If developers had to prove to regulators that powerful AI systems are safe to deploy, what are the best arguments they could use?
Our new report tackles the (very big!) question of how to make a ‘safety case’ for AI.
Our new report tackles the (very big!) question of how to make a ‘safety case’ for AI.

We define a safety case as a rationale developers provide to regulators to show that their AI systems are unlikely to cause a catastrophe.
The term ‘safety case’ is not new. In many industries (e.g. aviation), products are ‘put on trial’ before they are released.
The term ‘safety case’ is not new. In many industries (e.g. aviation), products are ‘put on trial’ before they are released.

We simplify the process of making a safety case by breaking it into six steps.
1. Specify the macrosystem (all AI systems) and the deployment setting.
2. Concretize 'AI systems cause a catastrophe' into specific unacceptable outcomes (e.g. the AI systems build a bioweapon)
...
1. Specify the macrosystem (all AI systems) and the deployment setting.
2. Concretize 'AI systems cause a catastrophe' into specific unacceptable outcomes (e.g. the AI systems build a bioweapon)
...
3. Justify claims about the deployment setting.
4. Carve up the collection of AI systems into smaller groups (subsystems) that can be analyzed in isolation.
5. Assess risk from subsystems acting unilaterally.
6. Assess risk from subsystems cooperating together.
4. Carve up the collection of AI systems into smaller groups (subsystems) that can be analyzed in isolation.
5. Assess risk from subsystems acting unilaterally.
6. Assess risk from subsystems cooperating together.

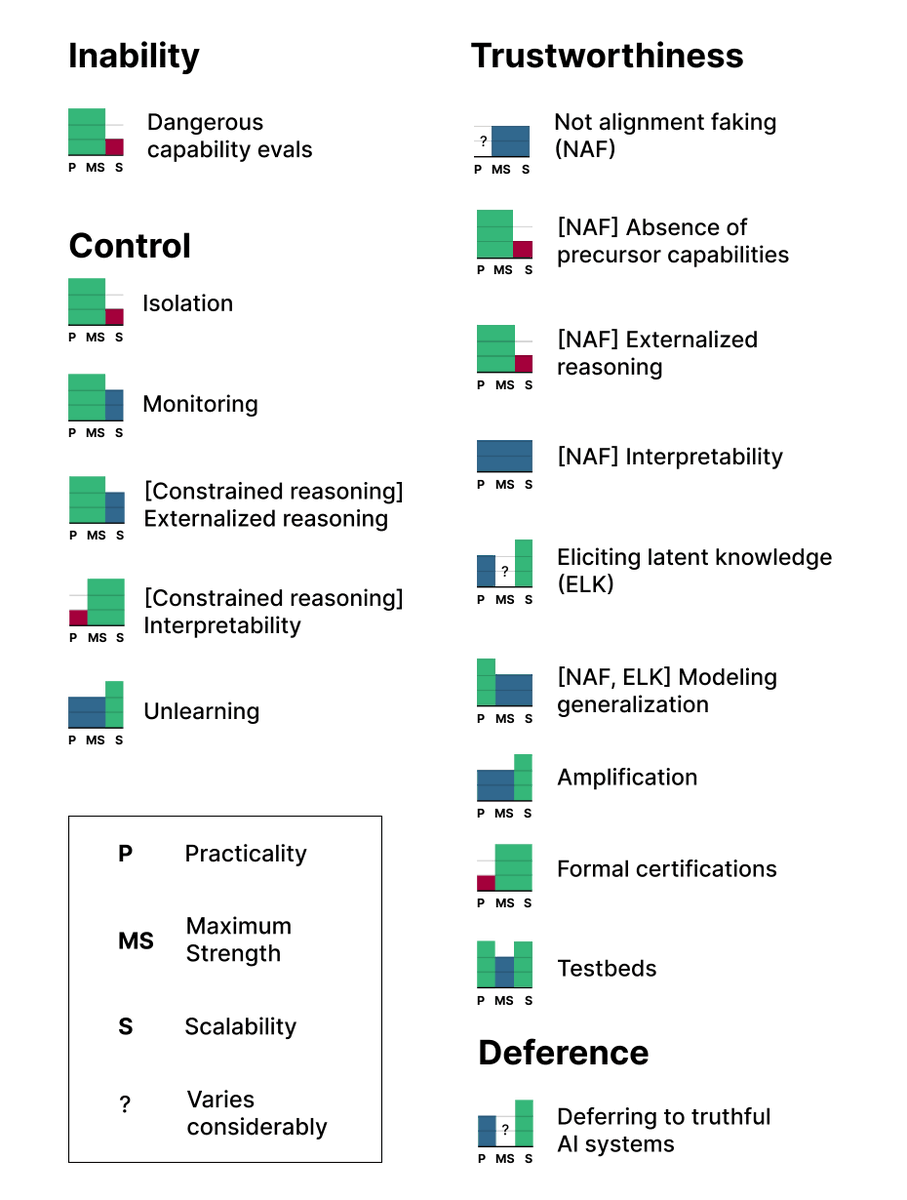
We first focus on step 5: how would developers argue that individual subsystems are safe? These arguments can be grouped into four categories.
Arguments could assert AI systems are
- too weak to be dangerous even if open-sourced (inability)
- unable to cause disaster due to restrictions (control)
- safe despite ablility to cause harm (trustworthiness)
- judged to be safe by credible AI advisors (deference)
- too weak to be dangerous even if open-sourced (inability)
- unable to cause disaster due to restrictions (control)
- safe despite ablility to cause harm (trustworthiness)
- judged to be safe by credible AI advisors (deference)

Consider the analogy of a robber and a diamond. How might one justify that the robber won’t steal the diamond?

The ordering of these categories is intentional. As AI systems become more powerful, developers will likely rely mostly on inability, then control, then trustworthiness, and finally, deference to AI advisors.

Next, we give examples of arguments in each category. Arguments are ranked on three axes:
1. Practicality
2. Strength
3. Scalability
No argument received full marks! Research will be needed to justify the safety of advanced AI systems.
1. Practicality
2. Strength
3. Scalability
No argument received full marks! Research will be needed to justify the safety of advanced AI systems.
The arguments in the previous step pertain to small groups of AI systems. It would be difficult to directly apply them to large groups. We also explain how to justify that the actions of *many* AI systems won’t cause a catastrophe (step 6 in our framework).

We are hoping this report will:
1. Motivate research that further clarifies the assumptions behind safety arguments.
2. Inform the design of hard safety standards.
1. Motivate research that further clarifies the assumptions behind safety arguments.
2. Inform the design of hard safety standards.
More in the paper:
Many thanks to my coauthors! @NickGabs01, @DavidSKrueger, and @thlarsen.
Might be of interest to @bshlgrs, @RogerGrosse, @DavidDuvenaud, @EvanHub, @aleks_madry, @ancadianadragan, @rohinmshah, @jackclarkSF, @Manderljung, @RichardMCNgobit.ly/3IJ5N95
Many thanks to my coauthors! @NickGabs01, @DavidSKrueger, and @thlarsen.
Might be of interest to @bshlgrs, @RogerGrosse, @DavidDuvenaud, @EvanHub, @aleks_madry, @ancadianadragan, @rohinmshah, @jackclarkSF, @Manderljung, @RichardMCNgobit.ly/3IJ5N95
• • •
Missing some Tweet in this thread? You can try to
force a refresh