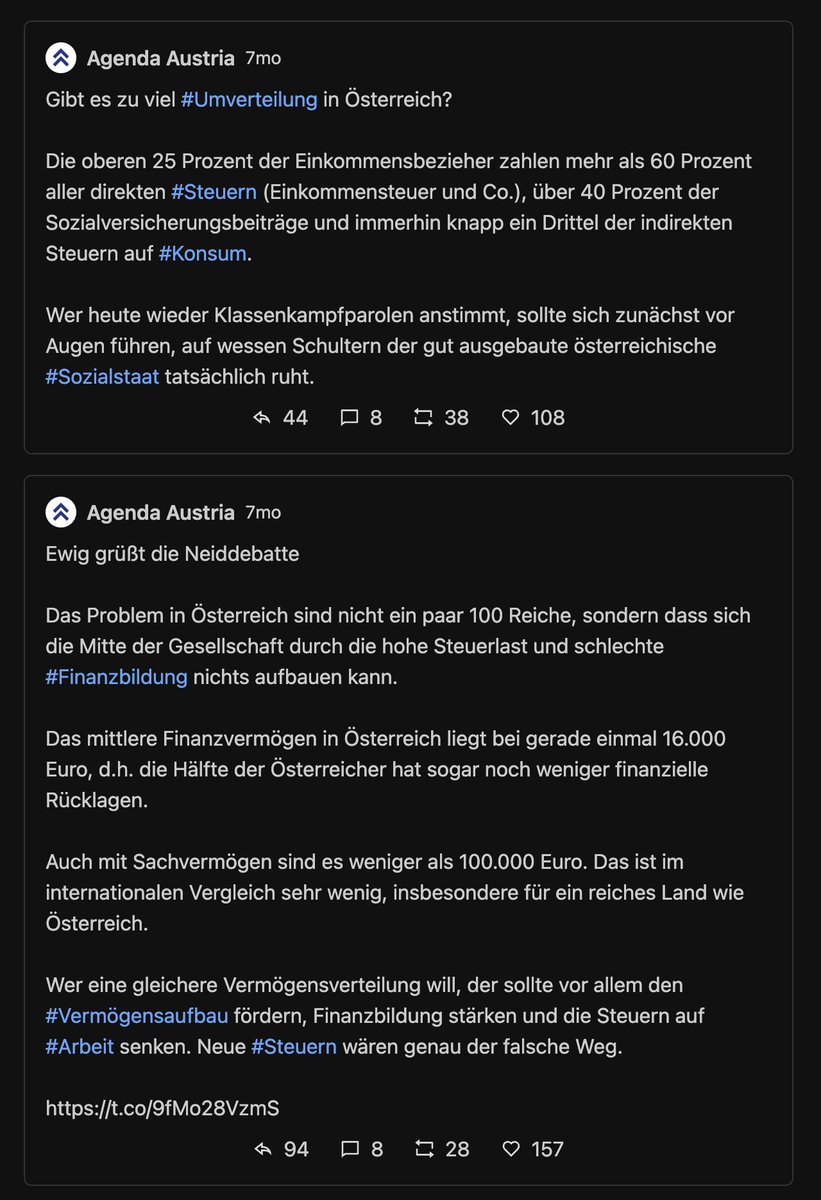
@florianklenk Die top Tweets bei MI sind dem ggü. eher langweilig. Allgemeiner Links-Twitter Applaus für die altbekannten Themen. No surprise.
Der top Tweet von MI fällt Likes+Retweets mäßig um einiges "satter" aus als der von AA.
