
Can we teach LMs to internalize chain-of-thought (CoT) reasoning steps? We found a simple method: start with an LM trained with CoT, gradually remove CoT steps and finetune, forcing the LM to internalize reasoning.
Paper:
Done w/ @YejinChoinka @pmphlt 1/5 bit.ly/internalize_st…
Paper:
Done w/ @YejinChoinka @pmphlt 1/5 bit.ly/internalize_st…
Approach: Training has multiple stages.
-Stage 0: the model is trained to predict the full CoT and the answer.
-Stage 1: the first CoT token is removed, and the model is finetuned to predict the remaining CoT and the answer.
-This continues until all CoT tokens are removed. 2/5
-Stage 0: the model is trained to predict the full CoT and the answer.
-Stage 1: the first CoT token is removed, and the model is finetuned to predict the remaining CoT and the answer.
-This continues until all CoT tokens are removed. 2/5

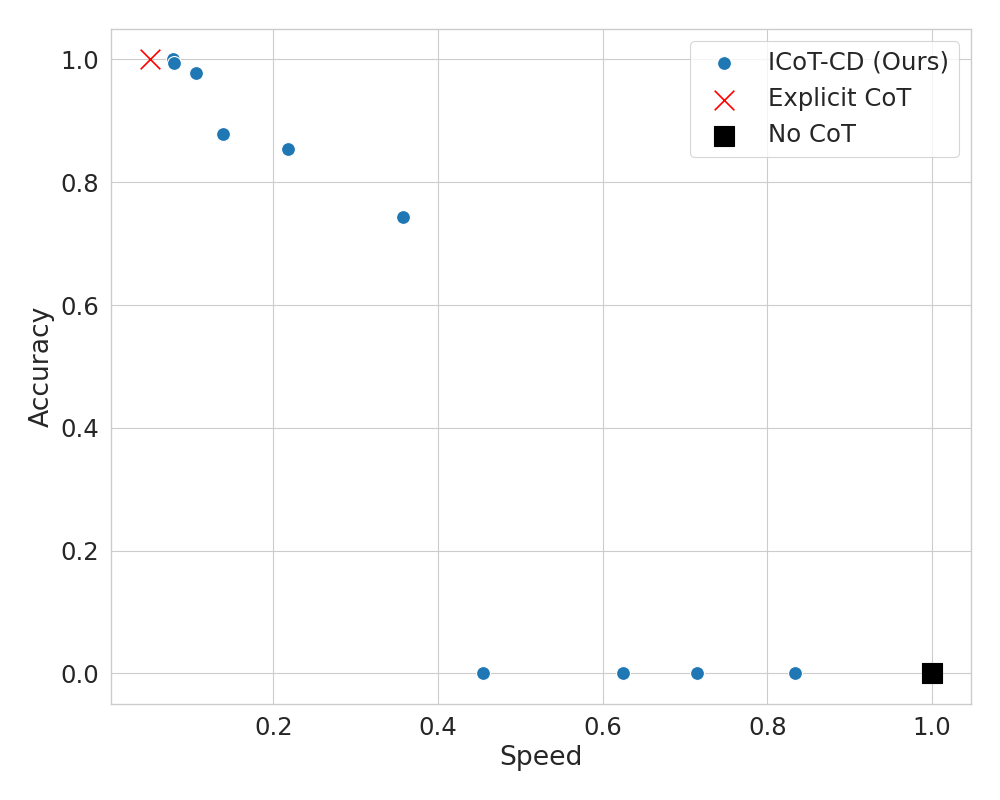
Results: We finetuned a GPT-2 Small to solve 9-by-9 multiplication with 99% accuracy. This simple method can be applied to any task involving CoT. For example, we finetuned Mistral 7B to achieve 51% accuracy on GSM8K without producing any intermediate steps. 3/5
Even if we can't internalize all CoT steps, partial internalization can lead to speedups during generation. For example, on 11-by-11 multiplication, we achieve over 74% accuracy using only 1/7 of the CoT steps (at 4X the speed) by internalizing 6/7 of the CoT tokens. 4/5
All code, models, and logs can be found at 5/5github.com/da03/Internali…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



