
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
Paper:
Github:
Documentation: arxiv.org/abs/2404.19756
github.com/KindXiaoming/p…
kindxiaoming.github.io/pykan/
Github:
Documentation: arxiv.org/abs/2404.19756
github.com/KindXiaoming/p…
kindxiaoming.github.io/pykan/
This is a joint work w/ @tegmark and awesome collaborators from MIT, Northeastern, IAIFI and Caltech.
@tegmark 1/N MLPs are foundational for today's deep learning architectures. Is there an alternative route/model? We consider a simple change to MLPs: moving activation functions from nodes (neurons) to edges (weights)! 
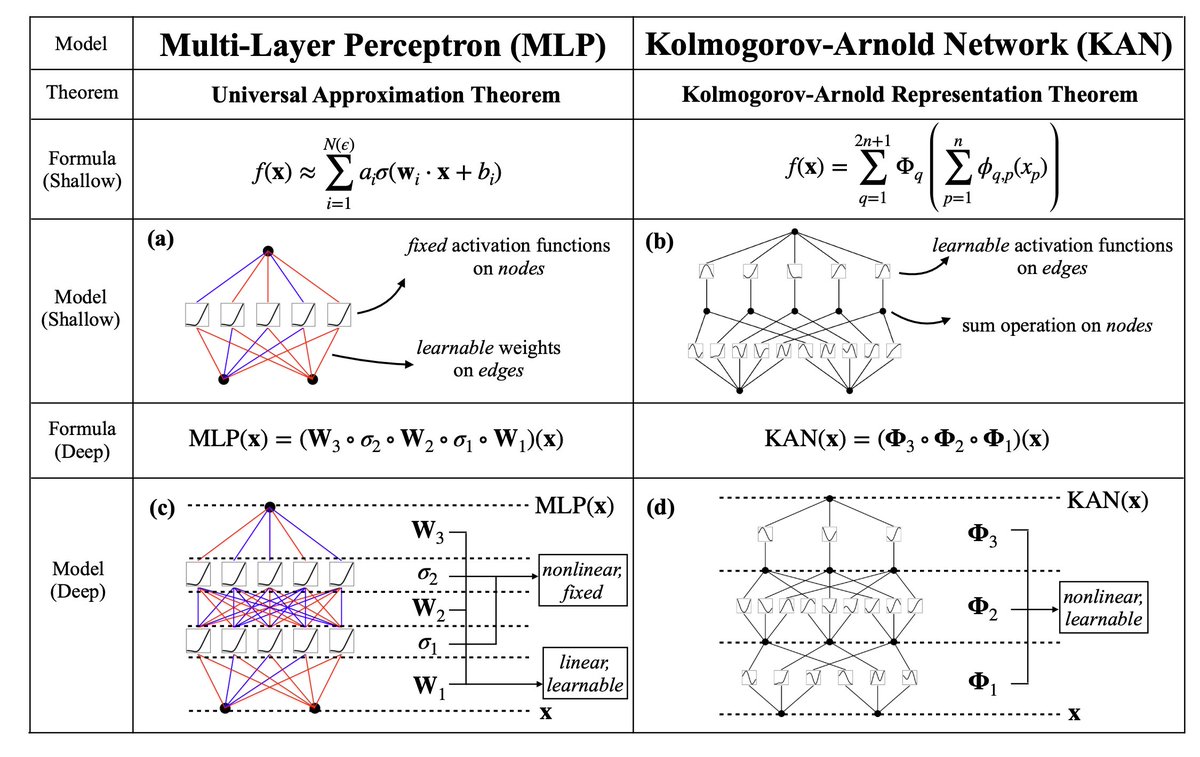
