Multiprocessing in Python clearly explained:
Ever felt like your Python code could run faster❓
Multiprocessing might be the solution you're looking for!
Today, I'll simplify it for you in this step-by-step guide.
Let's go! 🚀
Multiprocessing might be the solution you're looking for!
Today, I'll simplify it for you in this step-by-step guide.
Let's go! 🚀

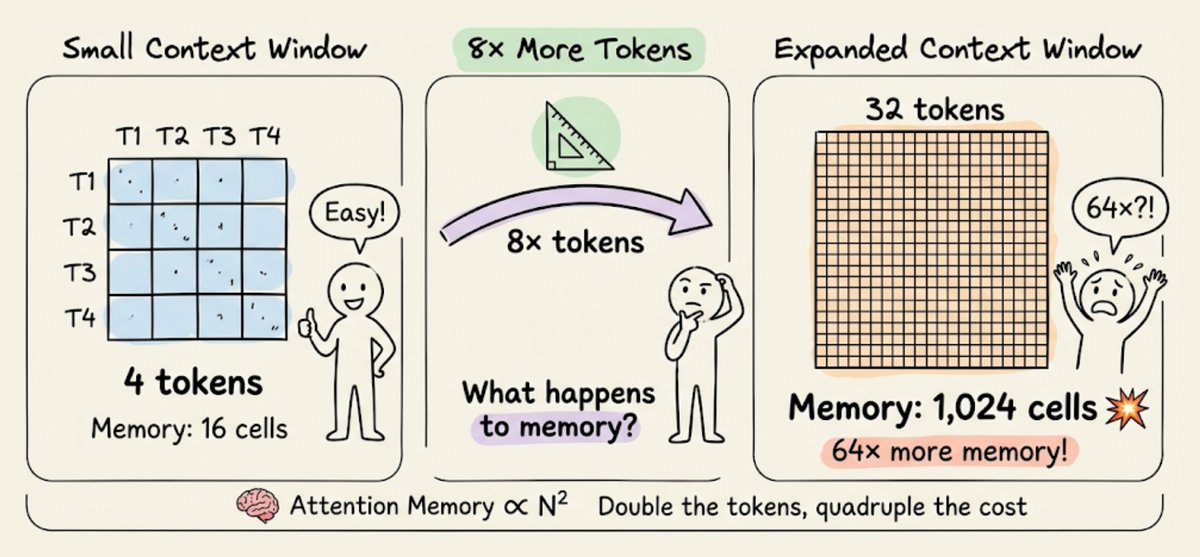
Let's start with an example where we run a simple function twice sequentially (without multiprocessing).
Check this out👇
Check this out👇
