Exciting News from Chatbot Arena!
@GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes.
For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive score of 1300 (!), and also achieving #1 on our Vision Leaderboard.
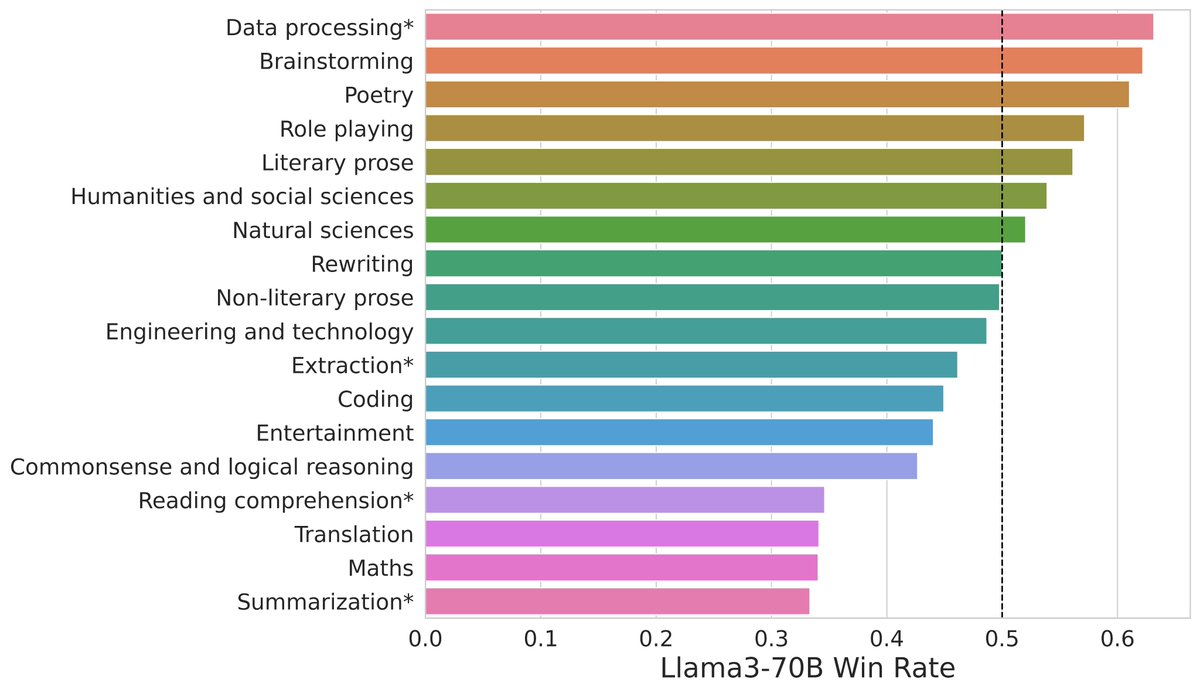
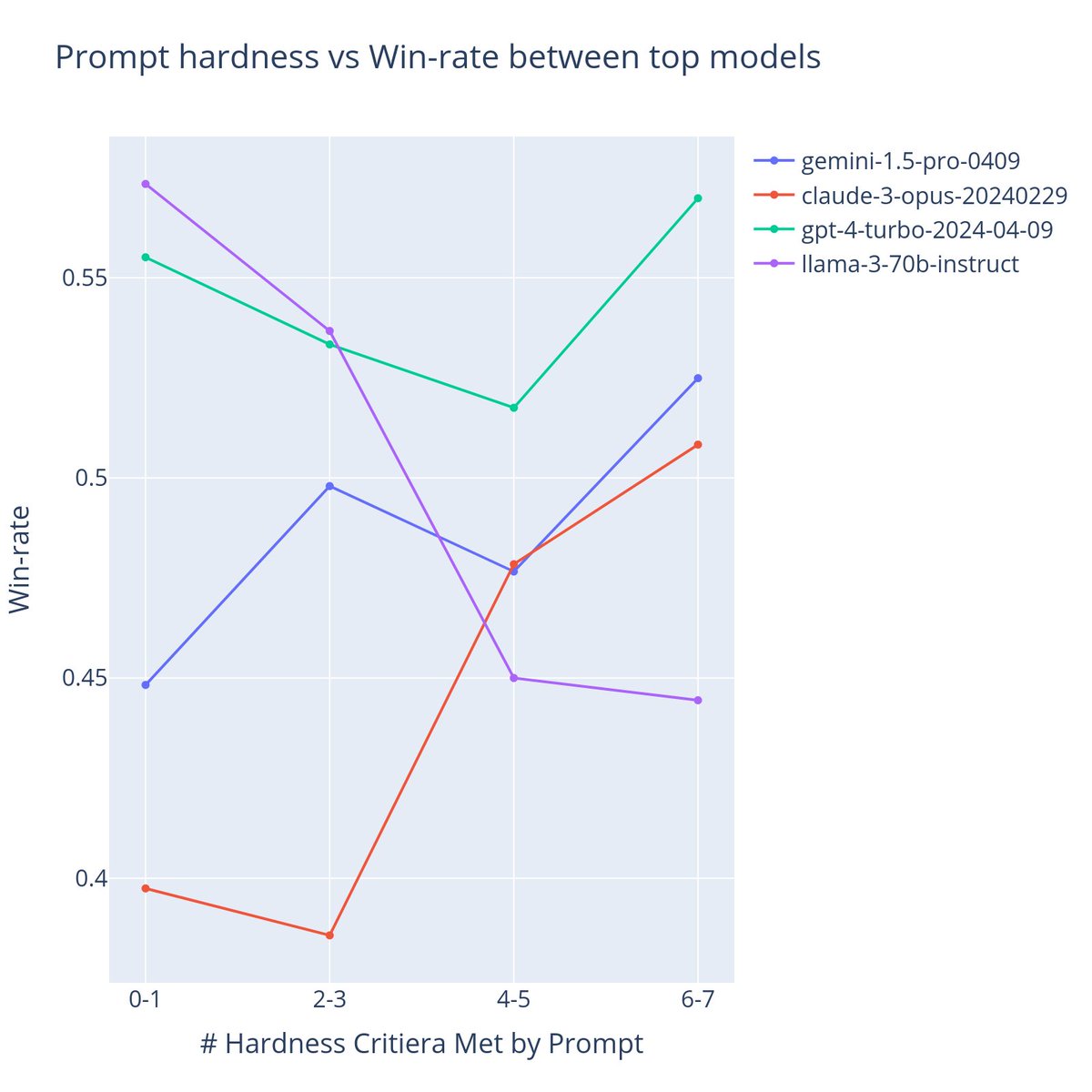
Gemini 1.5 Pro (0801) excels in multi-lingual tasks and delivers robust performance in technical areas like Math, Hard Prompts, and Coding.
Huge congrats to @GoogleDeepMind on this remarkable milestone!
Gemini (0801) Category Rankings:
- Overall: #1
- Math: #1-3
- Instruction-Following: #1-2
- Coding: #3-5
- Hard Prompts (English): #2-5
Come try the model and let us know your feedback!
More analysis below👇
@GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes.
For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive score of 1300 (!), and also achieving #1 on our Vision Leaderboard.
Gemini 1.5 Pro (0801) excels in multi-lingual tasks and delivers robust performance in technical areas like Math, Hard Prompts, and Coding.
Huge congrats to @GoogleDeepMind on this remarkable milestone!
Gemini (0801) Category Rankings:
- Overall: #1
- Math: #1-3
- Instruction-Following: #1-2
- Coding: #3-5
- Hard Prompts (English): #2-5
Come try the model and let us know your feedback!
More analysis below👇

Gemini 1.5 Pro (Experimental 0801) #1 on Vision Leaderboard.


Gemini shows strong multilingual capability: #1 performance in Chinese, Japanese, German, Russian.


But in technical domains like Coding/Hard Prompt Arena, Claude 3.5 Sonnet, GPT-4o, Llama 405B are still leading the way.


Overall win-rate heatmap: Gemini 1.5 Pro (0801) wins 54% vs GPT-4o, 59% vs Claude-3.5-Sonnet.
Check out full data at and come chat with the model! leaderboard.lmsys.org
Check out full data at and come chat with the model! leaderboard.lmsys.org

• • •
Missing some Tweet in this thread? You can try to
force a refresh