
Layer 2 blockchains are probably one of the most misunderstood topics in crypto, so let's fix that.
A guide on how L2s actually work 🧵:
A guide on how L2s actually work 🧵:

By now you probably know that L2s are Ethereum's way of scaling.
You've probably wondered why L2s are so cheap when compared to L1.
Or maybe you've asked yourself what ZK/OP proofs are.
This post will answer those questions and give you a base understanding of L2s.
You've probably wondered why L2s are so cheap when compared to L1.
Or maybe you've asked yourself what ZK/OP proofs are.
This post will answer those questions and give you a base understanding of L2s.
Let's first start by going over how Ethereum (and other L1s) work.
When a transaction is processed by a L1 chain, every node in the network must process it.
Txs are priced based on how much compute, storage, and data is used (gas usage). Compute and storage cost a lot.
When a transaction is processed by a L1 chain, every node in the network must process it.
Txs are priced based on how much compute, storage, and data is used (gas usage). Compute and storage cost a lot.

Eth txs are particularly expensive due to Eth's constraints on block sizes.
Because of this, there's a relatively small amount of compute and storage that can be done per block.
However, data is very cheap. In fact, Eth added a separate system just for data - EIP-4844 blobs.
Because of this, there's a relatively small amount of compute and storage that can be done per block.
However, data is very cheap. In fact, Eth added a separate system just for data - EIP-4844 blobs.

L2s are built on the premise of cheap data with minimized compute on the L1.
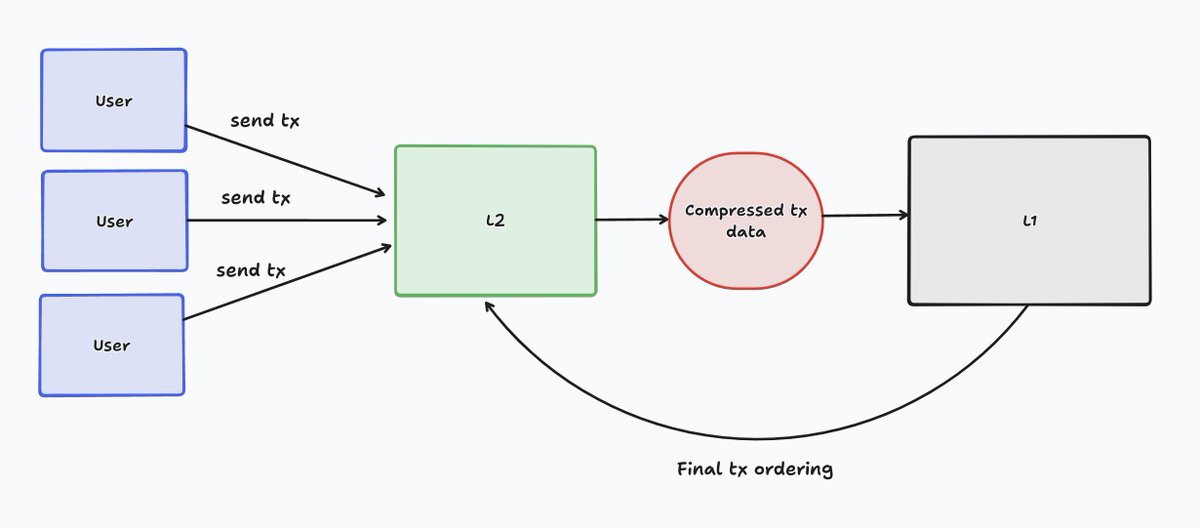
Users submit txs to the L2, where they're quickly processed and batched together. These batches are then compressed and sent as raw data to L1.
The L1 then stores this data to be used later.
Users submit txs to the L2, where they're quickly processed and batched together. These batches are then compressed and sent as raw data to L1.
The L1 then stores this data to be used later.

