A story about fraud in the AI research community:
On September 5th, Matt Shumer, CEO of OthersideAI, announces to the world that they've made a breakthrough, allowing them to train a mid-size model to top-tier levels of performance. This is huge. If it's real.
It isn't.
On September 5th, Matt Shumer, CEO of OthersideAI, announces to the world that they've made a breakthrough, allowing them to train a mid-size model to top-tier levels of performance. This is huge. If it's real.
It isn't.
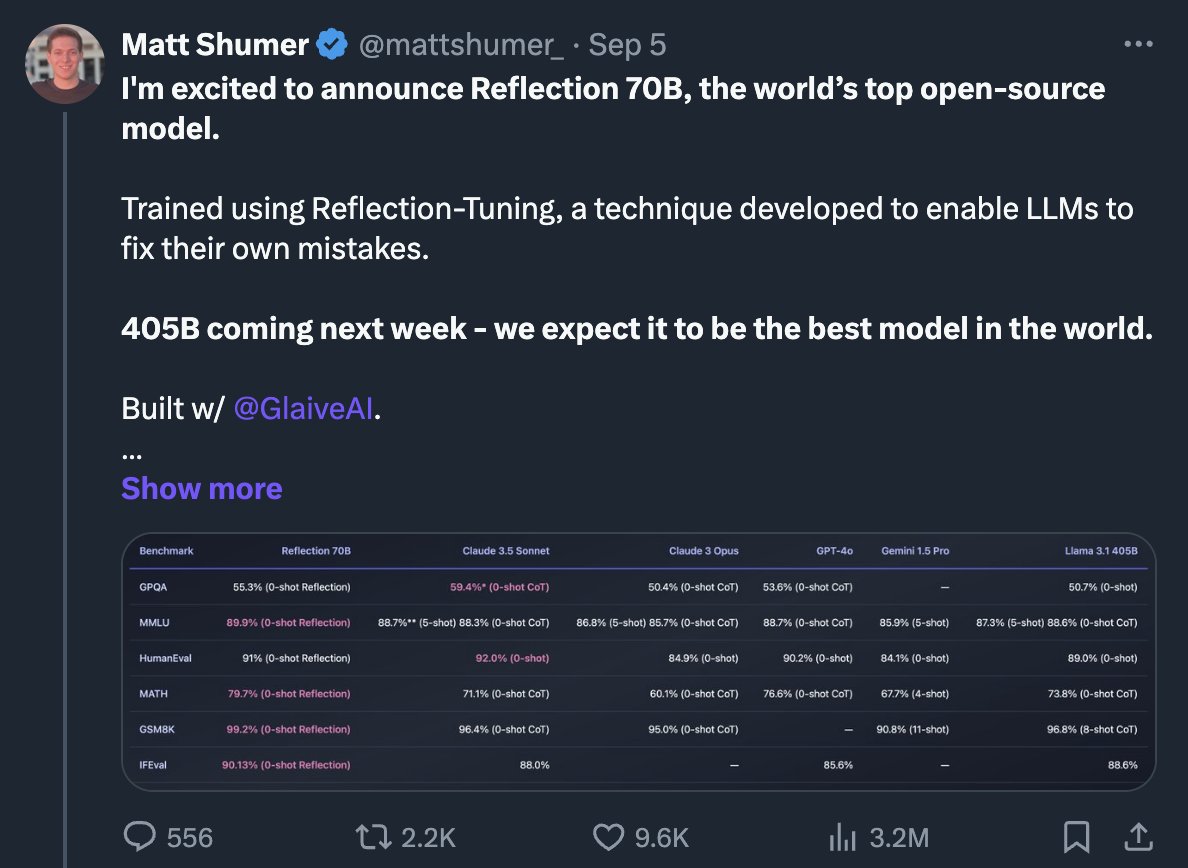
They get massive news coverage and are the talk of the town, so to speak.
*If* this were real, it would represent a substantial advance in tuning LLMs at the *abstract* level, and could perhaps even lead to whole new directions of R&D.
But soon, cracks appear in the story.
*If* this were real, it would represent a substantial advance in tuning LLMs at the *abstract* level, and could perhaps even lead to whole new directions of R&D.
But soon, cracks appear in the story.