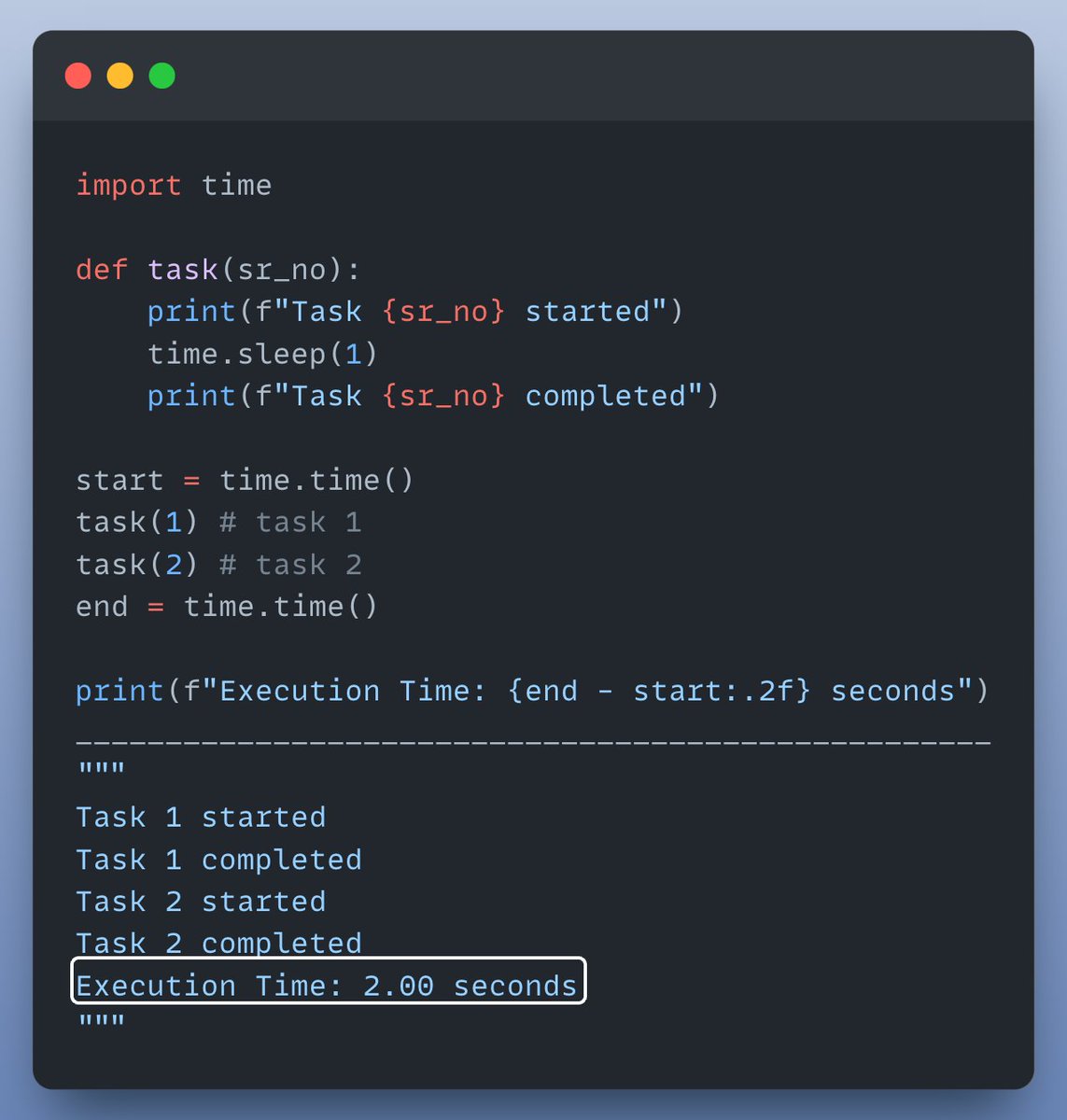
Let's visually understand what happened in the code above & how multi processing can help here.
• Sequential execution: task 2 starts only when task 1 is finished.
• Parallel execution: both tasks are performed at the same time in parallel, on separate CPU cores
Check this👇
• Sequential execution: task 2 starts only when task 1 is finished.
• Parallel execution: both tasks are performed at the same time in parallel, on separate CPU cores
Check this👇
Now that we understand the difference between sequential & parallel execution!