Der top Tweet von MI fällt Likes+Retweets mäßig um einiges "satter" aus als der von AA.
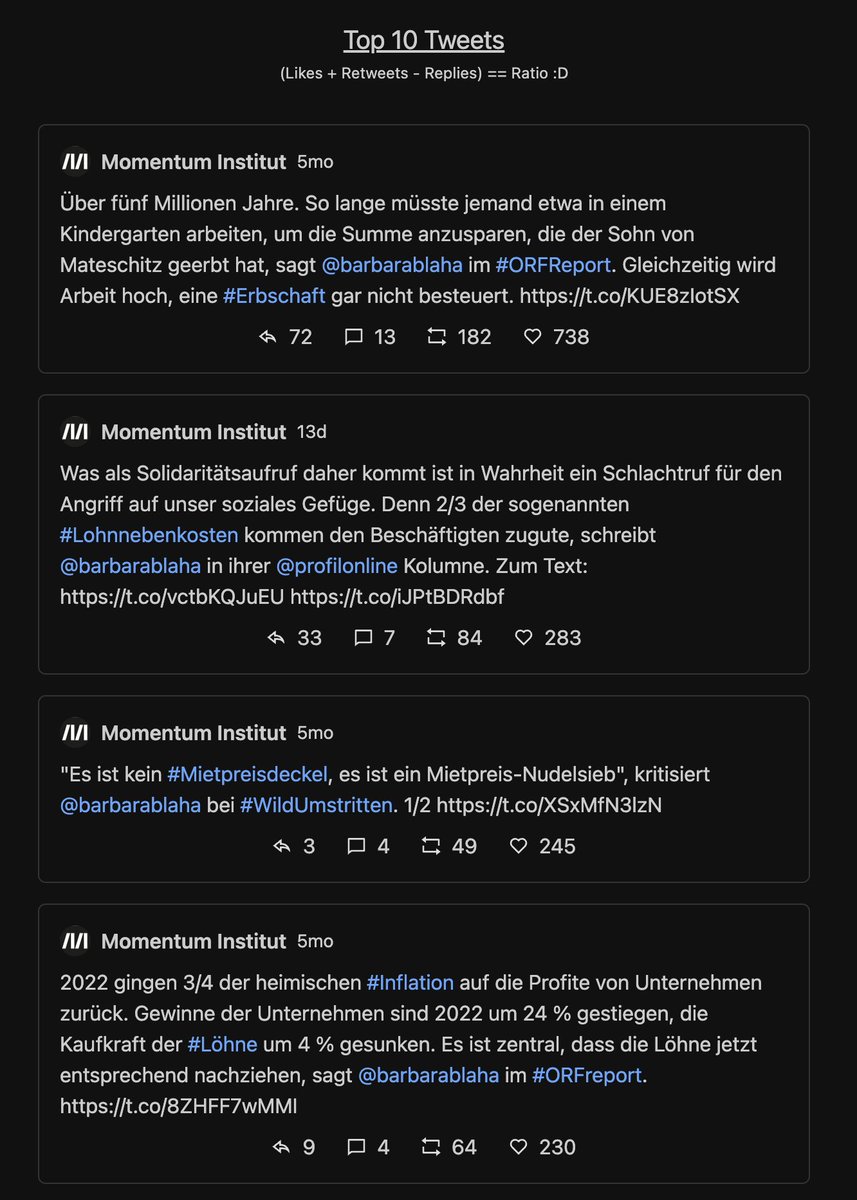
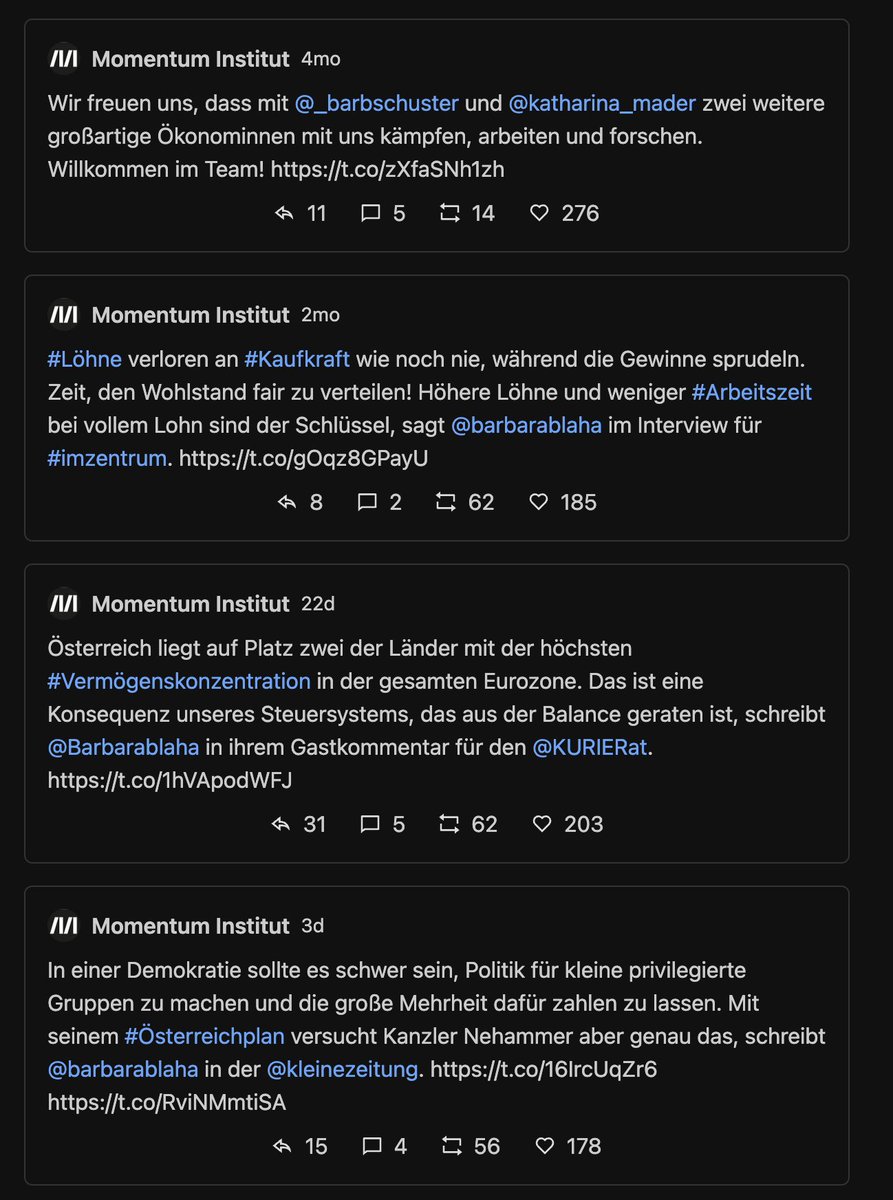
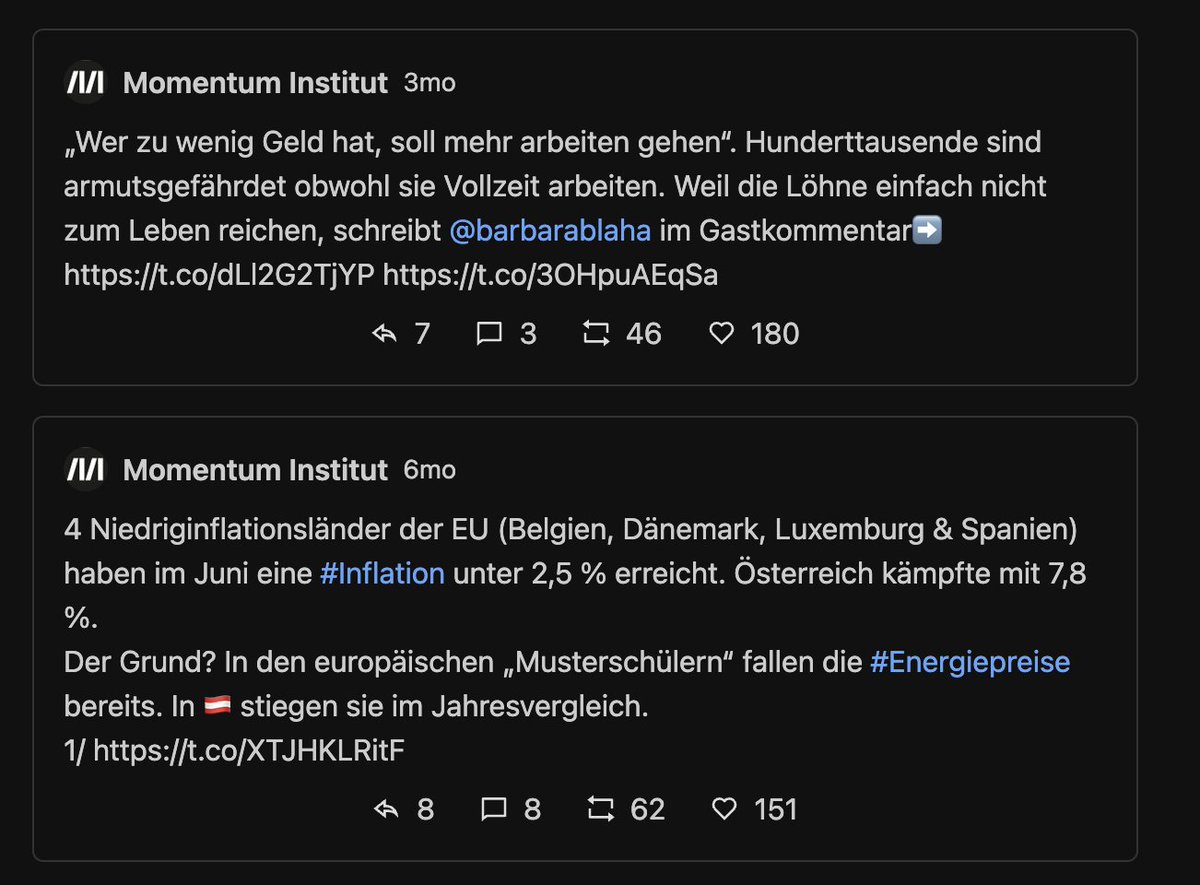
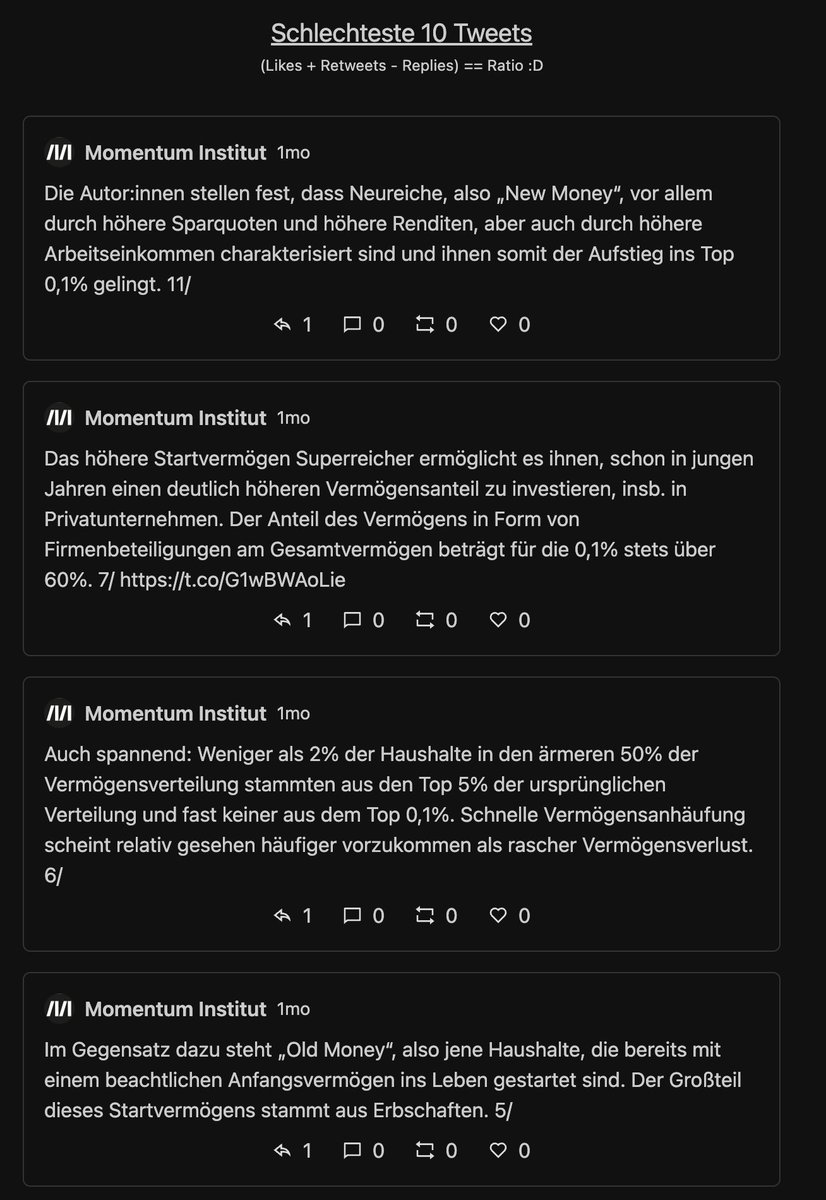
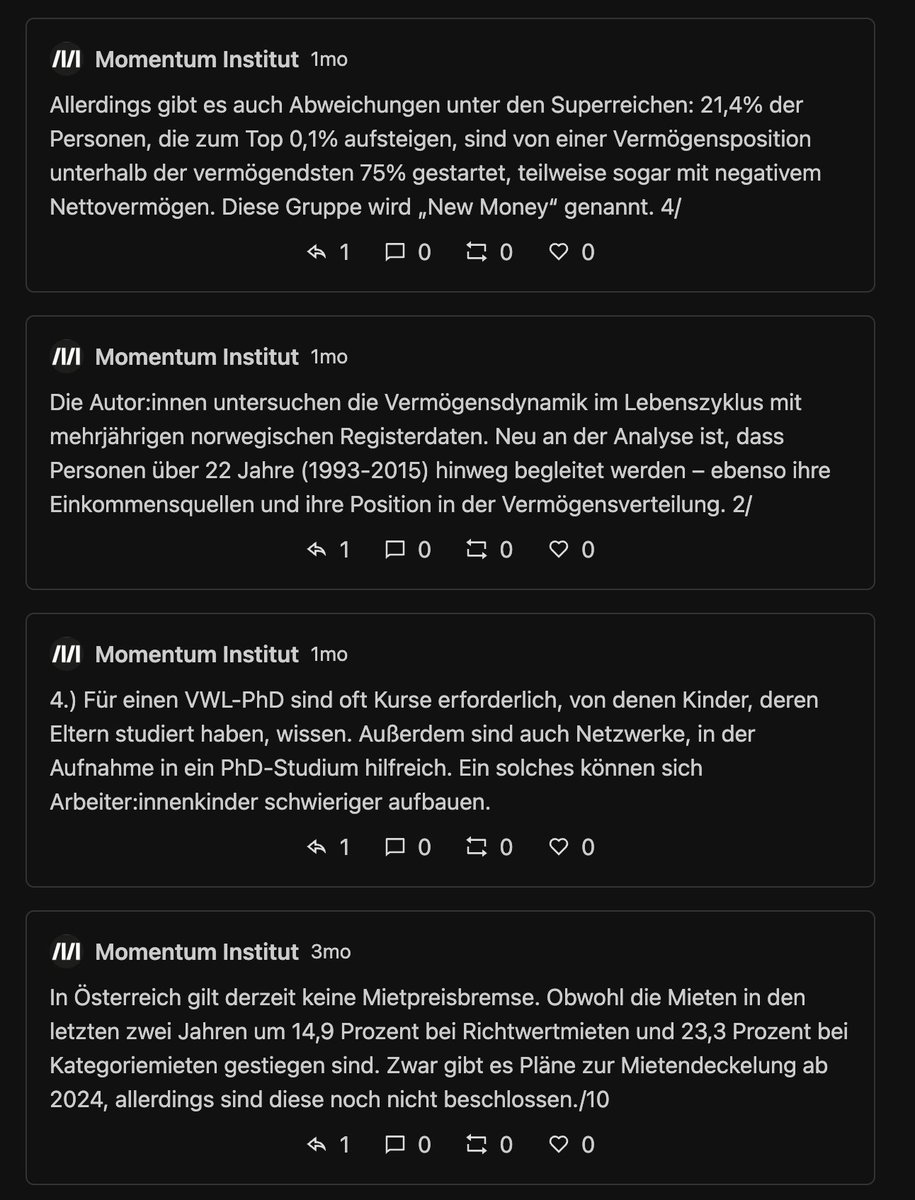
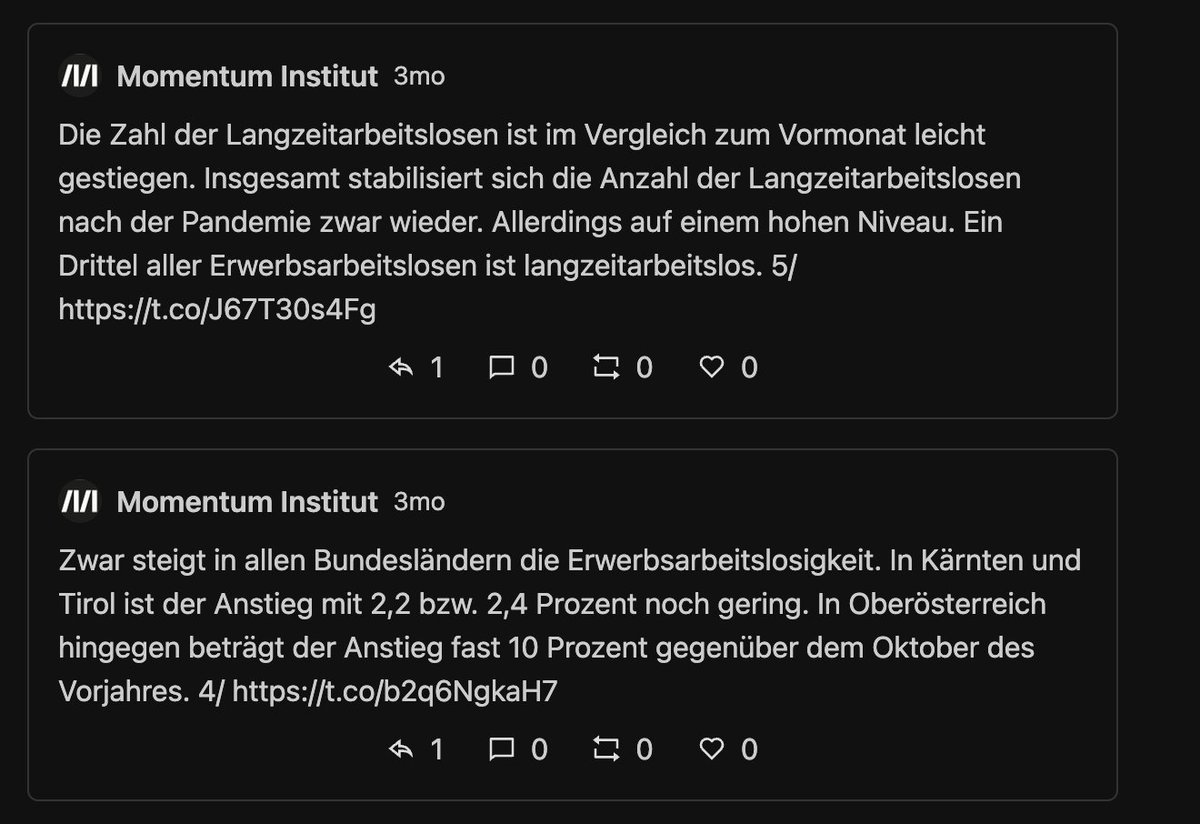
Next: die 10 "schlechtesten" Tweets. Also jene, wo es mehr (ws. negative) Antworten als Likes+Retweets gibt. Vergleiche:
Schwer bei dem Publikum hier. Die Fördergeber sind halt nicht auf Twitter.
knowyourmeme.com/memes/the-rati…
agenda-austria.at/ueberuns/foerd…
Schwer bei dem Publikum hier. Die Fördergeber sind halt nicht auf Twitter.
