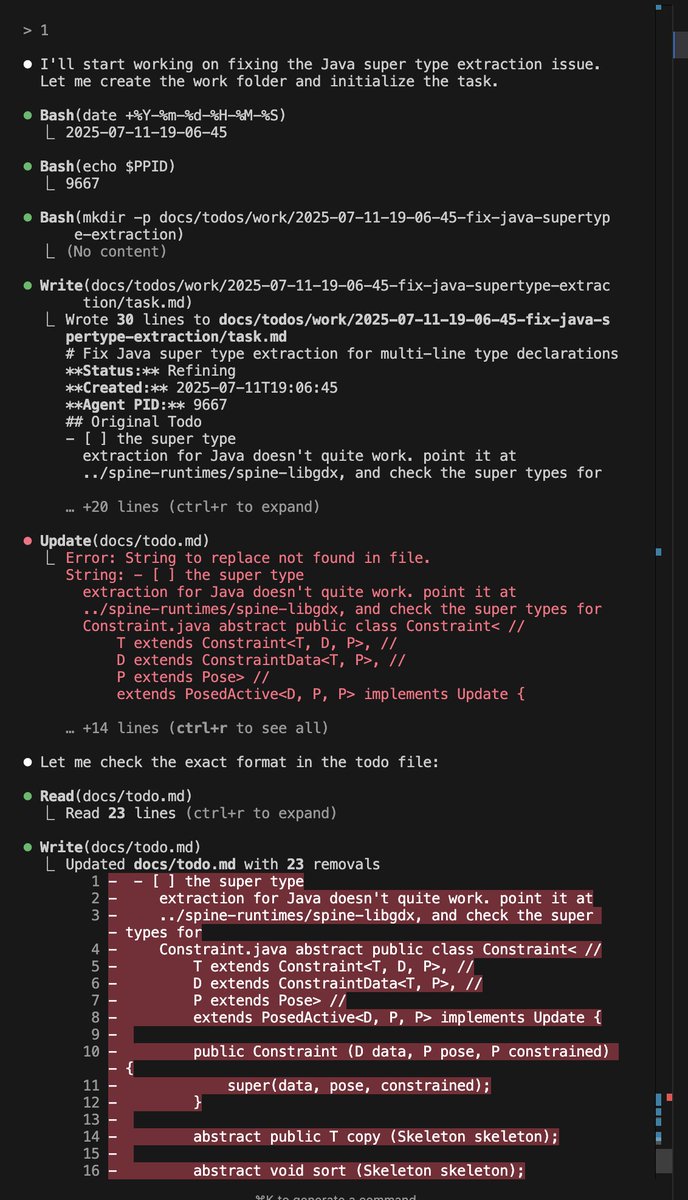
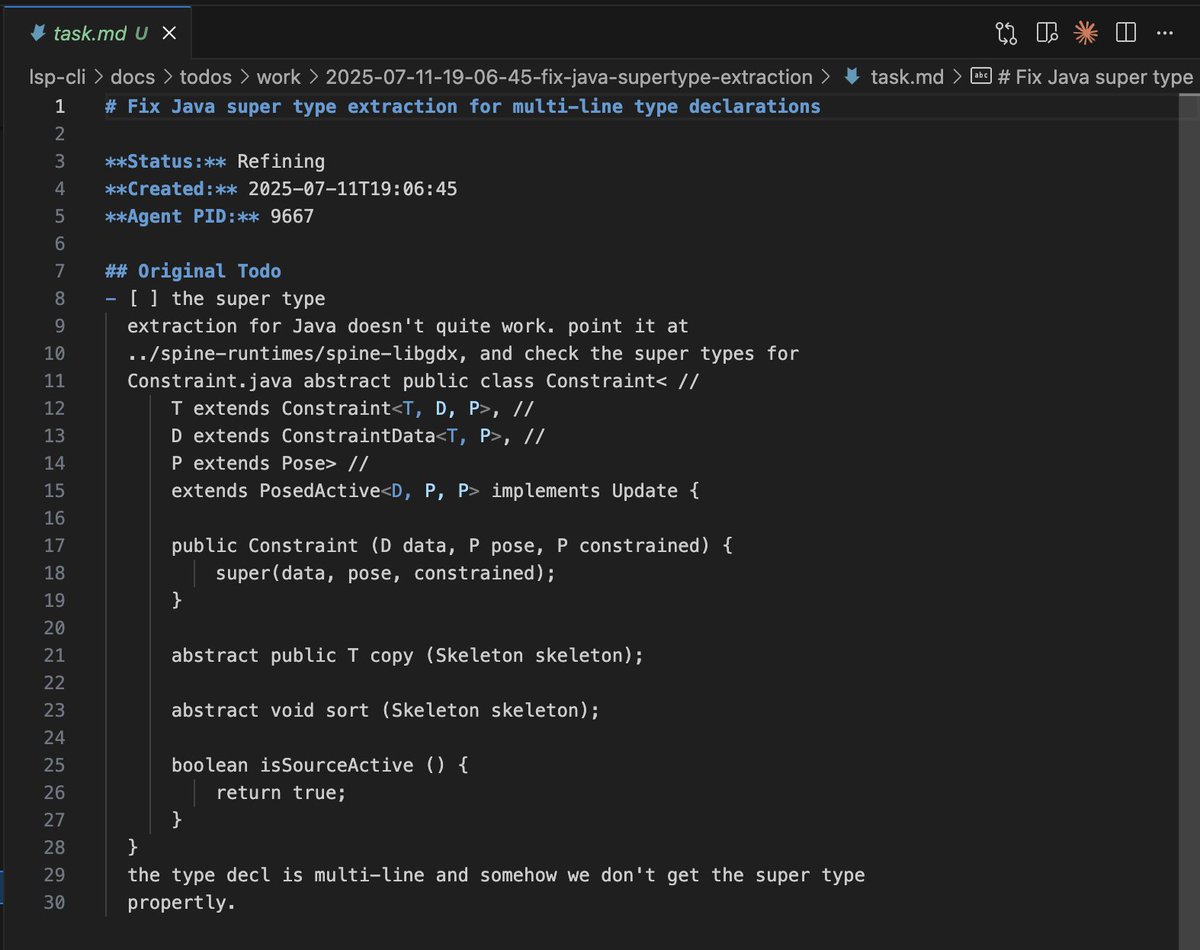
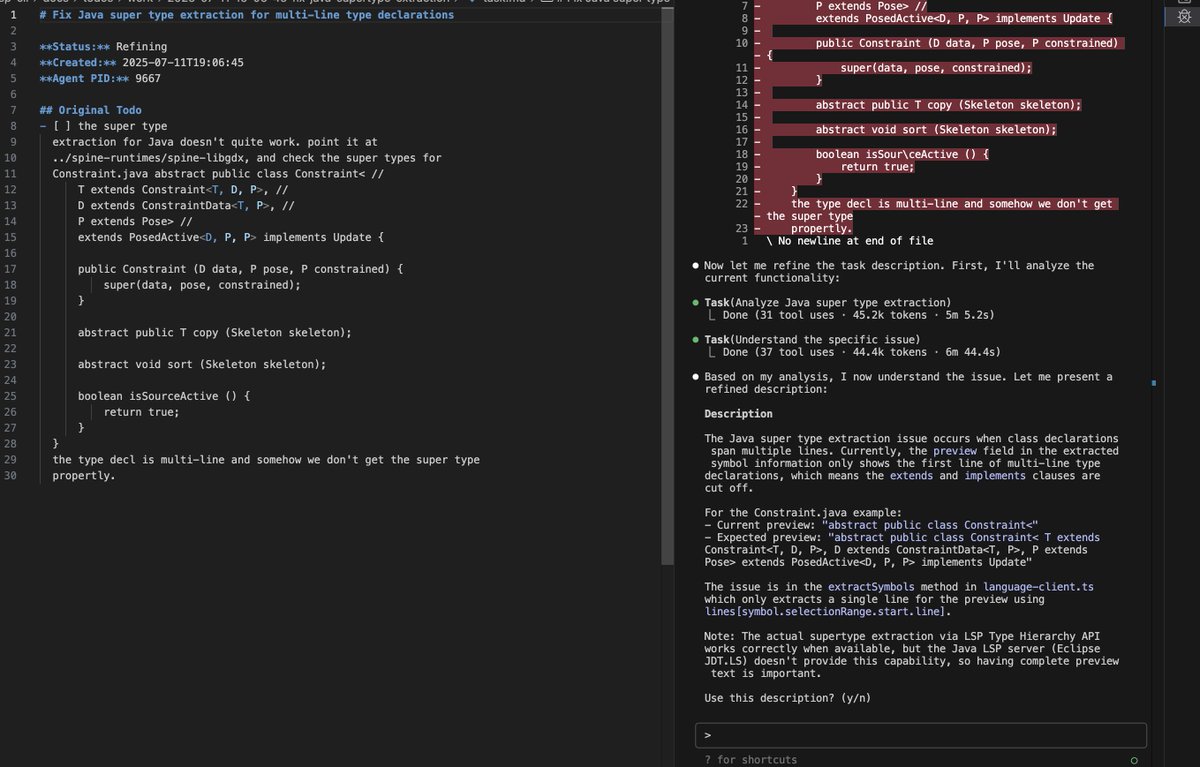
Video zur KärntenGPT Pressekonferenz.
Wir erfahren ein paar Dinge.
- Getestet wurden Mistral und Llama, welches Modell gewählt wurde, sagen sie nicht. Tippe auf Mistral, weil größeres Kontextfenster iirc.facebook.com/landkaernten/v…
Wir erfahren ein paar Dinge.
- Getestet wurden Mistral und Llama, welches Modell gewählt wurde, sagen sie nicht. Tippe auf Mistral, weil größeres Kontextfenster iirc.facebook.com/landkaernten/v…
3 Phasen, ersten 2 machen Sinn. Dritte Phase will Agents in Prozesse einziehen, die dann die 40% abgang an Personal kompensieren helfen soll.