Let’s add multiprocessing to the mix and see the difference in execution time! ⏰
Check this out👇
Let’s add multiprocessing to the mix and see the difference in execution time! ⏰
Check this out👇

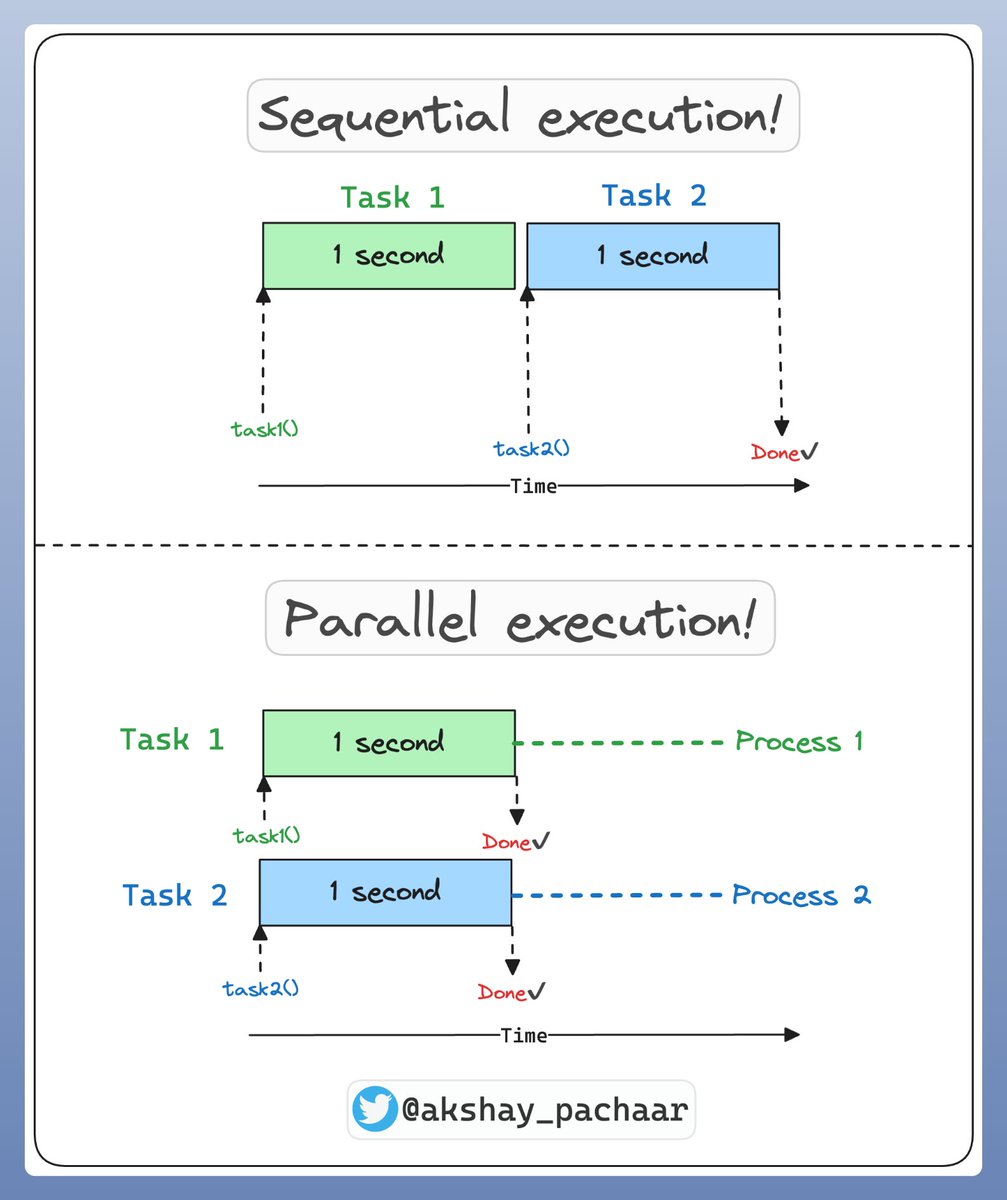
But why stop there? Let’s run our function multiple times using a for loop to see the real power of multiprocessing!
Check this out👇
Check this out👇
To make it even simpler, we can use a ProcessPool!
The recommended way to write multi-processing code in Python.
Check this out👇
The recommended way to write multi-processing code in Python.
