
Thanks @_akhaliq for sponsoring. You can now use MInference online in HF Demo with ZeroGPU.
Now, you can process 1M context 10x faster in a single A100 using Long-context LLMs like LLaMA3-1M, GLM4-1M, with even better acc, try MInference 1.0 right now! huggingface.co/spaces/microso…
Now, you can process 1M context 10x faster in a single A100 using Long-context LLMs like LLaMA3-1M, GLM4-1M, with even better acc, try MInference 1.0 right now! huggingface.co/spaces/microso…
https://twitter.com/_akhaliq/status/1809955332178706899
1) The motivation behind MInference is long-context inference is highly resource-intensive, yet inherently sparse and dynamic. We use dynamic sparse attention to accelerate the pre-filling of 1M inference by up to 10x. For more details, visit project page: aka.ms/MInference

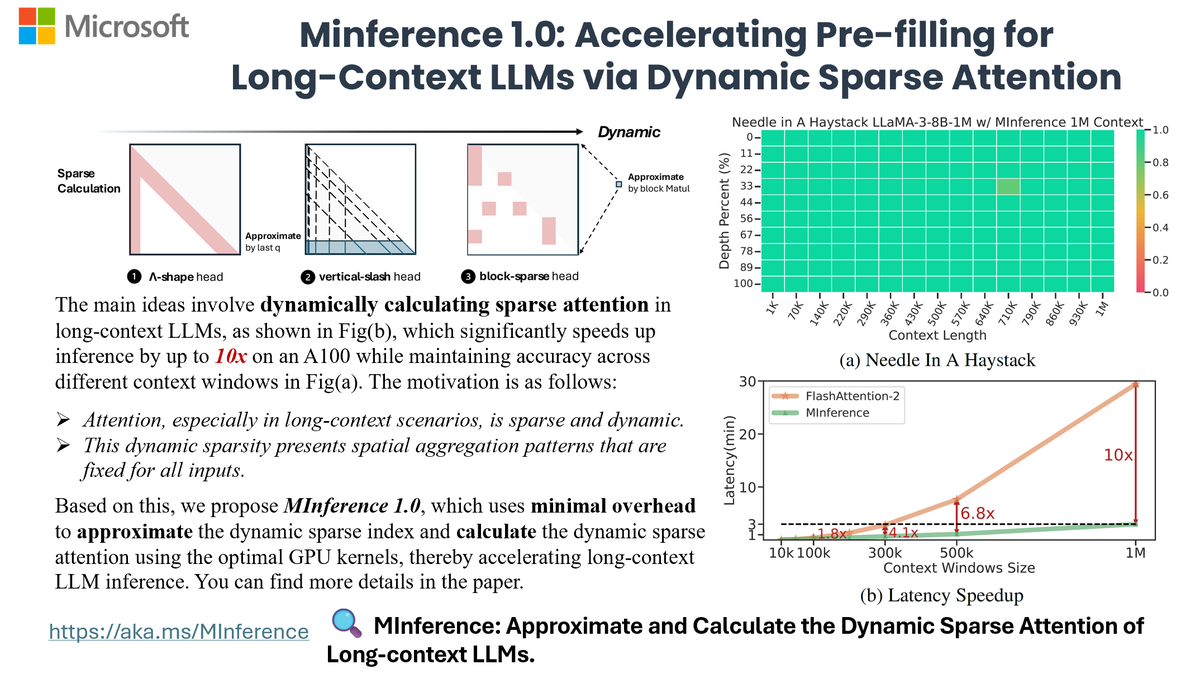
2) We categorize attention into 3 patterns: A-shape, Vertical-Slash, Block-Sparse. Through offline search, determine optimal sparse pattern for each head with 1 example. Then approximate dynamic sparse indices online and use optimal GPU kernels for dynamic sparse calculations.