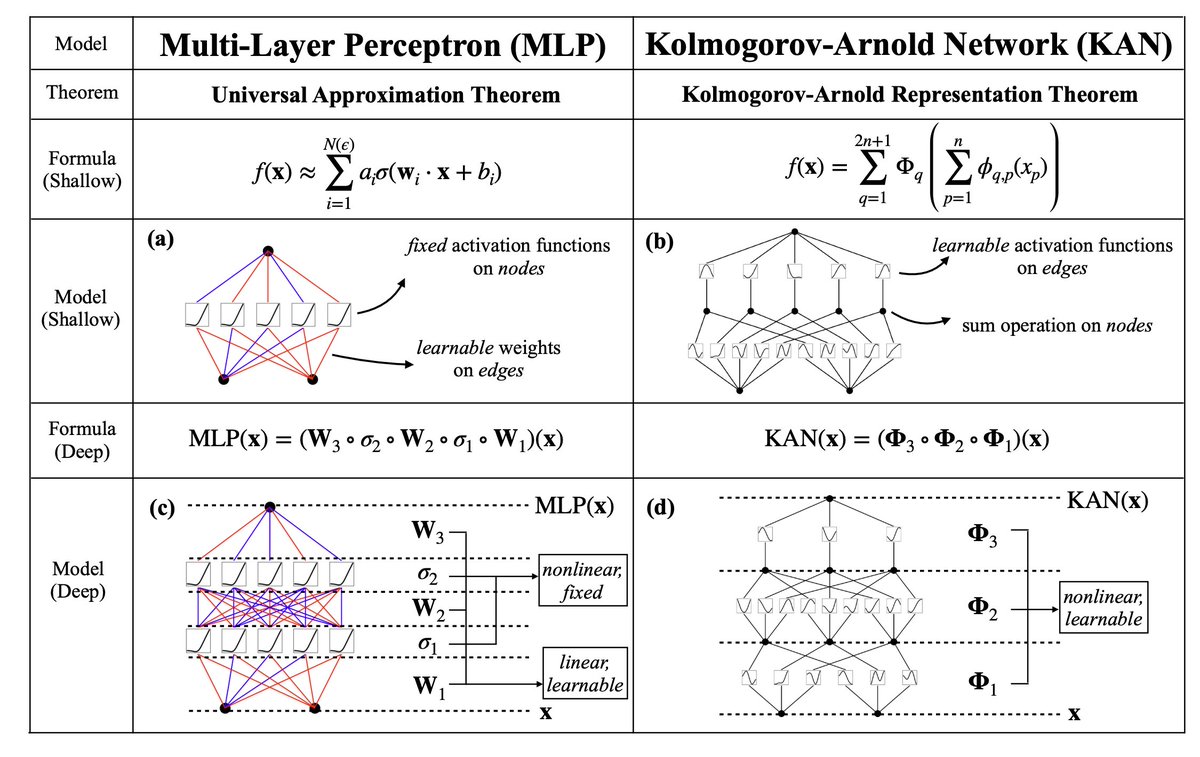
@tegmark 2/N This change sounds from nowhere at first, but it has rather deep connections to approximation theories in math. It turned out, Kolmogorov-Arnold representation corresponds to 2-Layer networks, with (learnable) activation functions on edges instead of on nodes.
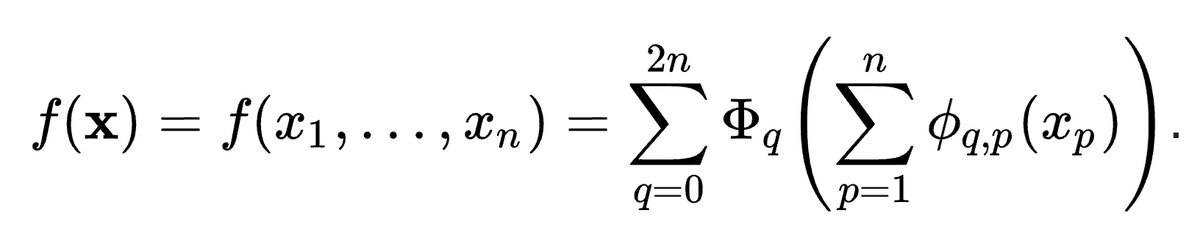
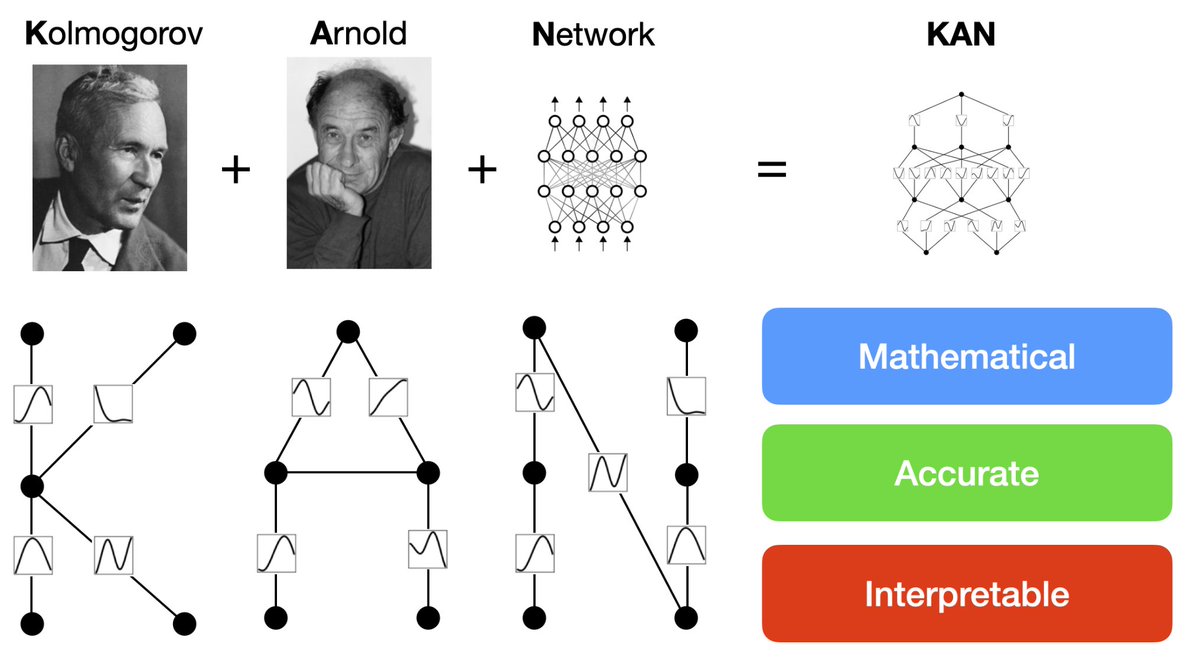
@tegmark 3/N Inspired by the representation theorem, we explicitly parameterize the Kolmogorov-Arnold representation with neural networks. In honor of two great late mathematicians, Andrey Kolmogorov and Vladimir Arnold, we call them Kolmogorov-Arnold Networks (KANs).
@tegmark 4/N From the math aspect: MLPs are inspired by the universal approximation theorem (UAT), while KANs are inspired by the Kolmogorov-Arnold representation theorem (KART). Can a network achieve infinite accuracy with a fixed width? UAT says no, while KART says yes (w/ caveat).
5/N From the algorithmic aspect: KANs and MLPs are dual in the sense that -- MLPs have (usually fixed) activation functions on neurons, while KANs have (learnable) activation functions on weights. These 1D activation functions are parameterized as splines.
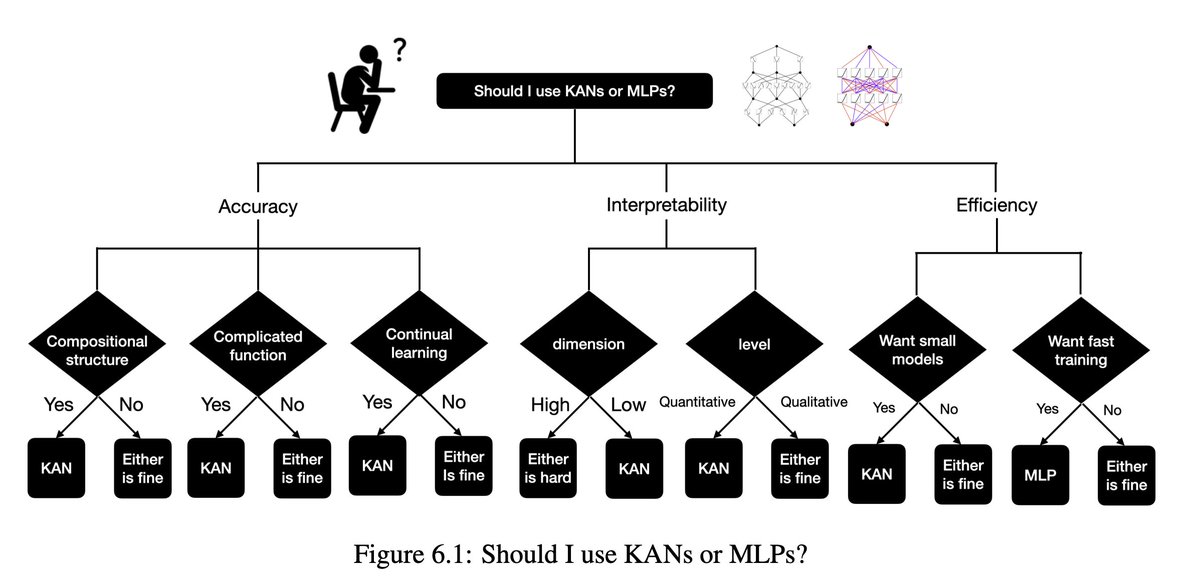
6/N From practical aspects: We find that KANs are more accurate and interpretable than MLPs, although we have to be honest that KANs are slower to train due to their learnable activation functions. Below we present our results.
7/N Neural scaling laws: KANs have much faster scaling than MLPs, which is mathematically grounded in the Kolmogorov-Arnold representation theorem. KAN's scaling exponent can also be achieved empirically.
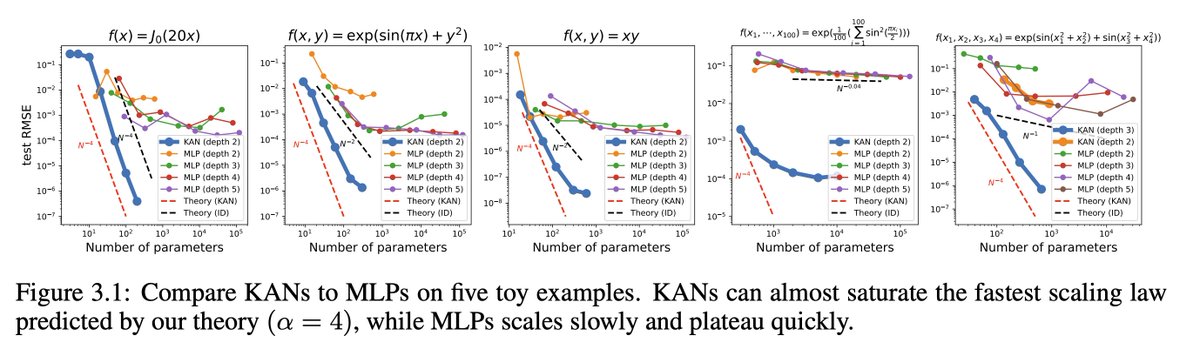
8/N KANs are more accurate than MLPs in function fitting, e.g, fitting special functions.

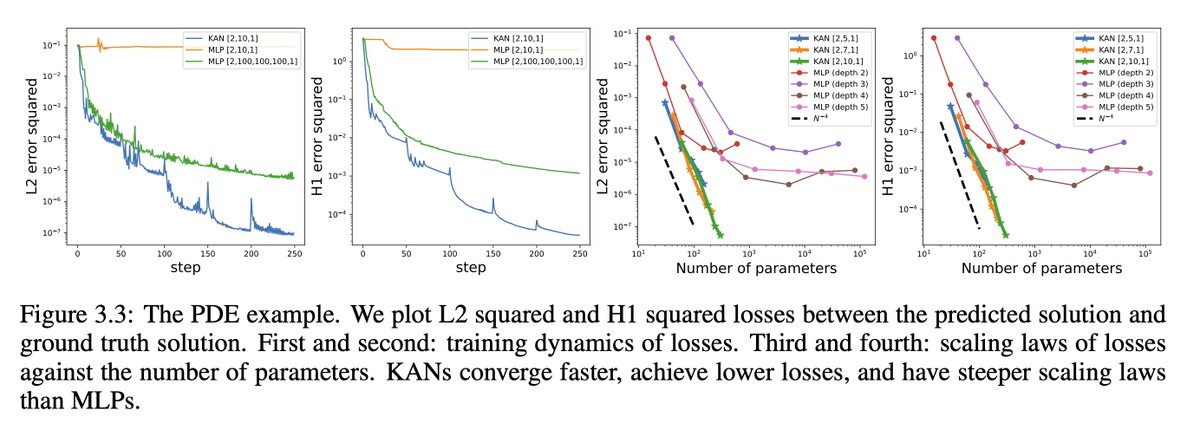
9/N KANs are more accurate than MLPs in PDE solving, e.g, solving the Poisson equation.
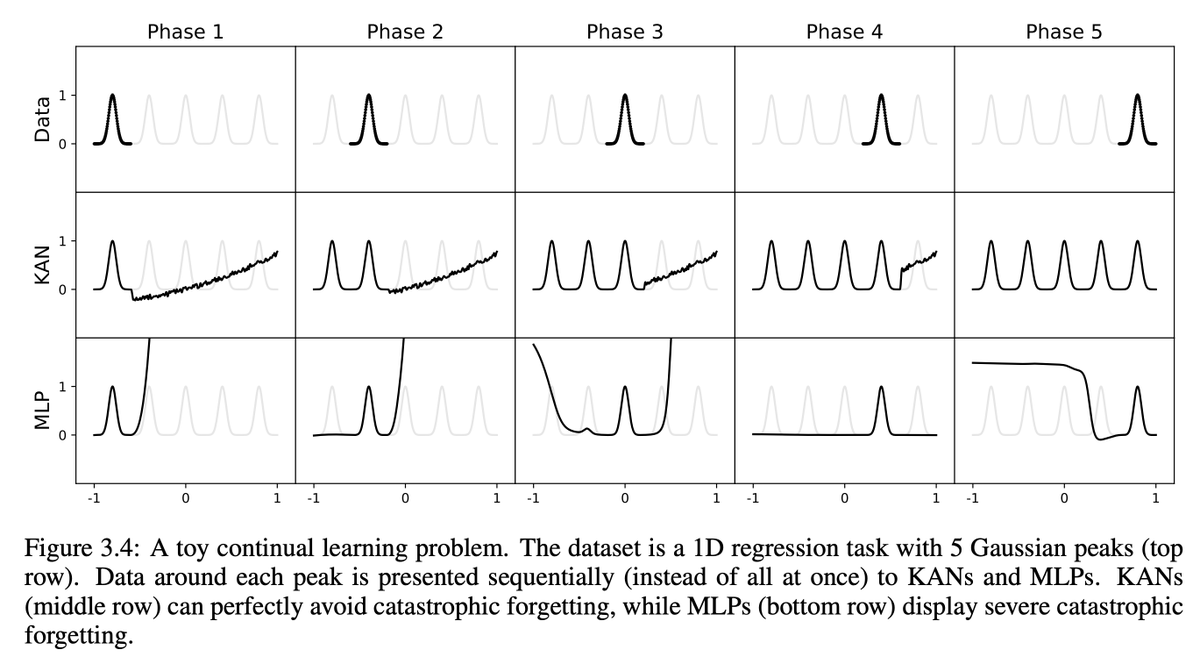
10/N As a bonus, we also find KANs' natural ability to avoid catastrophic forgetting, at least in a toy case we tried.