knowyourmeme.com/memes/the-rati…
agenda-austria.at/ueberuns/foerd…
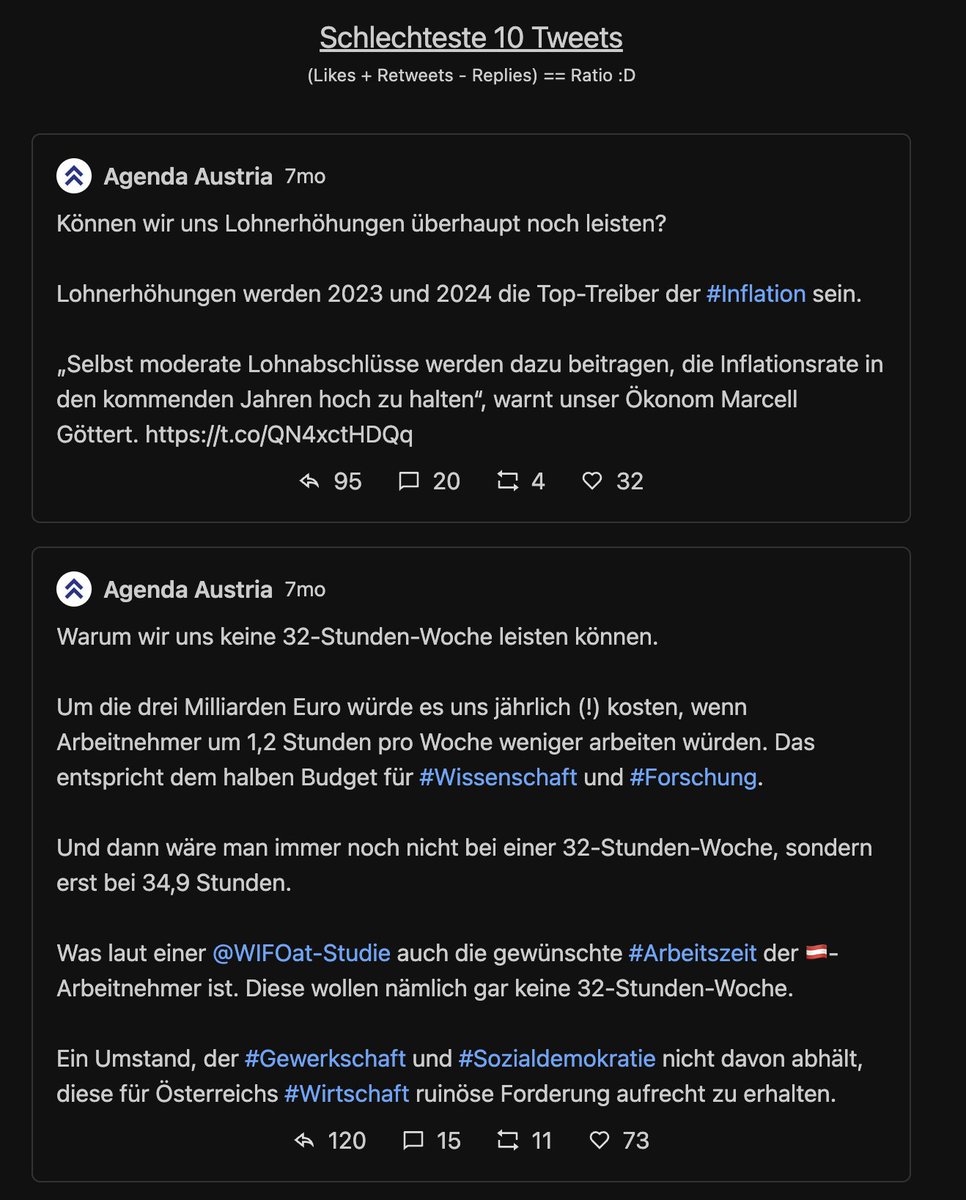
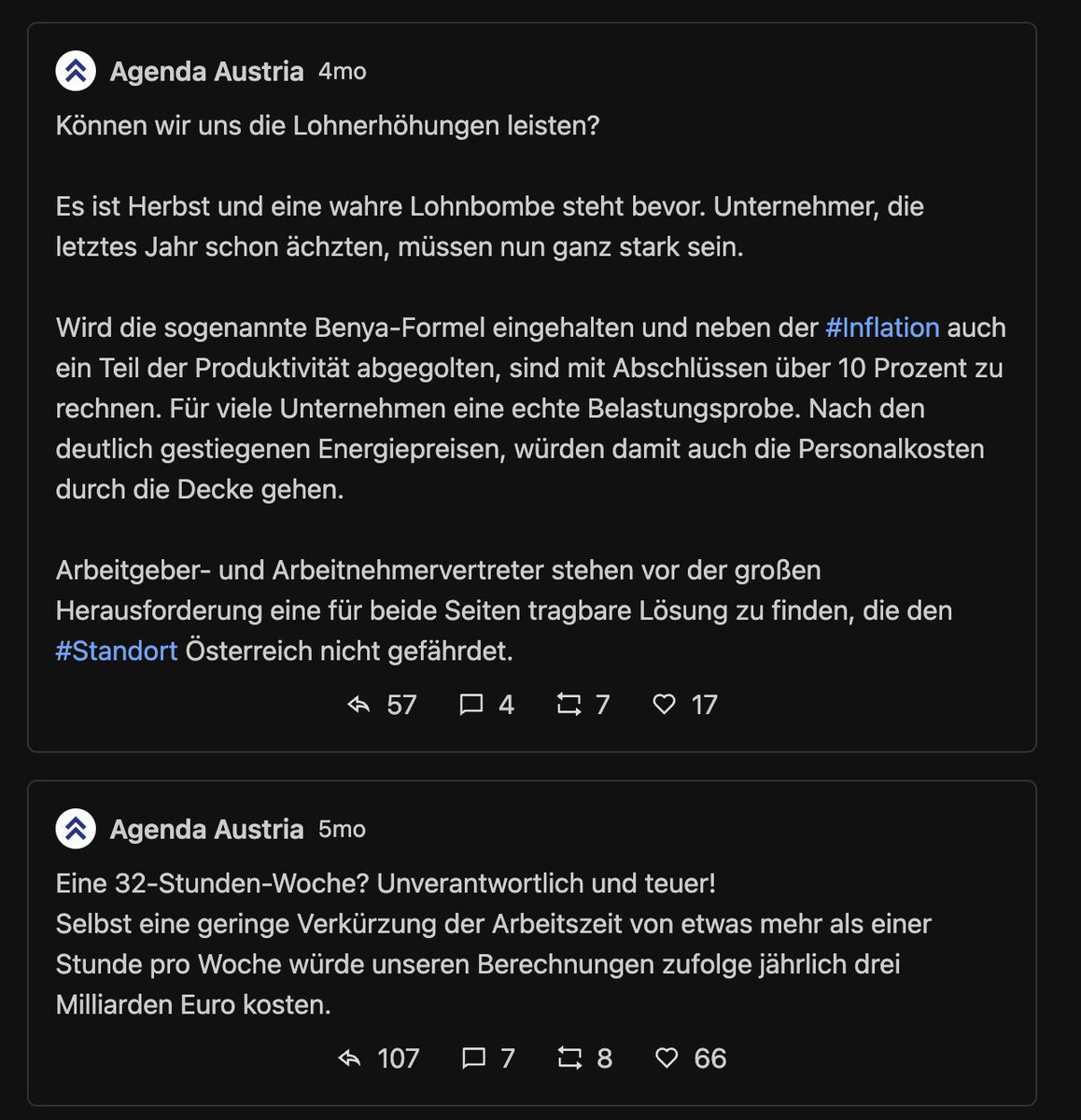
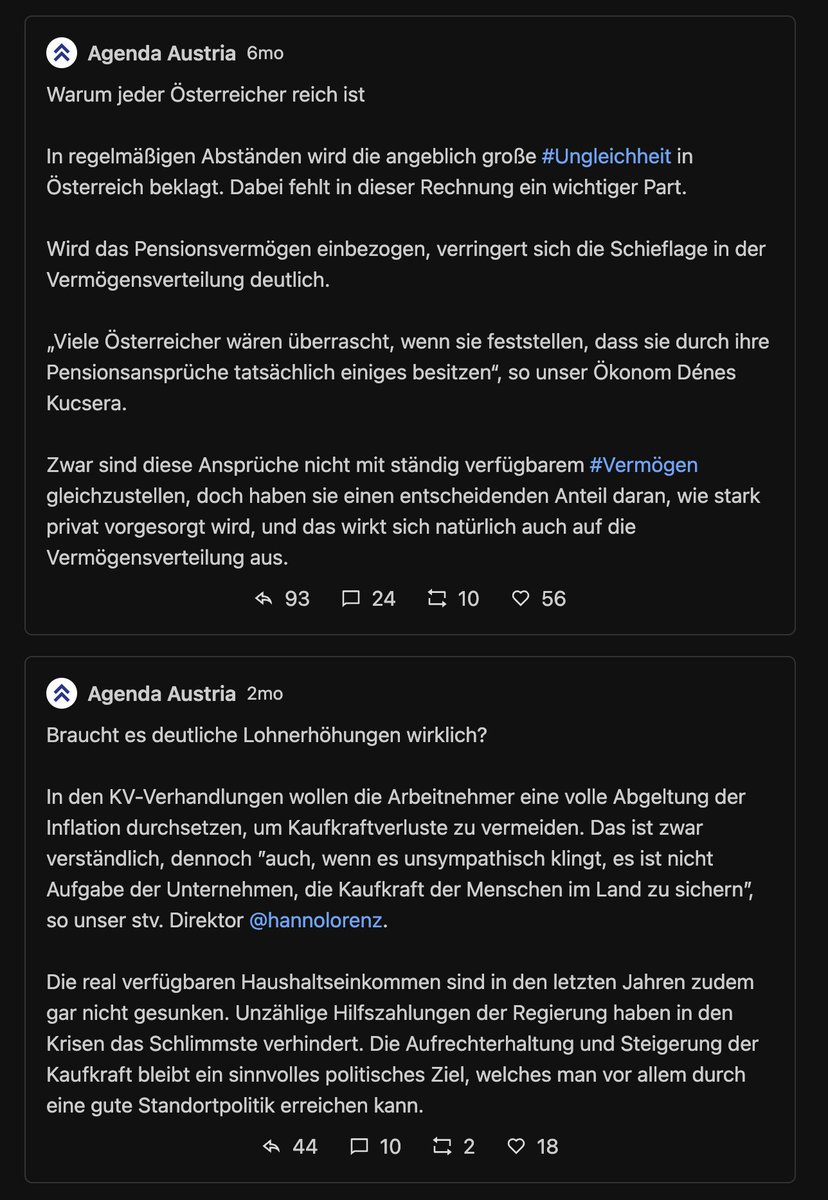
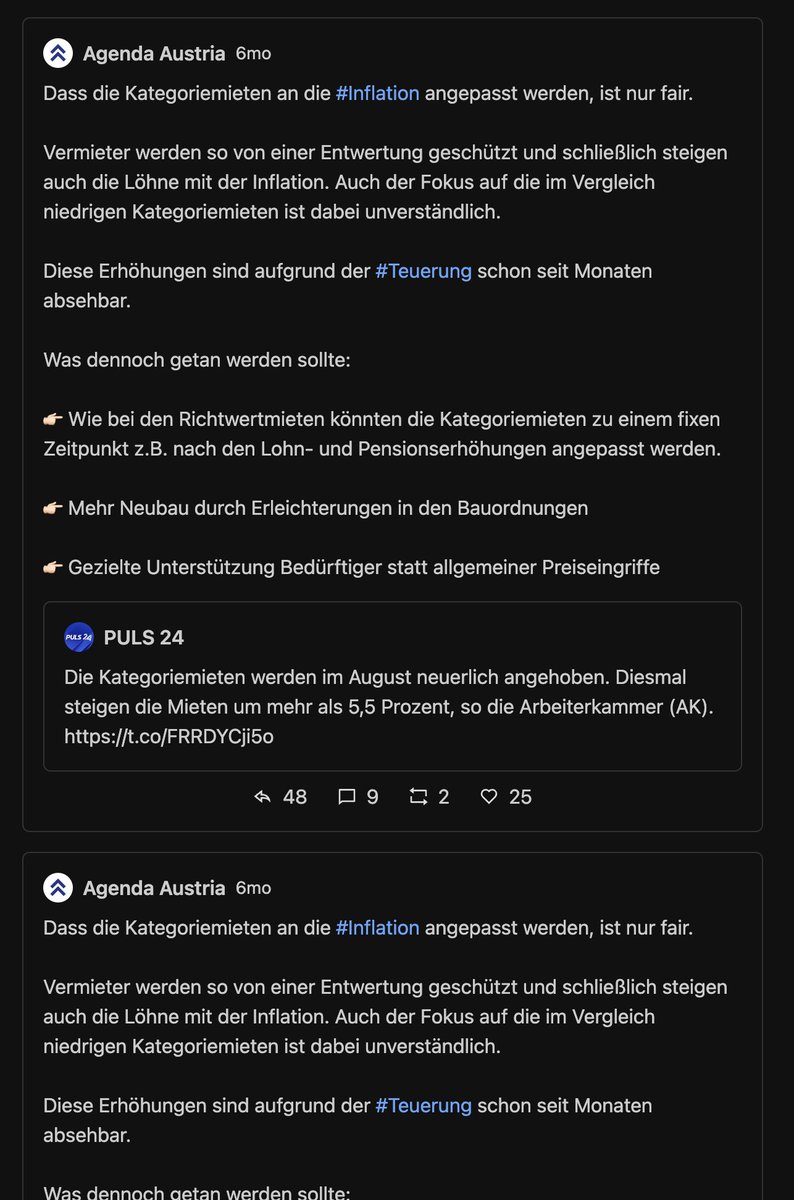
Beim MI gibts ... keinen Widerspruch vom Publikum? Hier schlagen Tweets ohne Interaktion auf. Das Twitter so linksversifft gleichgeschalten ist, hätte ich nicht erwartet.
Vll. erbarment sich ein paar Twitter Trolle, damit auch das MI die volle Twitter Experience erleben kann?
Vll. erbarment sich ein paar Twitter Trolle, damit auch das MI die volle Twitter Experience erleben kann?