Check this out👇
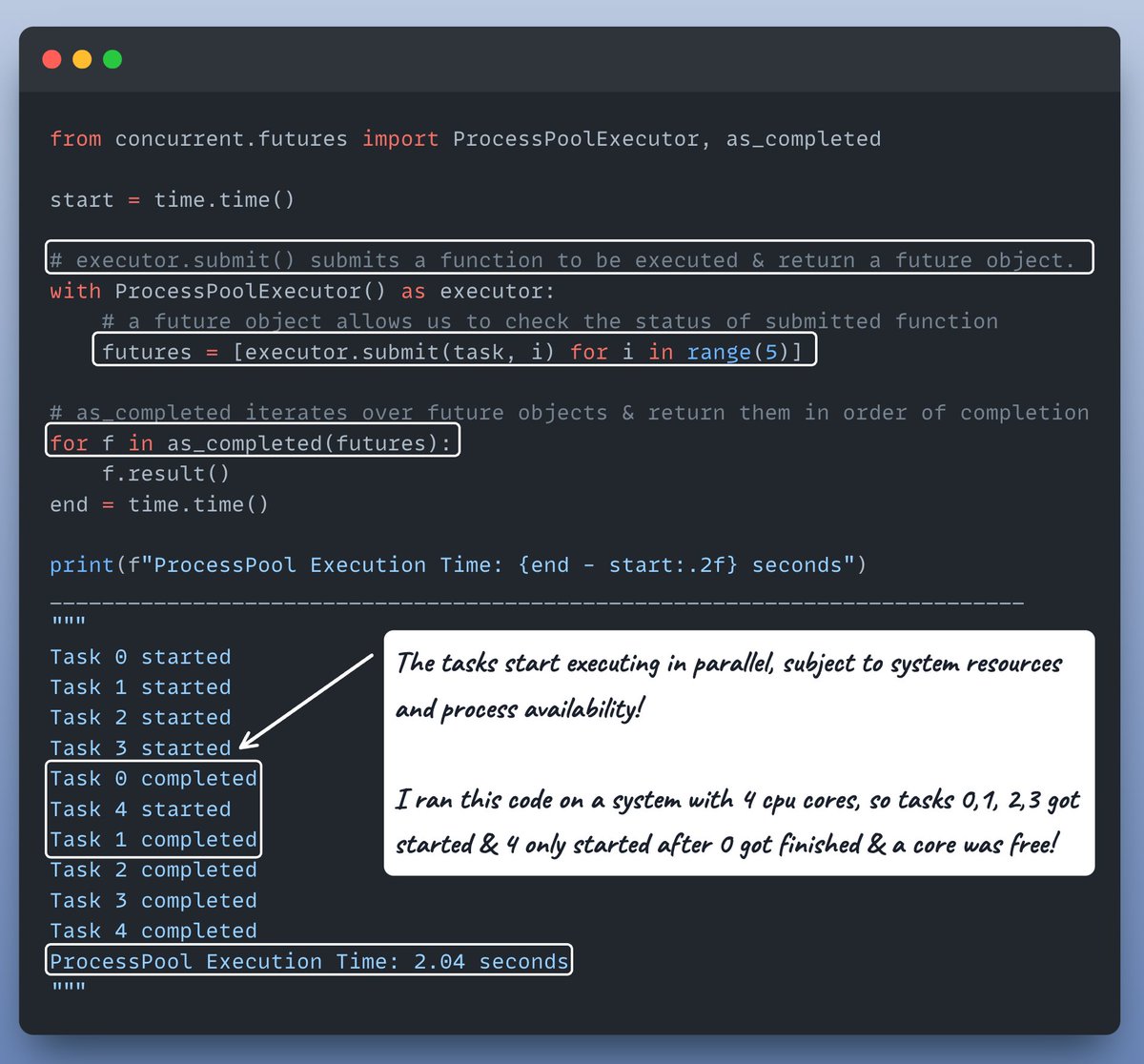
OK, last but not least let's do one more interesting thing before we wrap it up!
