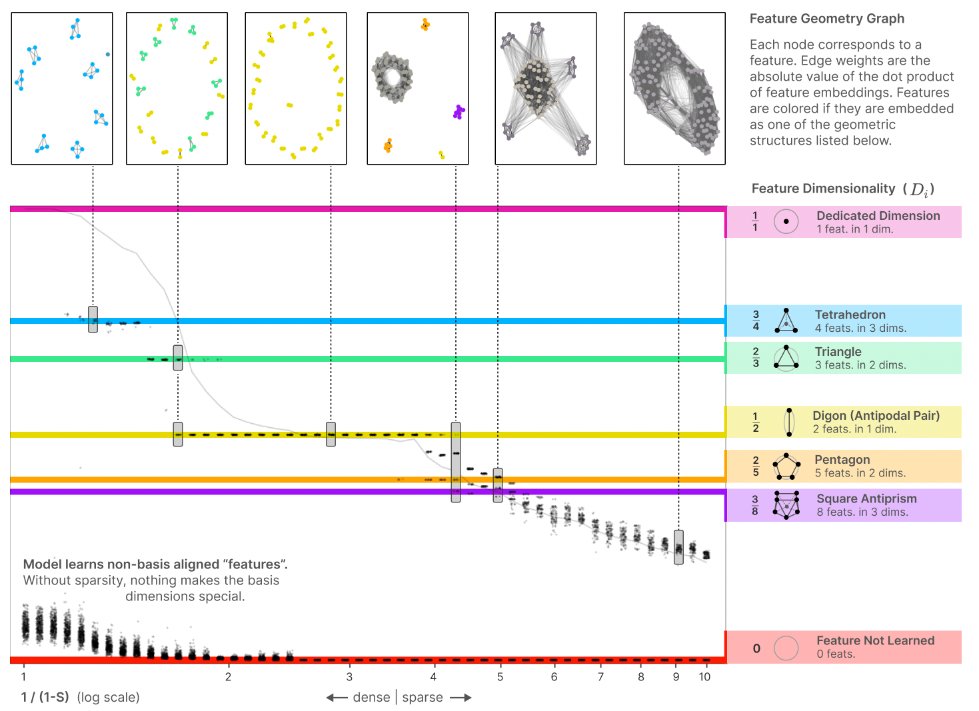
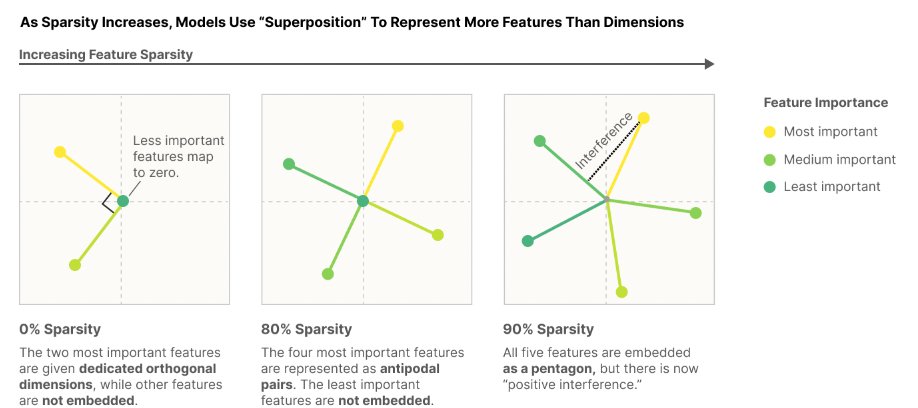
Claude 3 Opus is great at following multiple complex instructions.
To test it, @ErikSchluntz and I had it take on @karpathy's challenge to transform his 2h13m tokenizer video into a blog post, in ONE prompt, and it just... did it
Here are some details:
To test it, @ErikSchluntz and I had it take on @karpathy's challenge to transform his 2h13m tokenizer video into a blog post, in ONE prompt, and it just... did it
Here are some details:
First, we grabbed the raw transcript of the video and screenshots taken at 5s intervals.
Then, we chunked the transcript into 24 parts for efficient processing (the whole transcript fits within the context window, so this is merely a speed optimization).
Then, we chunked the transcript into 24 parts for efficient processing (the whole transcript fits within the context window, so this is merely a speed optimization).
