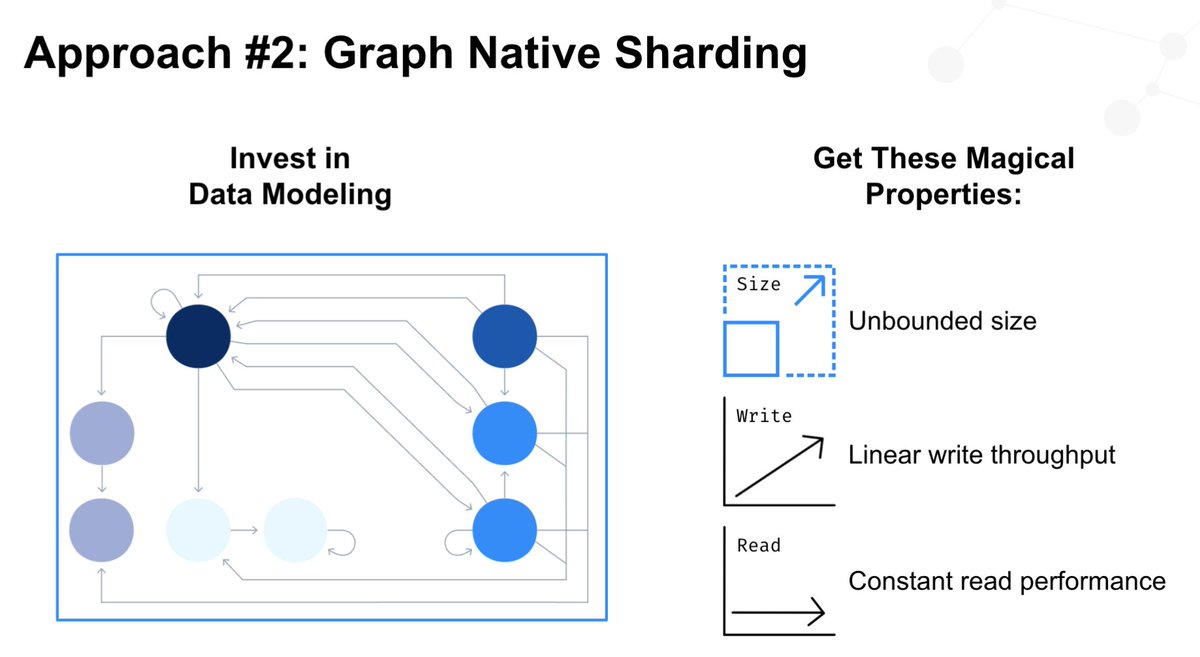
Ok, this is pretty crazy.
SQL has been the lingua franca of database querying since the dawn of time.
But for the first time in over three decades (!), ISO just published a NEW database query language called GQL -- the Graph Query Language!
SQL has been the lingua franca of database querying since the dawn of time.
But for the first time in over three decades (!), ISO just published a NEW database query language called GQL -- the Graph Query Language!

Prior to SQL, there were a bunch of different relational query languages. But the industry came together to create one unified query language so that vendors could compete not on syntax & lockin, but on the strength of their implementations.
The goal of GQL is the same.
The goal of GQL is the same.
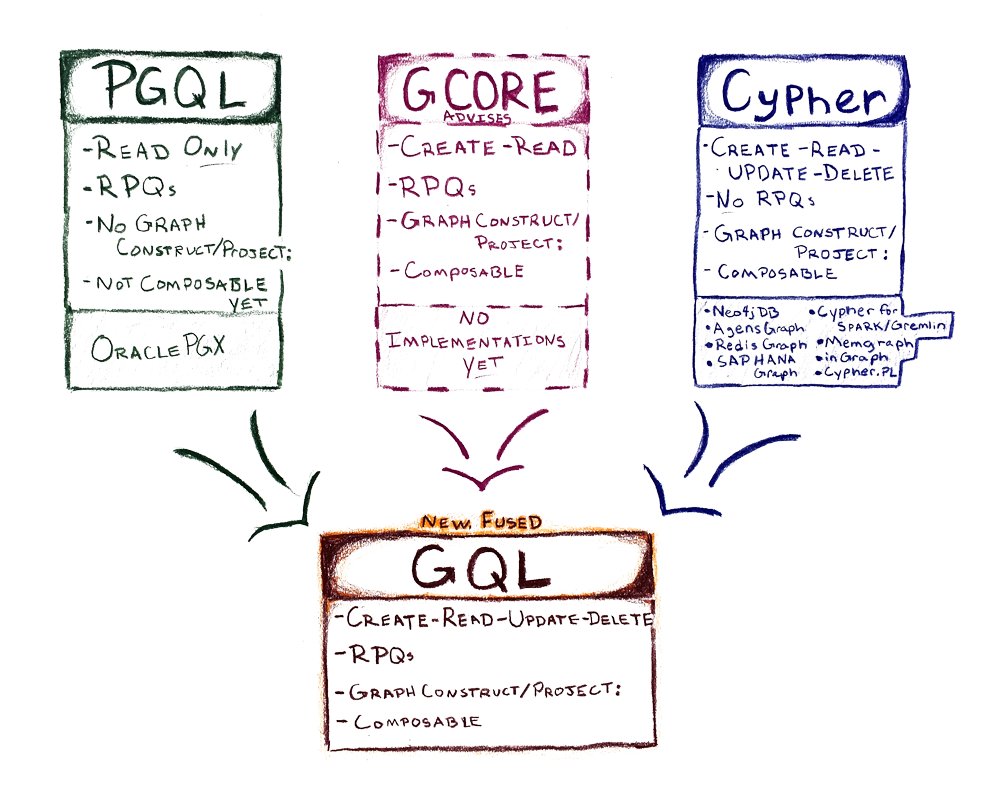
The origin of GQL goes all the way back to 2015 when we announced @openCypher with the goal to create a unified language for declarative graph querying. It took many years, but Cypher is now the most popular graph query language, supported by many DBs including @neo4j & Neptune.

But GQL is truly a joint effort. Lots of graph vendors came together to create the best possible graph query language, with an eye towards a future where users can write applications with one query language and it will immediately (or with low effort) run on all implementations.
When SQL got standardized in the 80s, it was like a lightning strike for the budding category of relational databases. The industry was already going through a platform shift (from mainframe to client/server) and as a new class of applications emerged they all got built on SQL.
GQL has the potential to do that for graph databases. The AI platform shift is driving a surge of adoption of Knowledge Graphs.
And as this new class of AI applications emerge, they will be built on top of the first standardized query language since SQL.
neo4j.com/blog/gql-inter…
And as this new class of AI applications emerge, they will be built on top of the first standardized query language since SQL.
neo4j.com/blog/gql-inter…
• • •
Missing some Tweet in this thread? You can try to
force a refresh