Notice that the L1 doesn't actually compute anything here - this is a key concept for rollups.
The L1 only stores data as blobs (not in contract "storage"), rather than processing every tx.
All the processing is done on the L2, which is cheaper/faster than the L1.
The L1 only stores data as blobs (not in contract "storage"), rather than processing every tx.
All the processing is done on the L2, which is cheaper/faster than the L1.
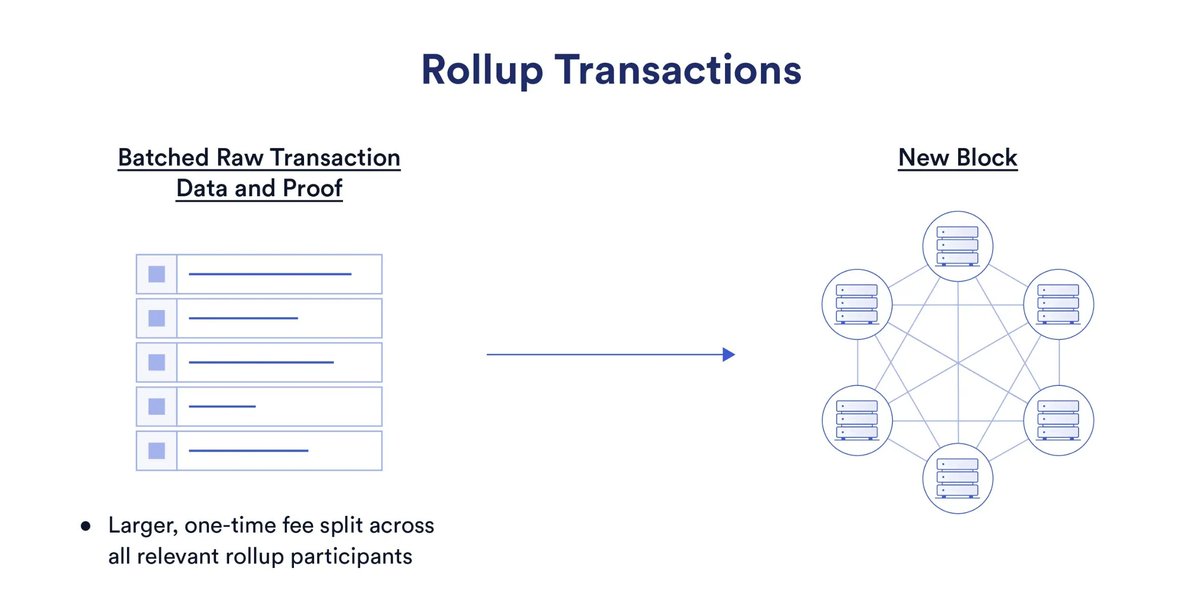
Because only data is submitted to the L1, and data is very cheap, L2s are able to scale Ethereum's tx throughput.
Depending on the type of txs being executed, L2s can theoretically process hundreds of more txs per second when compared to the L1.
This is a huge boost.
Depending on the type of txs being executed, L2s can theoretically process hundreds of more txs per second when compared to the L1.
This is a huge boost.
An important property of L2s is that they rely on the final ordering of L1 txs to derive their own final ordering.
If the L1 were to re-org L2 data batch txs, the L2 itself would re-org.
This is what we mean when we say L2s derive their state from the L1.
If the L1 were to re-org L2 data batch txs, the L2 itself would re-org.
This is what we mean when we say L2s derive their state from the L1.
So far the flow looks like this: users submit txs to the L2 -> the L2 process all of these txs -> L2 batches the txs -> L2 send compressed tx data to L1 as blobs.
But how does the L1 know that the computations on the L2 are correct? All we've done so far is send data to the L1.
But how does the L1 know that the computations on the L2 are correct? All we've done so far is send data to the L1.
This is where we get into optimistic and zero-knowledge proofs.
Optimistic (fraud) proofs use economic security while zk proofs use advanced cryptography.
Both methods of proving are used with the tx data to prove to the L1 that the results computed by the L2 are correct.
Optimistic (fraud) proofs use economic security while zk proofs use advanced cryptography.
Both methods of proving are used with the tx data to prove to the L1 that the results computed by the L2 are correct.
The L1 has a contract that tracks the state of the L2. You can think of this as the L1's viewpoint of the L2.
When a tx batch is submitted by the L2, it's telling the L1 that the L2 world has changed.
The L2 will then send a proof to prove that the state change is correct.
When a tx batch is submitted by the L2, it's telling the L1 that the L2 world has changed.
The L2 will then send a proof to prove that the state change is correct.