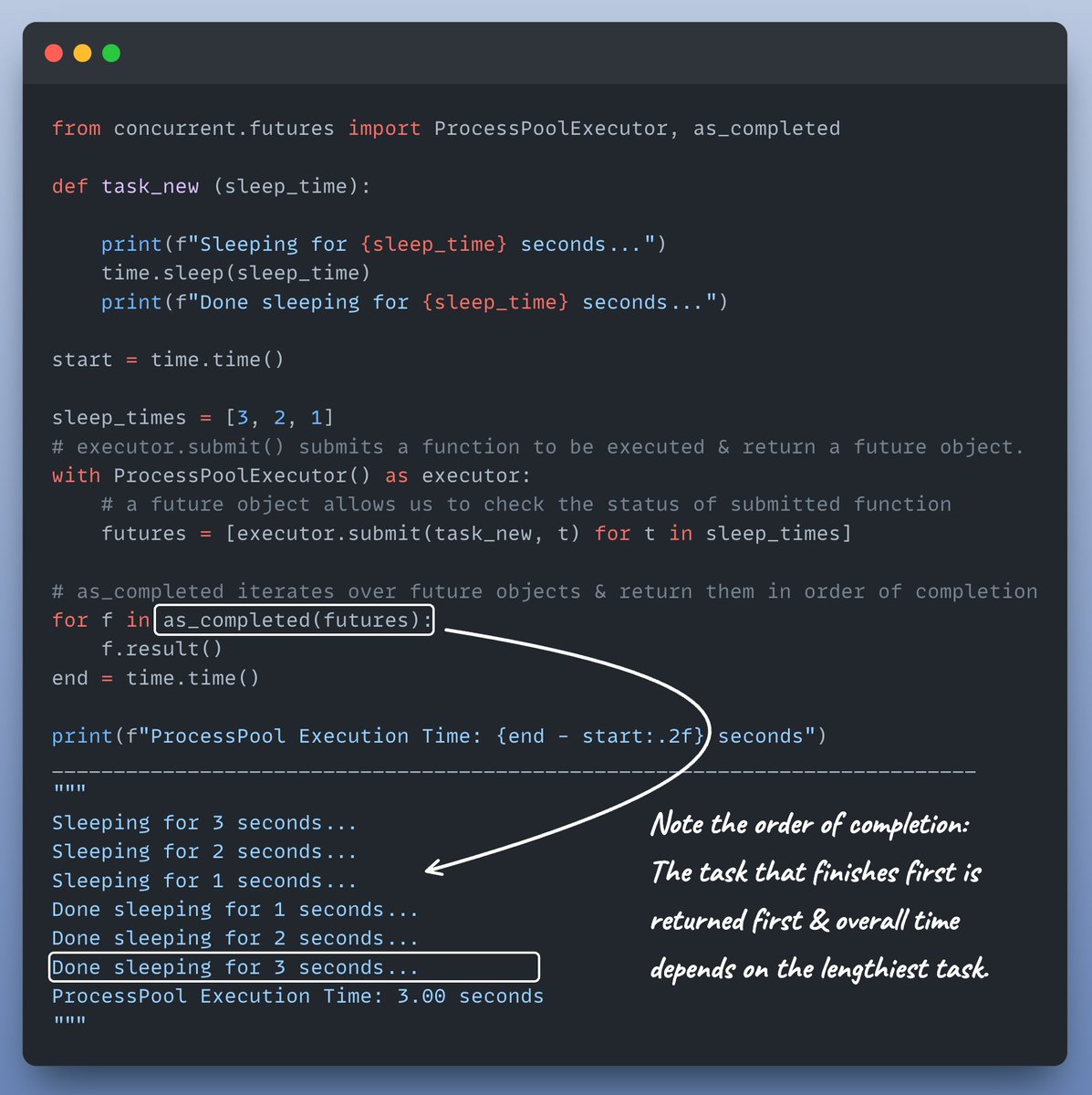
Let's modify task() to take sleep_time as an argument & observe how execution order changes.
Check this out👇
Let's modify task() to take sleep_time as an argument & observe how execution order changes.
Check this out👇
Multiprocessing is ideal for CPU-bound tasks (intensive calculations, data processing), as each process operates in its own memory space.
Where as multithreading suits I/O-bound tasks (network requests, file I/O), where threads share memory within the same process.
Where as multithreading suits I/O-bound tasks (network requests, file I/O), where threads share memory within the same process.
Interested in:
- Python 🐍
- ML/AI Engineering ⚙️
Find me → @akshay_pachaar ✔️
Enjoyed today's tutorial❓
Check out my book for more: bit.ly/InstantPython
- Python 🐍
- ML/AI Engineering ⚙️
Find me → @akshay_pachaar ✔️
Enjoyed today's tutorial❓
Check out my book for more: bit.ly/InstantPython
• • •
Missing some Tweet in this thread? You can try to
force a refresh