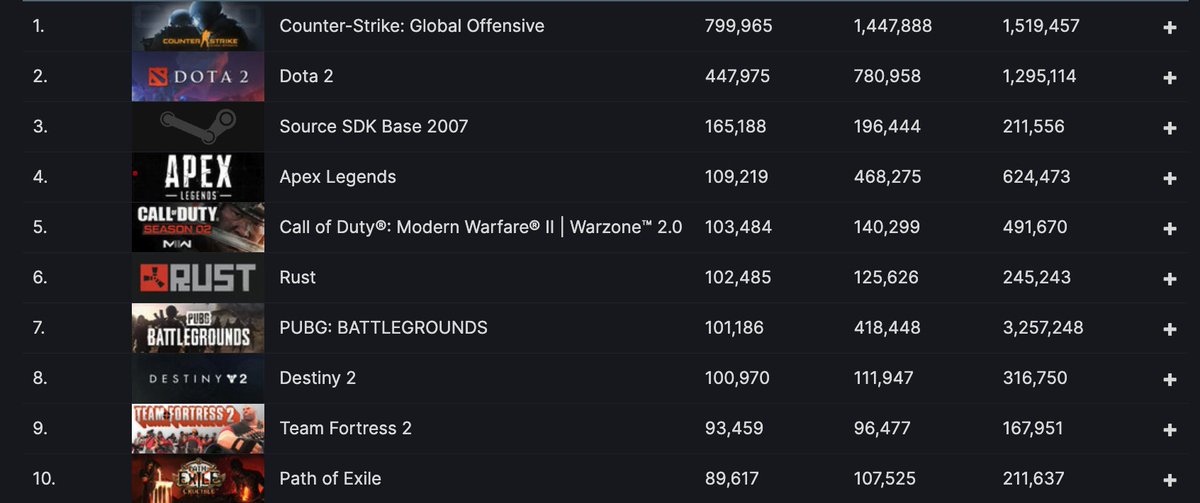
I think people are just not reading the blog post, so I'll help OpenAI out a bit and just post the coolest demos from it here.
TLDR: GPT4o is fully multimodal, as in input *and* output
One of these outputs is audio (not voice, *audio*, which is why it can sing)
The API only exposes audio/video to "select partners" for now, but these are some of the demos they show on the blog post:
TLDR: GPT4o is fully multimodal, as in input *and* output
One of these outputs is audio (not voice, *audio*, which is why it can sing)
The API only exposes audio/video to "select partners" for now, but these are some of the demos they show on the blog post:
Consistent image generation for a narrative.
This is *not* the model calling DALL-E like in ChatGPT today, these images are coming directly from the model
This is *not* the model calling DALL-E like in ChatGPT today, these images are coming directly from the model

Which is why it can do things like this, where it manipulates an existing image with ease
No IPAdapters, ControlNets etc. needed!
No IPAdapters, ControlNets etc. needed!

It can take styles from images and do things like mixing styles into a new font


Synthesize an image with text that looks like it was written on paper

It can transcribe meeting notes (nothing new)
But it can also do speaker diarization, infer the speaker identities from the context, and register emotional voice cues
But it can also do speaker diarization, infer the speaker identities from the context, and register emotional voice cues
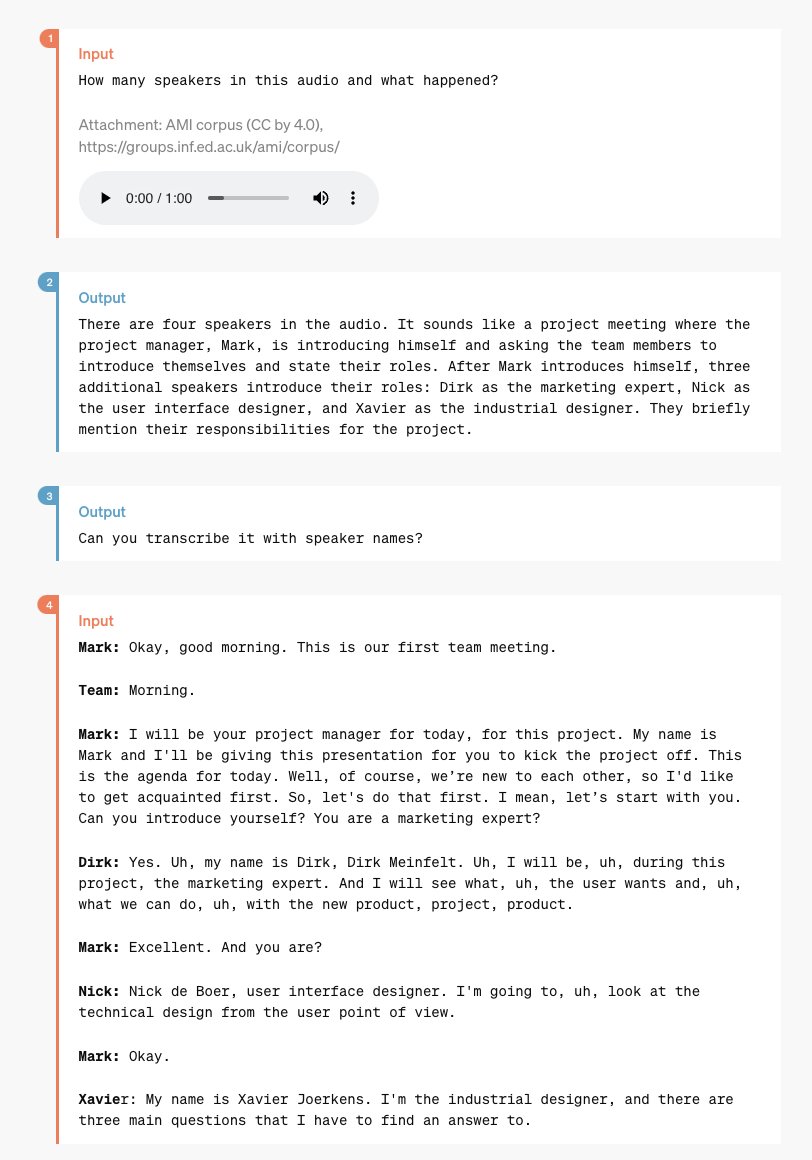
Seriously, check out the actual blog post, this is a huge deal, they severely undersold it in the presentation (and even the presentation was impressive!) openai.com/index/hello-gp…
• • •
Missing some Tweet in this thread? You can try to
force a refresh