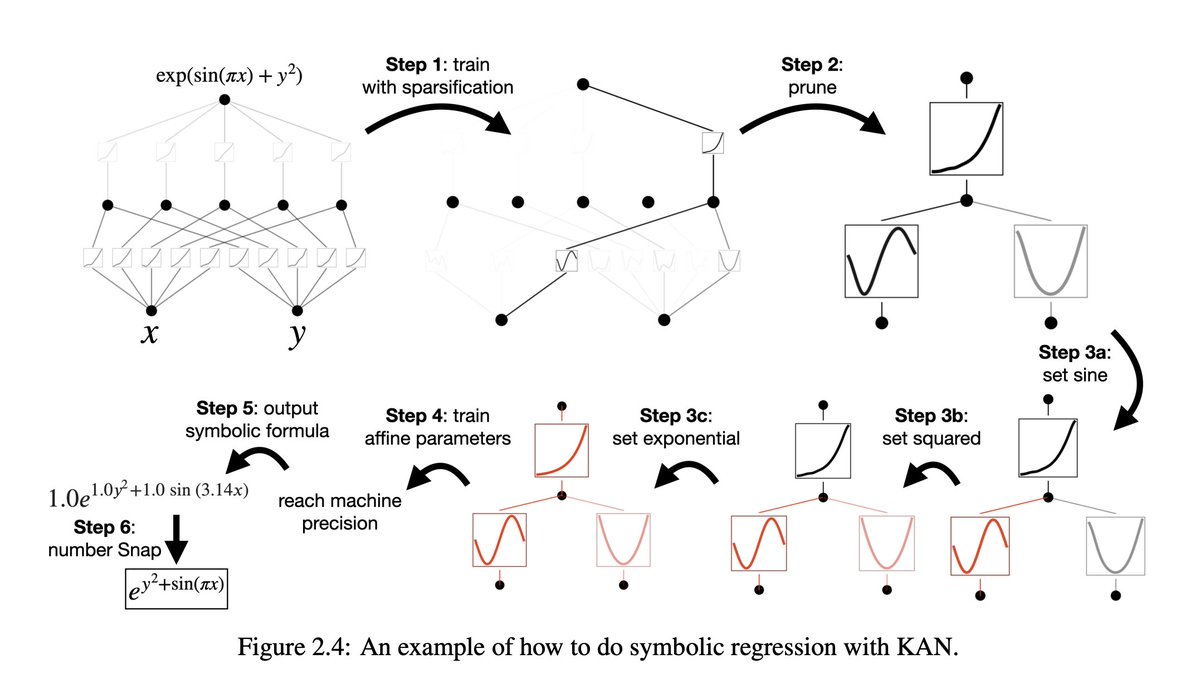
11/N KANs are also interpretable. KANs can reveal compositional structures and variable dependence of synthetic datasets from symbolic formulas.