We gave Opus the transcript, video screenshots, as well as two *additional* screenshots:
- One of Andrej's blog to display a visual style to follow
- The top of the notebook @karpathy shared with a writing style example On top, we added lots of instructions (prompt in repo)

- One of Andrej's blog to display a visual style to follow
- The top of the notebook @karpathy shared with a writing style example On top, we added lots of instructions (prompt in repo)


Here is a subset of some of what we asked the model, in one prompt (full prompt attached)
- directly write HTML
- filter out irrelevant screenshots
- transcribe the code examples in images if they contain a complete example
- synthesize transcript and image contents into prose
- directly write HTML
- filter out irrelevant screenshots
- transcribe the code examples in images if they contain a complete example
- synthesize transcript and image contents into prose

@ErikSchluntz and I have read the resulting transcript, and Opus manages to incorporate all of these requests, and produces a great blog post.
The blog post is formatted as asked, with a subset of images selected and captioned
The blog post is formatted as asked, with a subset of images selected and captioned
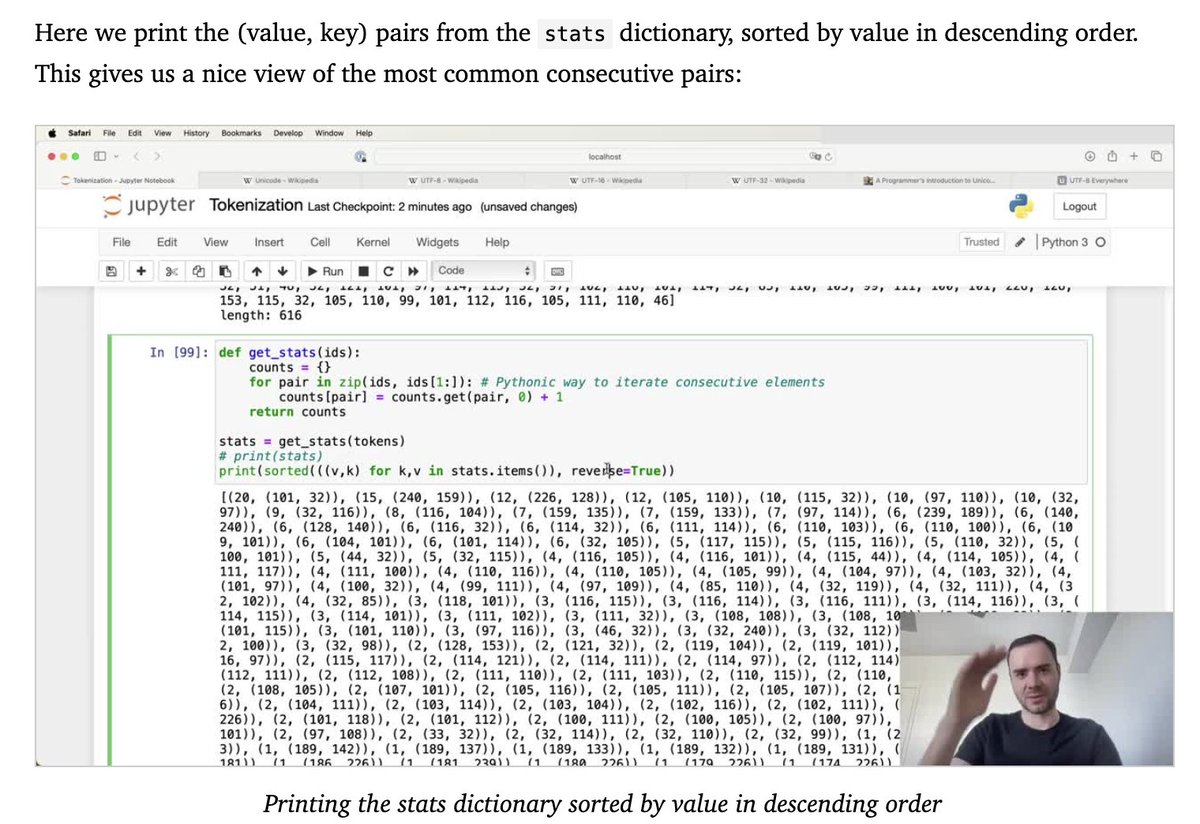
It writes code examples, and relates the content of the transcript to the screenshots to provide a coherent narrative.
Overall, the tutorial is readable, clear and much better than anything I've previously gotten out of an LLM.
Overall, the tutorial is readable, clear and much better than anything I've previously gotten out of an LLM.
