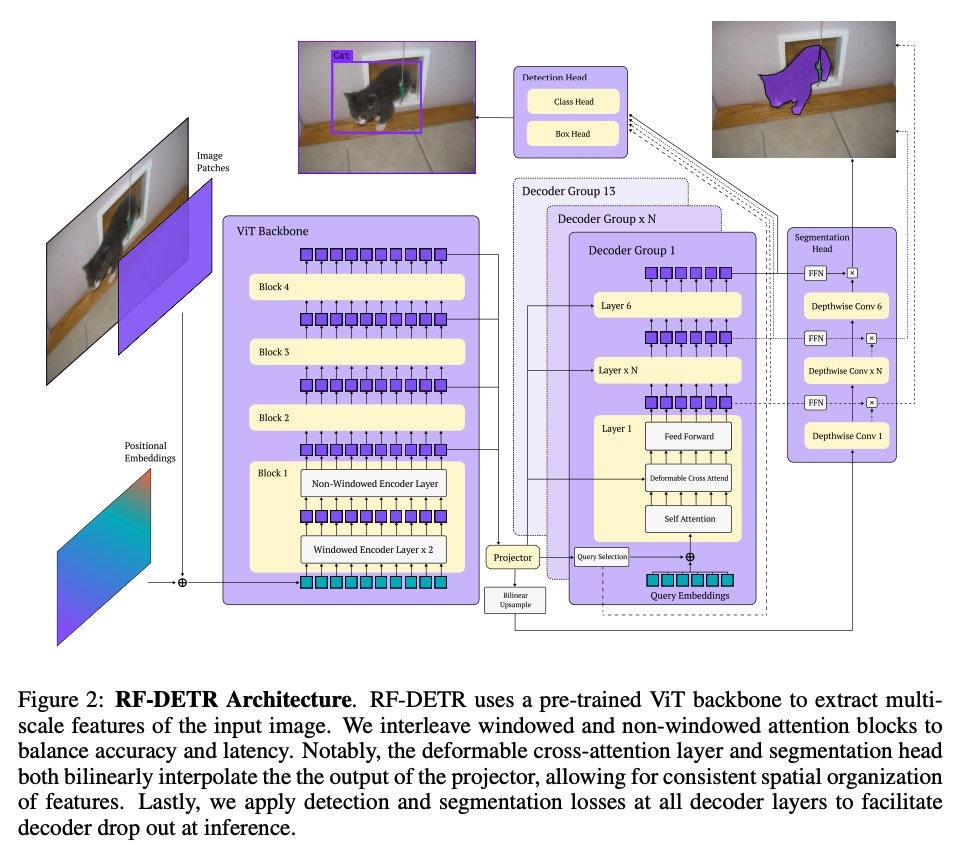
time analysis with computer vision
- blurring faces
- detection and tracking
- smoothing detections
- filtering detections by zone
- calculating time
let me know if you want me to explain anything else. ;)
code:
↓ read more github.com/roboflow/super…
- blurring faces
- detection and tracking
- smoothing detections
- filtering detections by zone
- calculating time
let me know if you want me to explain anything else. ;)
code:
↓ read more github.com/roboflow/super…
the full tutorial will be available on Monday on the @roboflow YouTube channel; subscribe so you don't miss it.
link to YouTube: youtube.com/@Roboflow

link to YouTube: youtube.com/@Roboflow

to ensure the privacy of store employees, I decided to blur their faces; to do this, we will first need a model capable of detecting them.
yesterday, I quickly labeled a few dozen images, which I used to train my model.
this is enough for the demo, but we need many more images to implement such a use case.
dataset link: universe.roboflow.com/roboflow-jvuqo…
yesterday, I quickly labeled a few dozen images, which I used to train my model.
this is enough for the demo, but we need many more images to implement such a use case.
dataset link: universe.roboflow.com/roboflow-jvuqo…
here's the result! I trained the model in Google Colab.
colab link: colab.research.google.com/github/roboflo…
colab link: colab.research.google.com/github/roboflo…
I used the inference package to run a model pre-trained on the COCO dataset to detect people. I used ByteTrack for tracking.
you can learn more about the Inference + Supervision combo from this tutorial.
tutorial link: supervision.roboflow.com/latest/how_to/…
you can learn more about the Inference + Supervision combo from this tutorial.
tutorial link: supervision.roboflow.com/latest/how_to/…
we want boxes to be stable; to reduce box flickering, we'll use smoothing - averaging the box positions based on the last N frames.
pay attention to the customer #37; on the left without smoothing, on the right with smoothing.
smoothing docs: supervision.roboflow.com/latest/detecti…
pay attention to the customer #37; on the left without smoothing, on the right with smoothing.
smoothing docs: supervision.roboflow.com/latest/detecti…
I drew the zones using MakeSense - an open-source photo labeling program I created while living in a dormitory several years ago.
make sense Github link: github.com/SkalskiP/make-…
make sense Github link: github.com/SkalskiP/make-…
here is a fragment of the logic responsible for counting time.
- if you're working with static video files, I recommend using an FPS-based approach.
- I recommend a clock-based approach if you're working with video streams.
- if you're working with static video files, I recommend using an FPS-based approach.
- I recommend a clock-based approach if you're working with video streams.


calculating the time customers spend waiting in line at a store is just one of the potential applications.
here's another use case where we calculate how long drivers wait to pass through an intersection.
here's another use case where we calculate how long drivers wait to pass through an intersection.
• • •
Missing some Tweet in this thread? You can try to
force a refresh