Ja, eher nicht...
Ja, eher nicht...

Auch angedacht: telefonische Beantwortung von oft gestellten Fragen. Sportlich, bei starkem Dialekt.
Haben bei NVIDIA tatsächlich ordentlich eingekauft. Leider nix über welche Hardware konkret. budgetmässig eher nicht A100/H100?
Haben bei NVIDIA tatsächlich ordentlich eingekauft. Leider nix über welche Hardware konkret. budgetmässig eher nicht A100/H100?
Demo bei Minute 19:30
Benutzeroberfläche über die freie Open-Source Software LibreChat implementiert. Wobei "implementiert" schon ein bissl weit gegriffen ist. Leicht adaptiert triffts eher.
Benutzeroberfläche über die freie Open-Source Software LibreChat implementiert. Wobei "implementiert" schon ein bissl weit gegriffen ist. Leicht adaptiert triffts eher.

Herr Inzko sagt, er verwendet ChatGPT mehr als Google und für Recherche.
Gut, das ist eher nicht vertrauensbildend, weil das ChatGPT nicht leisten kann, Stichwort Halluzinationen.
geht da schon eher, weil es Quellen ausspuckt. perplexity.ai
Gut, das ist eher nicht vertrauensbildend, weil das ChatGPT nicht leisten kann, Stichwort Halluzinationen.
geht da schon eher, weil es Quellen ausspuckt. perplexity.ai

Zweites Demo: PDF Zusammenfassung und Zusammenfassung auf Englisch übersetzen. Hinweis: alles lokal.
Ja, das ist net. Die Zusammenfassung großer Dokumente wird aber leider ziemlicher Müll sein. Spricht: Echtwelt-Betrieb wird schwierig.