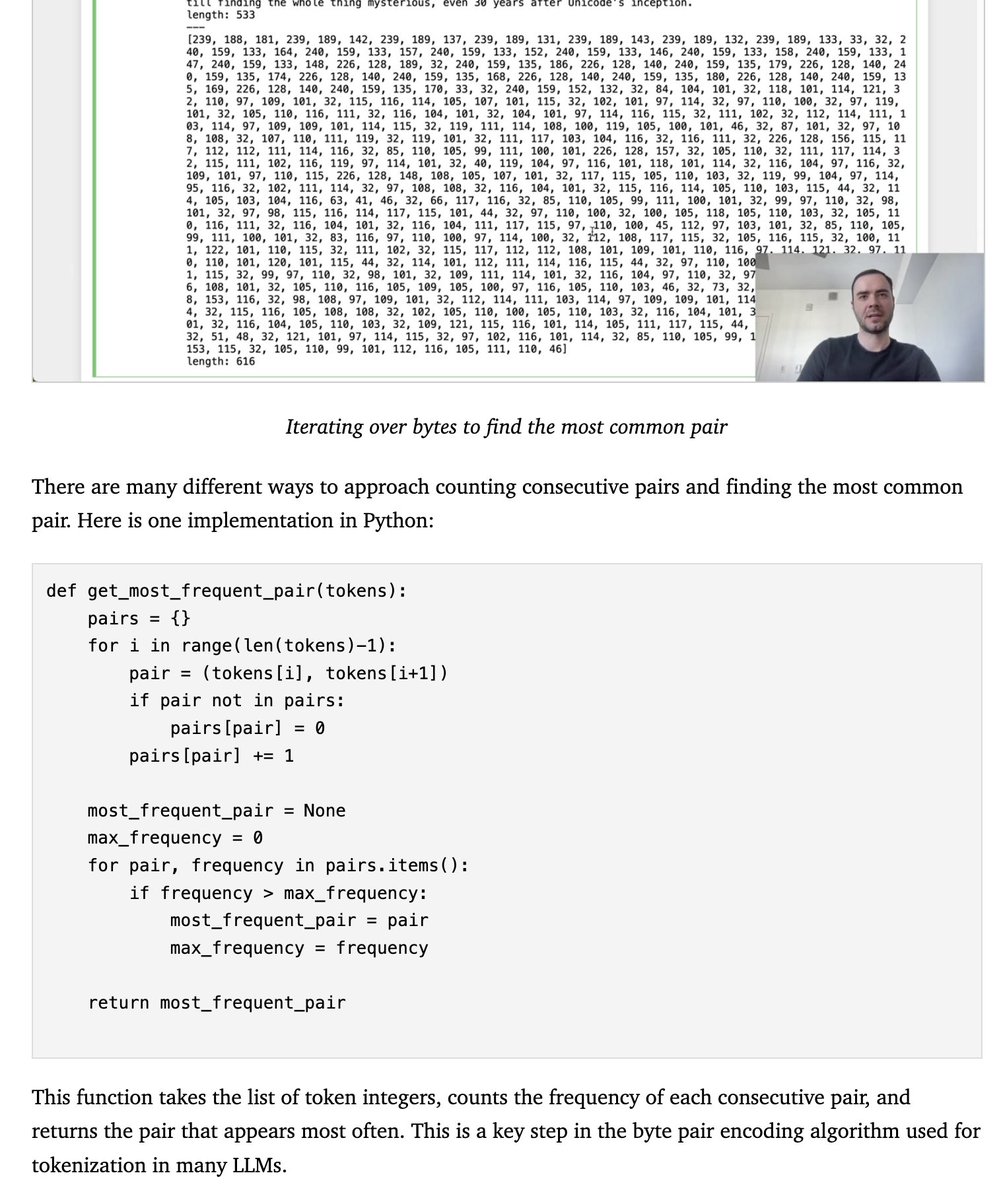
Of course, the model isn't perfect yet!
When looking through the transcript, @ErikSchluntz found some issues and inconsistencies.
Some minor code bugs slipped through, and some of the sections are repetitive (this is partially due to parallel processing).
When looking through the transcript, @ErikSchluntz found some issues and inconsistencies.
Some minor code bugs slipped through, and some of the sections are repetitive (this is partially due to parallel processing).
This was done in one prompt that @zswitten @ErikSchluntz and I wrote.
If you'd like to try to improve it, here is the prompt
And the full blog post github.com/hundredblocks/…
hundredblocks.github.io/transcription_…
If you'd like to try to improve it, here is the prompt
And the full blog post github.com/hundredblocks/…
hundredblocks.github.io/transcription_…
• • •
Missing some Tweet in this thread? You can try to
force a refresh