Speaking of Trolls. Wenn erwähnen die beiden Organisationen in ihren Tweets?
Erwähnungen der AA. Auf "Tweets anzeigen" klicken, um die konkreten Tweets zu sehen.
Eigene Mitarbeiter werden erwartbar am öftesten erwähnt. Gefolgt von Babler, AK, MI (MitarbeiterInnen), SPÖ, ÖGB
:D
Erwähnungen der AA. Auf "Tweets anzeigen" klicken, um die konkreten Tweets zu sehen.
Eigene Mitarbeiter werden erwartbar am öftesten erwähnt. Gefolgt von Babler, AK, MI (MitarbeiterInnen), SPÖ, ÖGB
:D
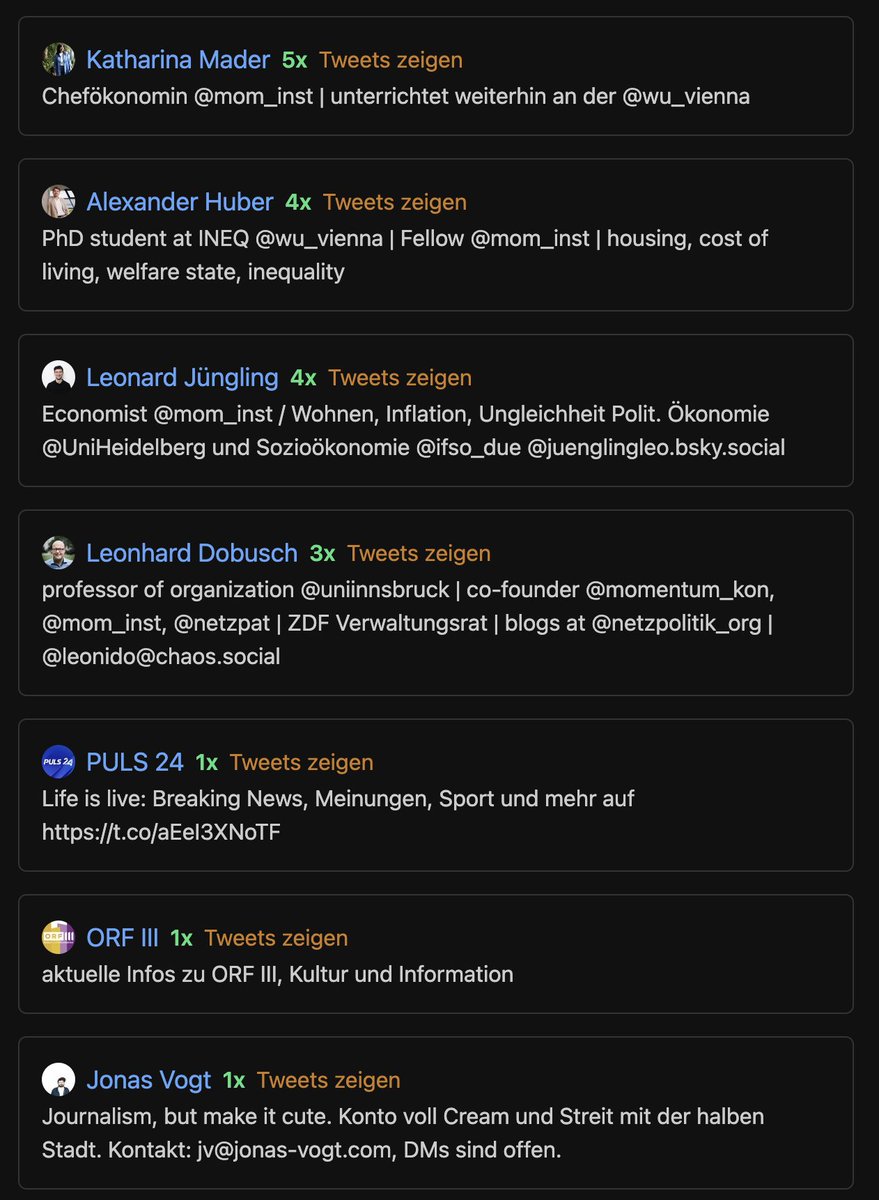
Beim MI ist das alles um einiges handzahmer und weniger angriffig.
Auch hier werden die eigenen MitarbeiterInnen am öftesten erwähnt.
Aber Konfrontationen mit anderen Personen und Orgas scheint man zu meiden. AA und Schellhorn werden nur jeweils 1x erwähnt.
Auch hier werden die eigenen MitarbeiterInnen am öftesten erwähnt.
Aber Konfrontationen mit anderen Personen und Orgas scheint man zu meiden. AA und Schellhorn werden nur jeweils 1x erwähnt.
Als nächstes schauen wir uns die Zitate/"Drükos" an. Das gibt uns Auskunft darüber, ob gebeefed wird.
Bei der AA schaut das so aus. Man zitiert sich am liebsten selbst. Dann beefed man per Drüko mit MI, AK, ÖGB, MitarbeiterInnen dieser Organisationen, SPÖ, GPA, und Fussi (lol)
Bei der AA schaut das so aus. Man zitiert sich am liebsten selbst. Dann beefed man per Drüko mit MI, AK, ÖGB, MitarbeiterInnen dieser Organisationen, SPÖ, GPA, und Fussi (lol)
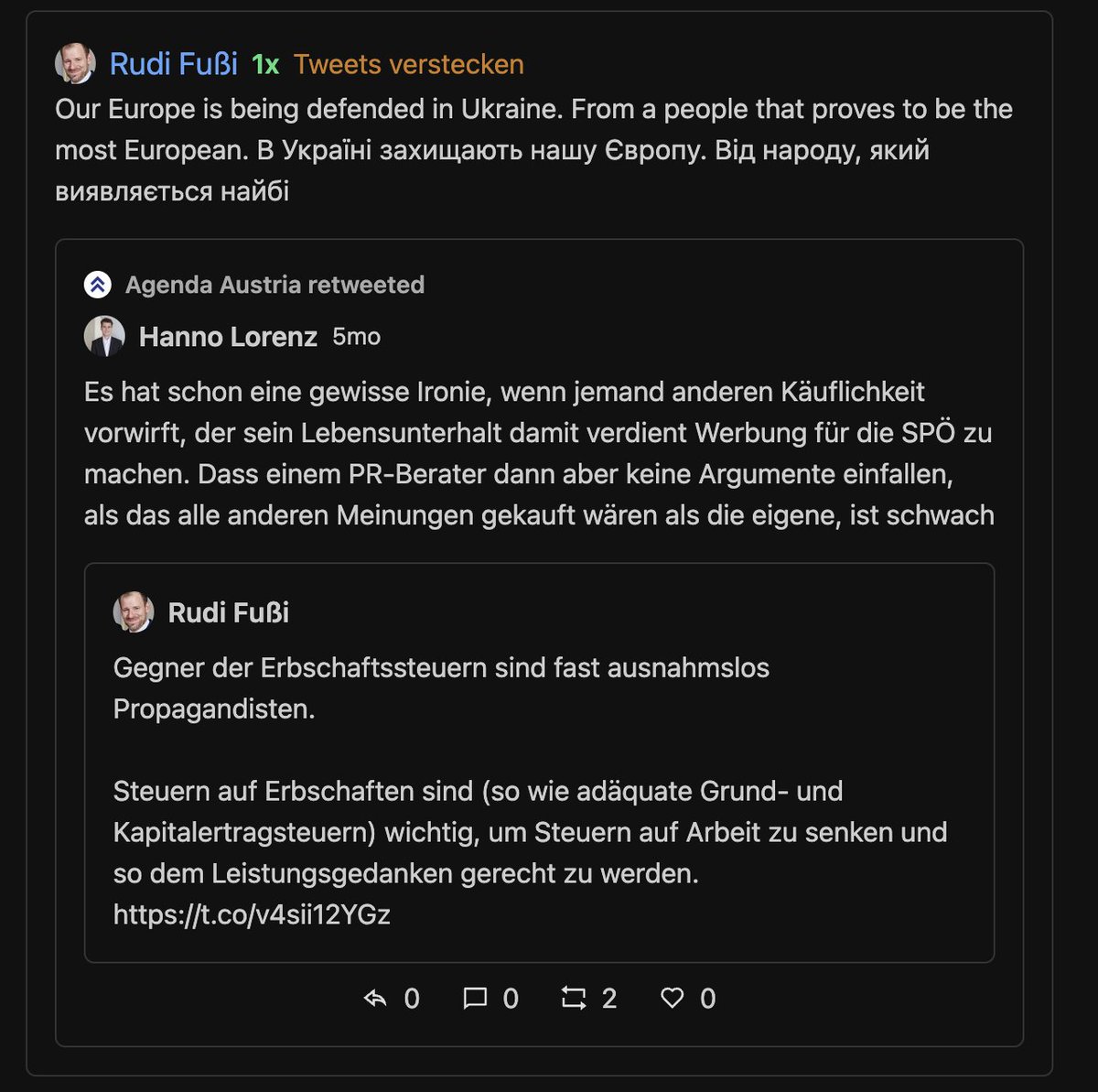
Das MI macht so gut wie keine Zitate/Drückos. Das hat man wohl in der "How-to-social-media-professionally" Schule gelernt. Mit AA und ihren Mitarbeitern beefed man 2x per Retweet von Tweets eigener Mitarbeiter.
Quasi die Königsdisziplin des Beefings. AA ist hier klare Siegerin.
Quasi die Königsdisziplin des Beefings. AA ist hier klare Siegerin.
Dann habe wir noch Retweets.
Bei der AA retweeted man sich selbst bzw. seine Mitarbeiter erwarungsgemäß am häufigsten.
Aber auch der Pragmaticus, eXXpress, und verschiedene Servus TV Outlets werden retweetet.
Weil man dort schreibt oder auftritt.
Bei der AA retweeted man sich selbst bzw. seine Mitarbeiter erwarungsgemäß am häufigsten.
Aber auch der Pragmaticus, eXXpress, und verschiedene Servus TV Outlets werden retweetet.
Weil man dort schreibt oder auftritt.
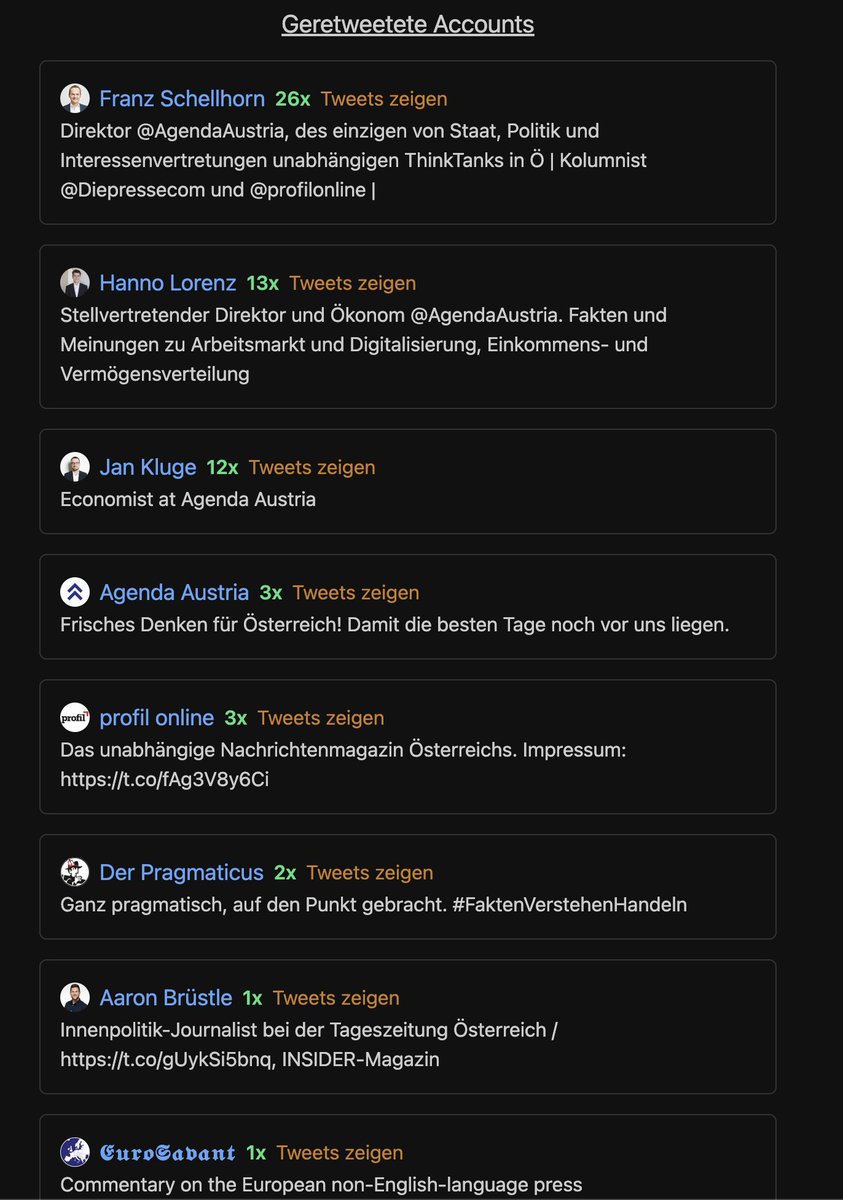
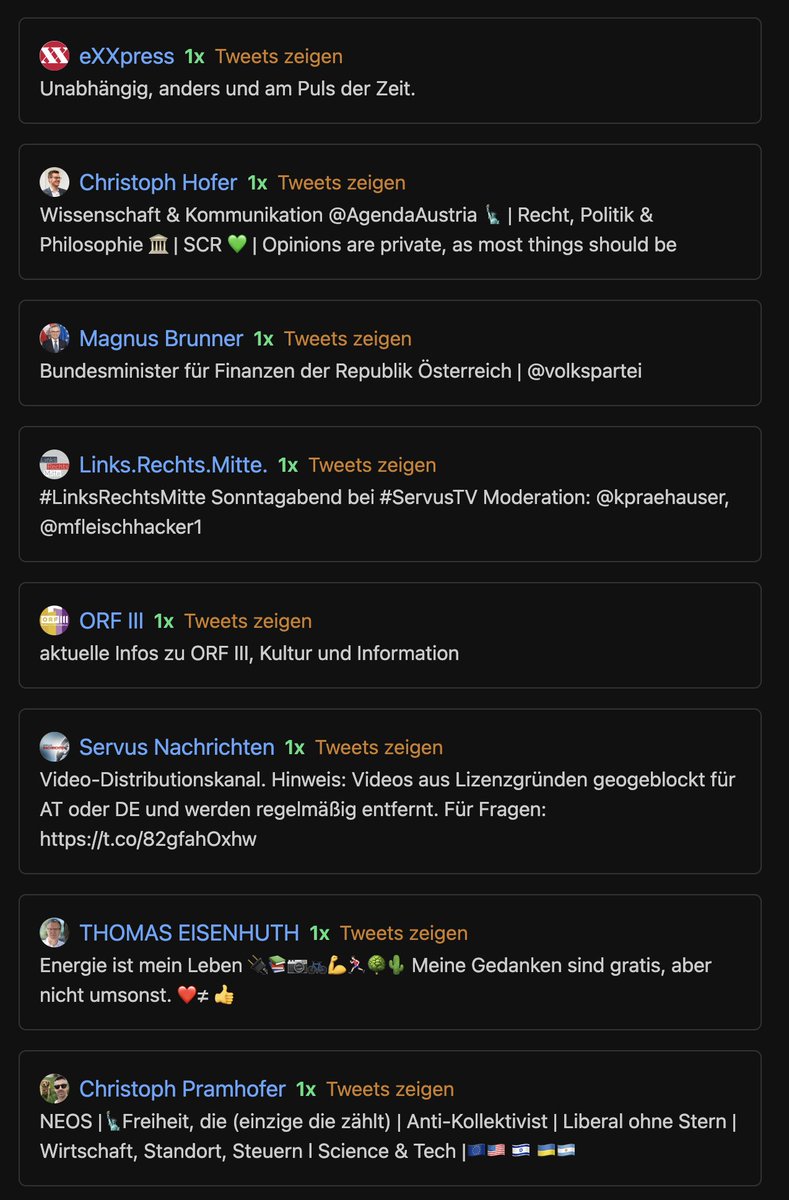
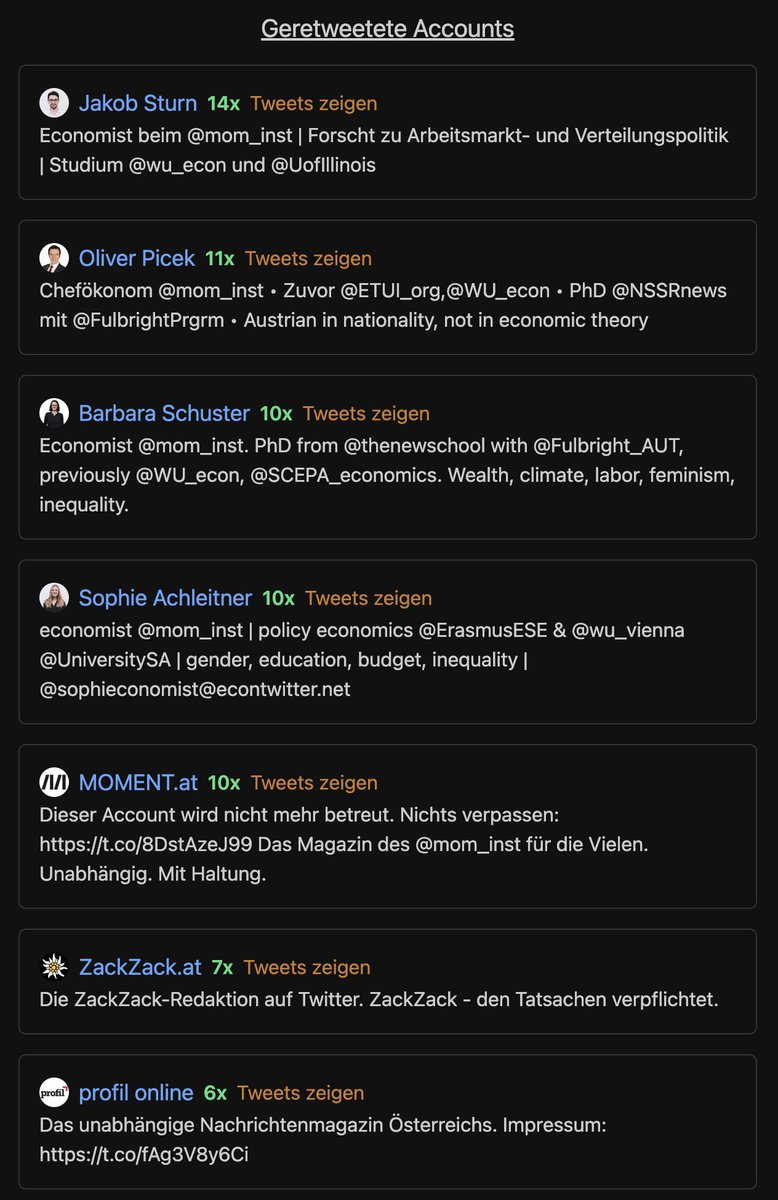
Die Retweets des MI sind dem ggü. wieder zurückhaltender.