The proof finalizes a set of txs on the L2. Verifying proofs on the L1 is what we refer to as "settlement".
Settlement is important because it allows users to withdraw their funds from the L2 bridge.
Without proper settlement, a bad actor could steal funds from the bridge!
Settlement is important because it allows users to withdraw their funds from the L2 bridge.
Without proper settlement, a bad actor could steal funds from the bridge!
Summary so far: users submit txs to the L2 -> txs are batched and sent to the L1 -> L1 finalizes its ordering -> L2 finalizes its ordering -> L2 submits proof to the L1 to finalize state changes.
This is all theoretical, so lets walk through a simple example.
This is all theoretical, so lets walk through a simple example.

Lets say Bob swaps USDC for ETH on an L2.
This tx is sent to the L2 where it is processed quickly. At this point the tx is "soft" confirmed.
If you trust the L2 operator, you can treat this state as finalized. If you want stronger guarantees, you can wait for the L1 data batch.
This tx is sent to the L2 where it is processed quickly. At this point the tx is "soft" confirmed.
If you trust the L2 operator, you can treat this state as finalized. If you want stronger guarantees, you can wait for the L1 data batch.
The L2 then waits for more txs to come in to form a batch. The is then submitted to the L1 as part of a blob.
Once the L1 finalizes, the L2 ordering is finalized.
It's important to note that at this point, the swap tx is finalized on the L2 itself. The swap cannot be reverted.
Once the L1 finalizes, the L2 ordering is finalized.
It's important to note that at this point, the swap tx is finalized on the L2 itself. The swap cannot be reverted.
But what about settlement?
Settlement is used to finalize the L1's view of the L2, allowing for bridge withdrawals.
In our example, the L2 would submit a proof (OP or ZK) after several batches have been submitted. The proof type will determine how long it takes to finalize.
Settlement is used to finalize the L1's view of the L2, allowing for bridge withdrawals.
In our example, the L2 would submit a proof (OP or ZK) after several batches have been submitted. The proof type will determine how long it takes to finalize.

OP proofs can take up to 7 days, while ZK proofs will usually take 1 day at most.
Once the poof is verified on the L1, the L1 will update it's state of the L2.
Bob can now withdraw their new ETH from the L2 back to the L1 as a result of this settlement.
Once the poof is verified on the L1, the L1 will update it's state of the L2.
Bob can now withdraw their new ETH from the L2 back to the L1 as a result of this settlement.
Let's summarize the key points from above:
- L2s save gas costs by moving tx processing offchain, and instead submit tx data to the L1
- L2s derive their final ordering from the ordering of the L1
- L2s submit proofs to the L1 to allow funds to be withdrawn from the L2 bridge
- L2s save gas costs by moving tx processing offchain, and instead submit tx data to the L1
- L2s derive their final ordering from the ordering of the L1
- L2s submit proofs to the L1 to allow funds to be withdrawn from the L2 bridge
If you want to go a bit more depth into how L2s work, I recommend reading this post from Vitalik: .
In the future, I'll go more in depth into various rollup components.
For now, if you can understand everything above, you'll be ahead of 95% of CT ;)vitalik.eth.limo/general/2021/0…
In the future, I'll go more in depth into various rollup components.
For now, if you can understand everything above, you'll be ahead of 95% of CT ;)vitalik.eth.limo/general/2021/0…
• • •
Missing some Tweet in this thread? You can try to
force a refresh