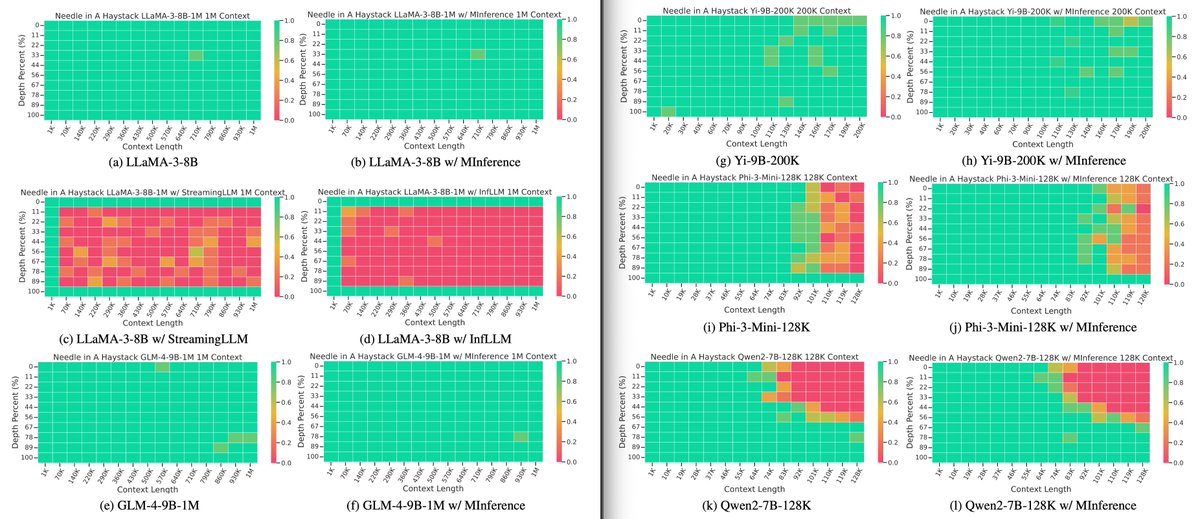
3) We evaluated MInference on a wide range of SoTA long-text benchmarks, from 128K to 1M, including RULER, InfiniteBench, Needle Test, and PG-19, on SoTA open-source long-context LLMs, including LLaMA-3-1M, GLM-4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K. with same performance.
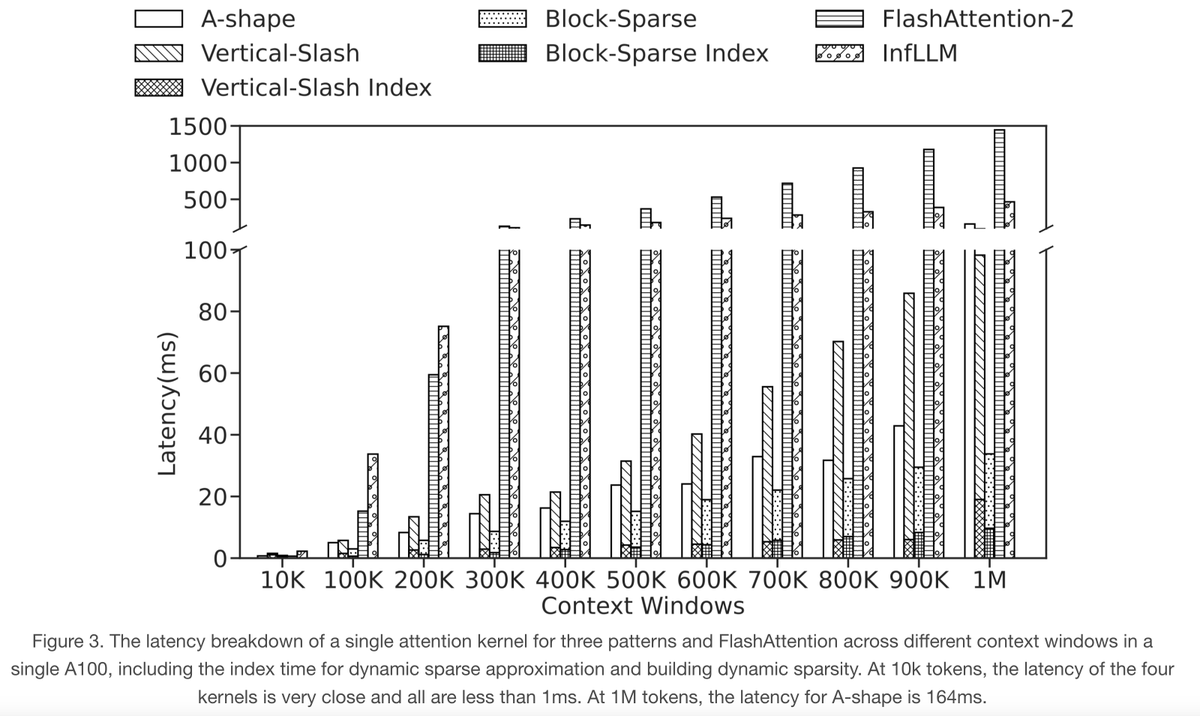
4) MInference uses dynamic compiler PIT, Triton, and Flash-Attention to effectively speed up long-context LLMs inference with minimal overhead, achieving speedups of 1.8x, 4.1x, 6.8x, and 10x at 100K, 300K, 500K, and 1M tokens, respectively.
5) The discovered sparse patterns are not just due to LLMs using RoPE but are also found in BERT Auto-Encoder, T5 Encoder-Decoder, and VLMs. We believe these sparse patterns act as information transmission channels, learned through world knowledge.

6) Now you can try to use MInference to accelerate your long-context LLMs inference!
Code: github.com/microsoft/MInf…
Code: github.com/microsoft/MInf…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