Wiederum retweeted man sich selbst bzw. seine MitarbeiterInnen am häufigsten. ZackZack ist hier der einzige Ausreisser.
Wiederum retweeted man sich selbst bzw. seine MitarbeiterInnen am häufigsten. ZackZack ist hier der einzige Ausreisser.
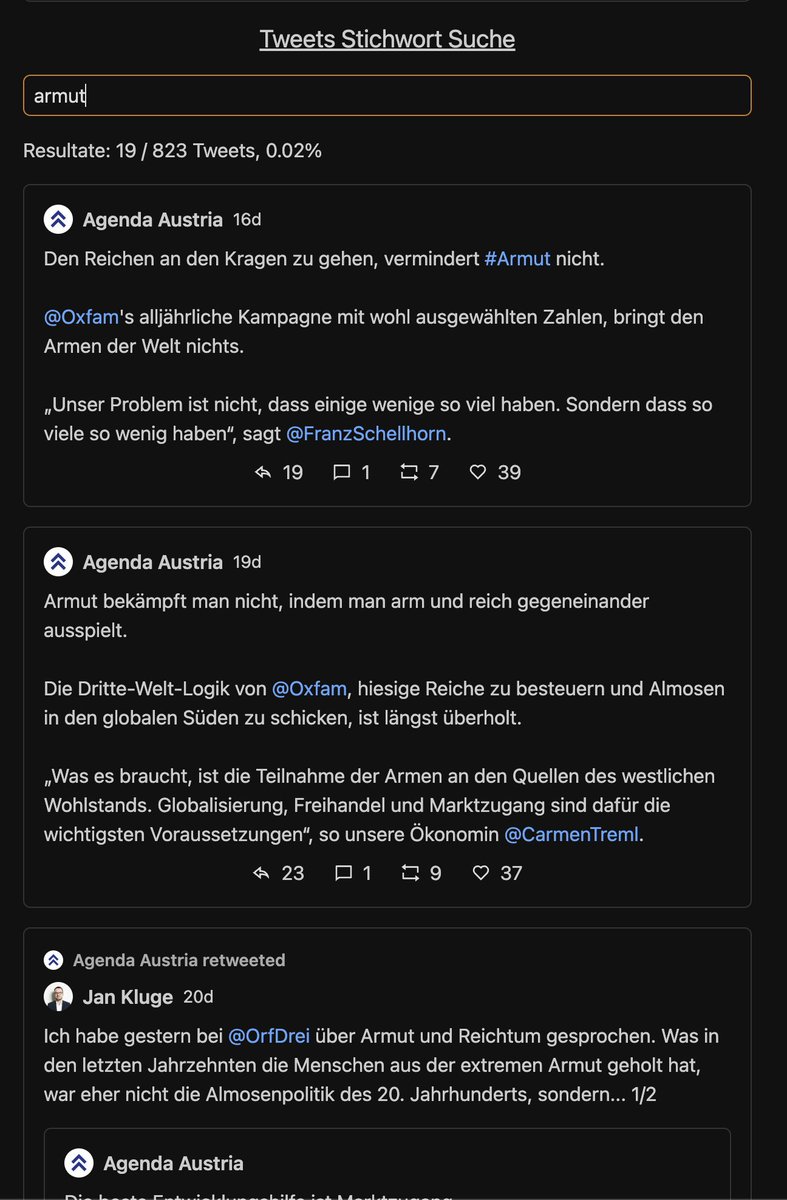
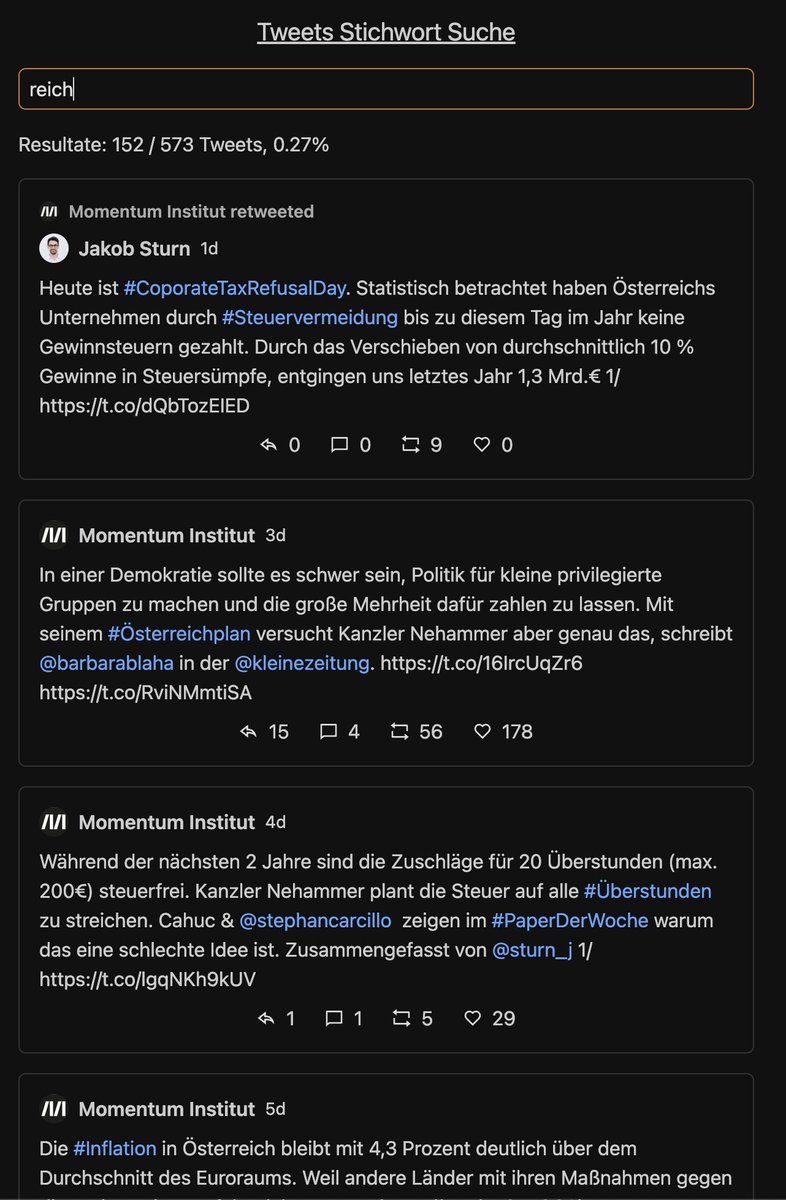
Und zu guter letzt gibts noch ein interaktives Tool für euch. Mit dem könnt ihr per Stichwörtern die Tweets der beiden Organisationen durchsuchen.
Enjoy.
Enjoy.
Was haben wir gelernt?
- AA ist eine 9-5 Hustlebude, MI ein Stechuhr Verein. Beide haben ähnliche Engagementzahlen
- AA beefed mit allem was links ist, MI versucht sich professionell zurück zu halten
- Beide lieben sich selbst am meisten
- AA ist eine 9-5 Hustlebude, MI ein Stechuhr Verein. Beide haben ähnliche Engagementzahlen
- AA beefed mit allem was links ist, MI versucht sich professionell zurück zu halten
- Beide lieben sich selbst am meisten
• • •
Missing some Tweet in this thread? You can try to
force a refresh