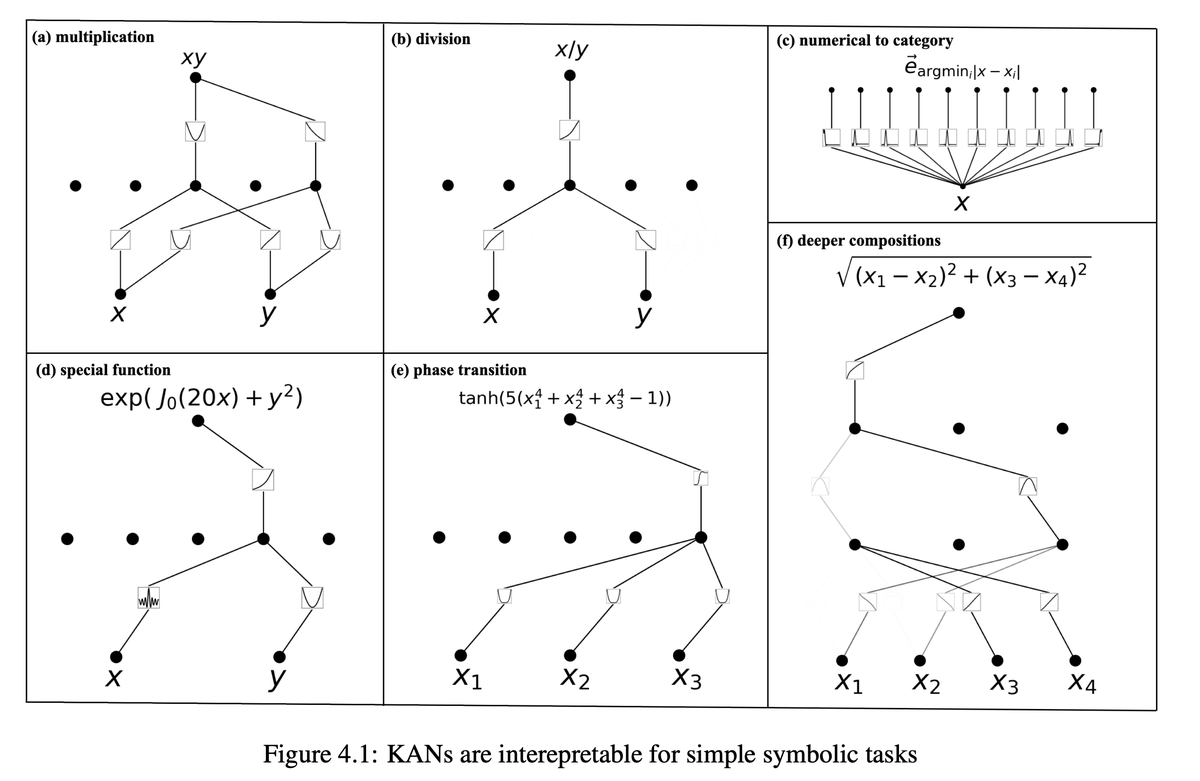
12/N Human users can interact with KANs to make them more interpretable. It’s easy to inject human inductive biases or domain knowledge into KANs.
13/N We used KANs to rediscover mathematical laws in knot theory. KANs not only reproduced Deepmind's results with much smaller networks and much more automation, KANs also discovered new formulas for signature and discovered new relations of knot invariants in unsupervised ways.
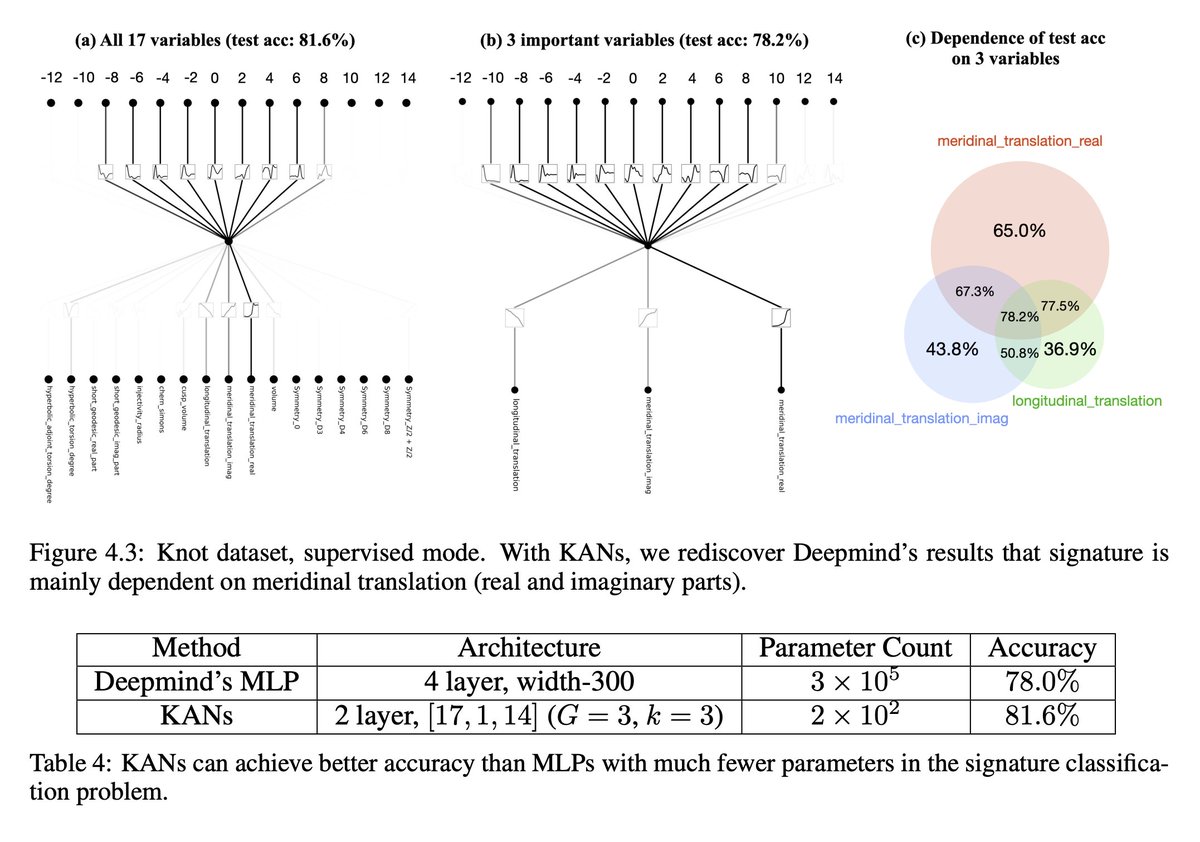
14/N In particular, Deepmind’s MLPs have ~300000 parameters, while our KANs only have ~200 parameters. KANs are immediately interpretable, while MLPs require feature attribution as post analysis.
15/N KANs are also helpful assistants or collaborators for scientists. We showed how KANs can help study Anderson localization, a type of phase transition in condensed matter physics. KANs make extraction of mobility edges super easy, either numerically,