Ja, das ist net. Die Zusammenfassung großer Dokumente wird aber leider ziemlicher Müll sein. Spricht: Echtwelt-Betrieb wird schwierig.

Auf Basis des Demos haben sie LibreChat + LangChain/LlamaIndex zusammengeklatscht. Also quasi die Tutorials durchgespielt :D
Das ist schon OK. Der Echtweltkontakt wird jedenfalls spannend, sowohl Landesintern als auch ggü "Kundinnen".
Den Förderkatalog Use Case kriegen sie hin
Das ist schon OK. Der Echtweltkontakt wird jedenfalls spannend, sowohl Landesintern als auch ggü "Kundinnen".
Den Förderkatalog Use Case kriegen sie hin
Alles andere sind sehr lofty goals. We'll see.
Ah in der Q&A gibts zu Minute 25:00 mehr Info zu den Kosten. Die Hardware hat bis dato €50k gekostet. Da lag ich mit meiner Schätzung 30% für Software von €85k gar net so weit weg.
Herr Inzko argumentiert das wäre billiger als €60/Monat pro Mitarbeiter.
Herr Inzko argumentiert das wäre billiger als €60/Monat pro Mitarbeiter.
Strom und Maintenance der Hardware ist in Kärnten anscheinend gratis...
Weiter: sie werden mehrere thematische Chatbots bauen. Förderführer erste low-hanging fruit. Warum das bis Herbst dauert erschließt sich leider nicht.
Ja, das dablasen sie sicher, denk ich.
Weiter: sie werden mehrere thematische Chatbots bauen. Förderführer erste low-hanging fruit. Warum das bis Herbst dauert erschließt sich leider nicht.
Ja, das dablasen sie sicher, denk ich.
~25:00 Herr Inzko spricht davon, mit 2 Kärnter Unternehmen den Prototypen umgesetzt zu haben, aber dass sie intern die Expertise aufbauen wollen, das selbst fort zu führen um nicht in Abhängigkeit zu bleiben.
Liebe es. Sehr gute Idee. High Five für Herrn Inzko!
Liebe es. Sehr gute Idee. High Five für Herrn Inzko!
Man braucht dazu nämlich auch kein Team von 50 Leuten. Es wird gemunkelt, dass die Umsetzungsfirma genau aus 3 Leuten besteht, wovon nur einer die Umsetzung macht.
Es braucht wirklich nicht mehr. Ein FTE plus ein zweites Fallback FTE. That's it. Infra ist automatisierbar.
Es braucht wirklich nicht mehr. Ein FTE plus ein zweites Fallback FTE. That's it. Infra ist automatisierbar.
Minute 27:00 nich einmal zum Budget, €85k bisher. Wird bis 2027 noch eigenes Budget für KI geben, größter Teil für Personalaufbau.
Good!
Good!
Kaiser noch einmal zu den 40%: die werden demnächst aus dem Dienst ausscheiden.
Meint mit dem KI Projekt kann man deren Erfahrung im Haus erhalten.
Das wird jedenfalls eher nicht zutreffen. Was stimmt: die von ihnen erstellten Dokumente und Emails bleiben erhalten :)
Meint mit dem KI Projekt kann man deren Erfahrung im Haus erhalten.
Das wird jedenfalls eher nicht zutreffen. Was stimmt: die von ihnen erstellten Dokumente und Emails bleiben erhalten :)
Und aus.
Das war jetzt net deppat. Herr Inzko wird ws. intern a bissl unruhig gwesen sein, weil das Demo halt net wirklich gut demonstriert, was da alles an Infra im Hintergrund gebaut wurde.
Jedenfalls bis aufs trottelige Marketing kein voller Klogriff wie der AMS Bot.
Das war jetzt net deppat. Herr Inzko wird ws. intern a bissl unruhig gwesen sein, weil das Demo halt net wirklich gut demonstriert, was da alles an Infra im Hintergrund gebaut wurde.
Jedenfalls bis aufs trottelige Marketing kein voller Klogriff wie der AMS Bot.
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh