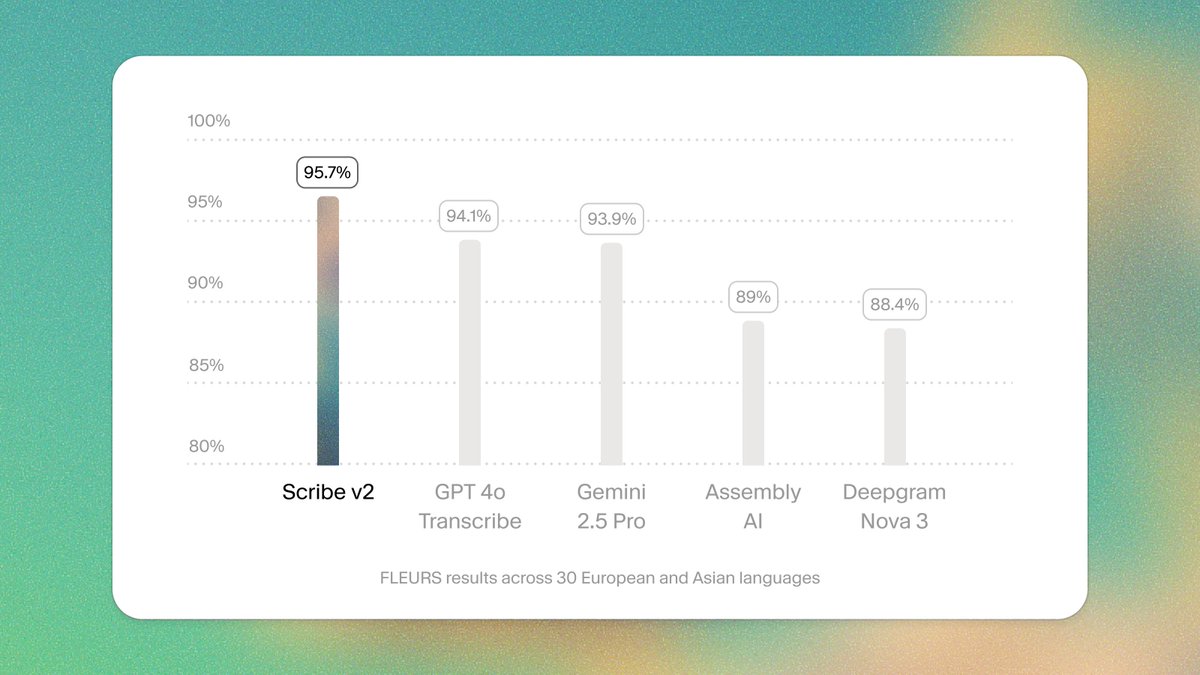
Here’s an early preview of ElevenLabs Music.
All of the songs in this thread were generated from a single text prompt with no edits.
Title: It Started to Sing
Style: “Pop pop-rock, country, top charts song.”
All of the songs in this thread were generated from a single text prompt with no edits.
Title: It Started to Sing
Style: “Pop pop-rock, country, top charts song.”
Title: It Started to Sing (Jazz Version)
Style: “A jazz pop top charts song with emotional vocals, catchy chorus, and trumpet solos.”
Style: “A jazz pop top charts song with emotional vocals, catchy chorus, and trumpet solos.”
Title: Broke my Heart
Style: “Smooth Contemporary R&B with subtle Electronic elements, featuring a pulsing 104 BPM drum machine beat, filtered synths, lush electric piano, and soaring strings, with an intimate mood.”
Style: “Smooth Contemporary R&B with subtle Electronic elements, featuring a pulsing 104 BPM drum machine beat, filtered synths, lush electric piano, and soaring strings, with an intimate mood.”
Title: My Love
Style: “Indie Rock with 90s influences, featuring a combination of clean and distorted guitars, driving drum beats, and a prominent bassline, with a moderate tempo around 120 BPM, and a mix of introspective and uplifting moods, evoking a sense of nostalgia and hope.”
Style: “Indie Rock with 90s influences, featuring a combination of clean and distorted guitars, driving drum beats, and a prominent bassline, with a moderate tempo around 120 BPM, and a mix of introspective and uplifting moods, evoking a sense of nostalgia and hope.”
• • •
Missing some Tweet in this thread? You can try to
force a refresh