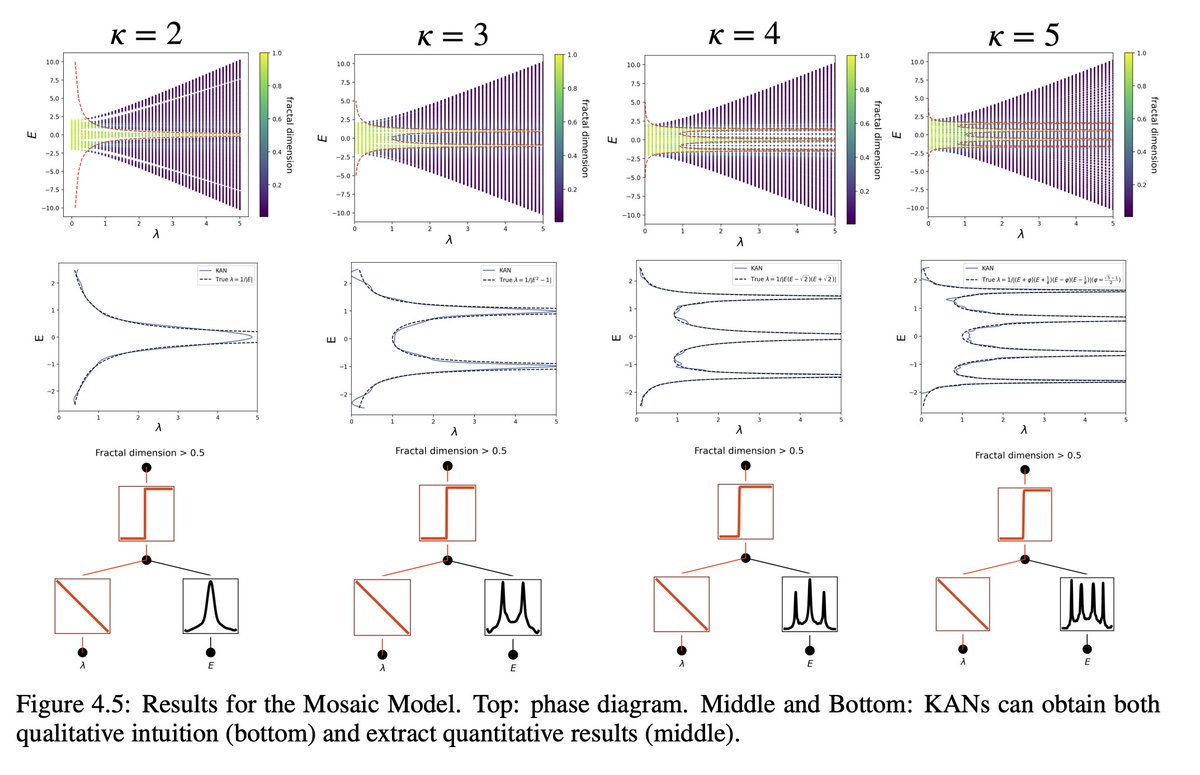
16/N, or symbolically
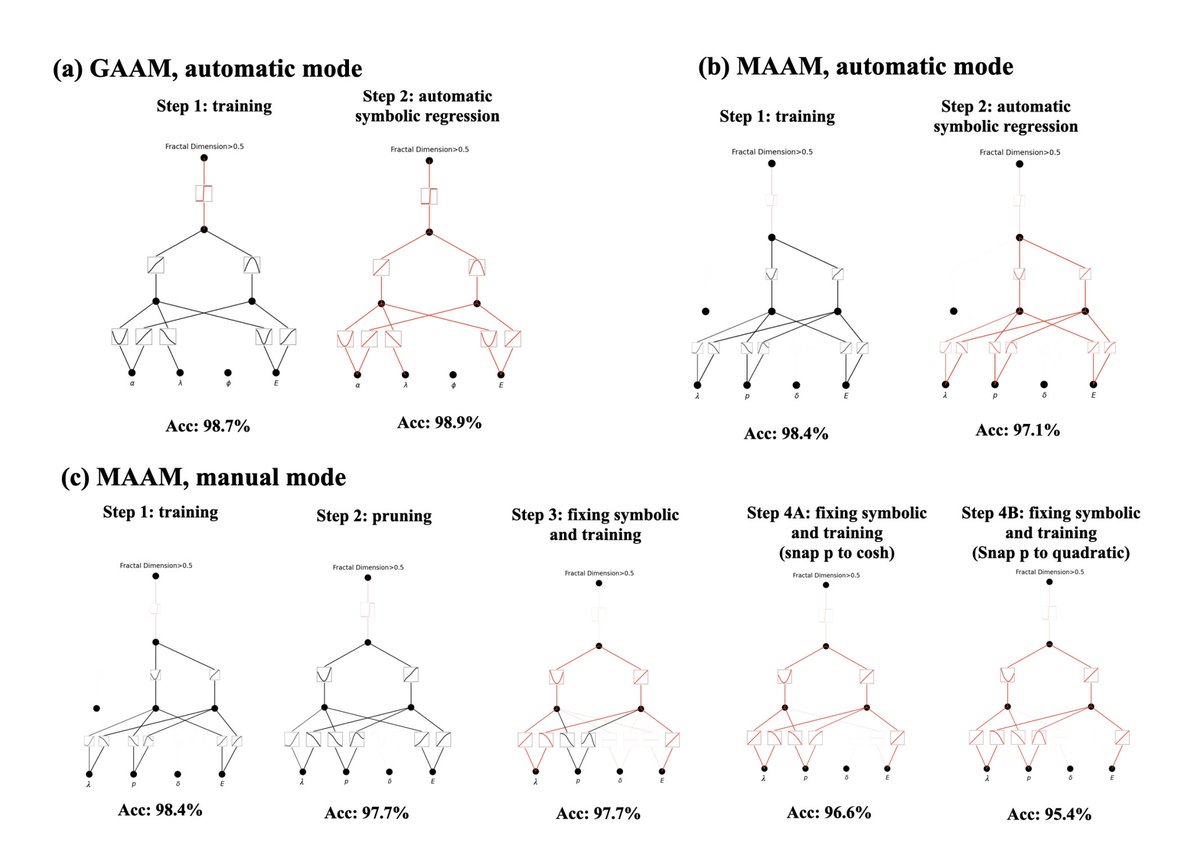

17/N Given our empirical results, we believe that KANs will be a useful model/tool for AI + Science due to their accuracy, parameter efficiency and interpretability. The usefulness of KANs for machine learning-related tasks is more speculative and left for future work.
18/N Computation requirements:
All examples in our paper can be reproduced in less than 10 minutes on a single CPU (except for sweeping hyperparams). Admittedly, the scale of our problems are smaller than many machine learning tasks, but are typical for science-related tasks.
All examples in our paper can be reproduced in less than 10 minutes on a single CPU (except for sweeping hyperparams). Admittedly, the scale of our problems are smaller than many machine learning tasks, but are typical for science-related tasks.
Also fun to collaborate (again) with my friend @RoyWang67103904 whom I knew from elementary school :)
19/N Why is training slow?
Reason 1: technical. learnable activation functions (splines) are more expensive to evaluate than fixed activation functions.
Reason 2: personal. The physicist in my body would suppress my coder personality so I didn't try (know) optimizing efficiency.
Reason 1: technical. learnable activation functions (splines) are more expensive to evaluate than fixed activation functions.
Reason 2: personal. The physicist in my body would suppress my coder personality so I didn't try (know) optimizing efficiency.
20/N Adapt to transformers: I have no idea how to do that, although a naive (but might be working!) extension is just replacing MLPs by KANs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