On September 7th, the first independent attempts to replicate their claimed results fail. Miserably, actually. The performance is awful.
Further, it is discovered that Matt isn't being truthful about what the released model actually is based on under the hood.
Further, it is discovered that Matt isn't being truthful about what the released model actually is based on under the hood.



Matt starts making claims that there's something wrong with the API. There's something wrong with the upload. For *some* reason there's some glitch that's just about to be fixed.

Proof points are needed and so Matt hits back. He provides access to a secret, private API that can be used to test "his model". And it performs great! For an open source model of that size, anyway.
He even releases a publicly available endpoint for researchers to try out!
He even releases a publicly available endpoint for researchers to try out!


But the thing about a private API is it's not really clear what it's calling on the backend. They could be calling a more powerful proprietary model under the hood. We should test and see. Trust, but verify.
And it turns out that Matt is a liar.
And it turns out that Matt is a liar.

Their API was a Claude wrapper with a system prompt to make it act similar to the open source model.
Amusingly, they appear to be redeploying their private API in response to distinctive tells sneaking through, playing whack-a-mole to try to not get found out.
Amusingly, they appear to be redeploying their private API in response to distinctive tells sneaking through, playing whack-a-mole to try to not get found out.




tl;dr
Matt Shumer is a liar and a fraud. Presumably he'll eventually throw some poor sap engineer under the bus and pretend he was lied to.
Grifters shit in the communal pool, sucking capital, attention, and other resources away from people who could actually make use of them.
Matt Shumer is a liar and a fraud. Presumably he'll eventually throw some poor sap engineer under the bus and pretend he was lied to.
Grifters shit in the communal pool, sucking capital, attention, and other resources away from people who could actually make use of them.

check out mythbuster extrordinaire @RealJosephus's great thread on this
https://x.com/RealJosephus/status/1832904398831280448
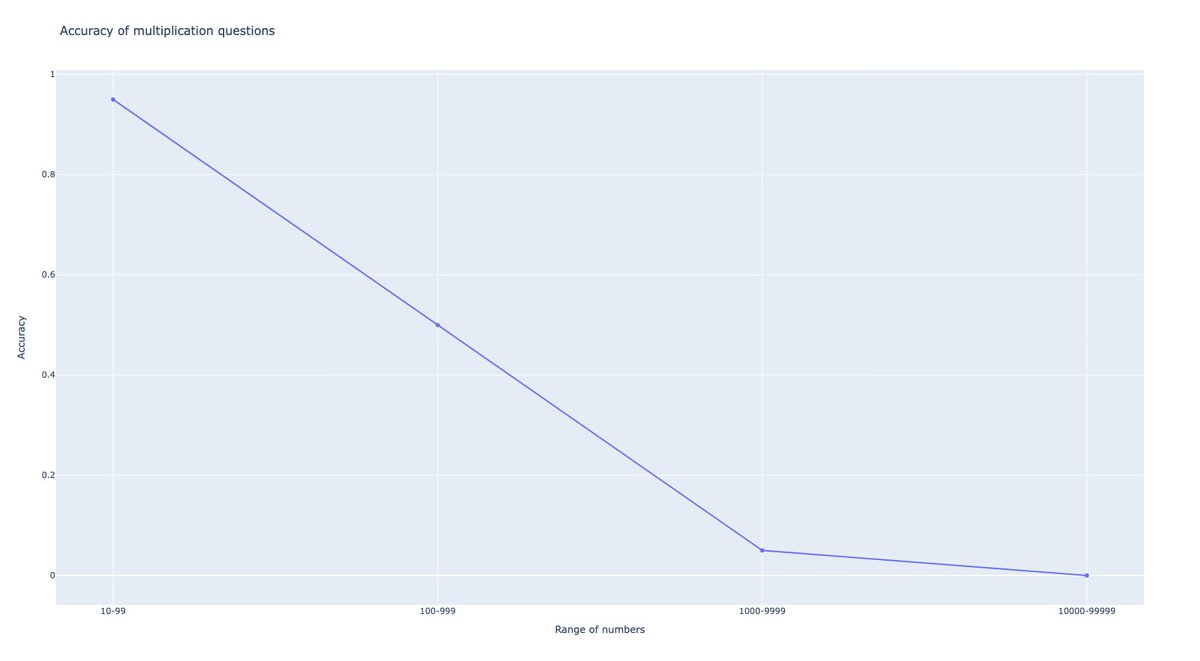
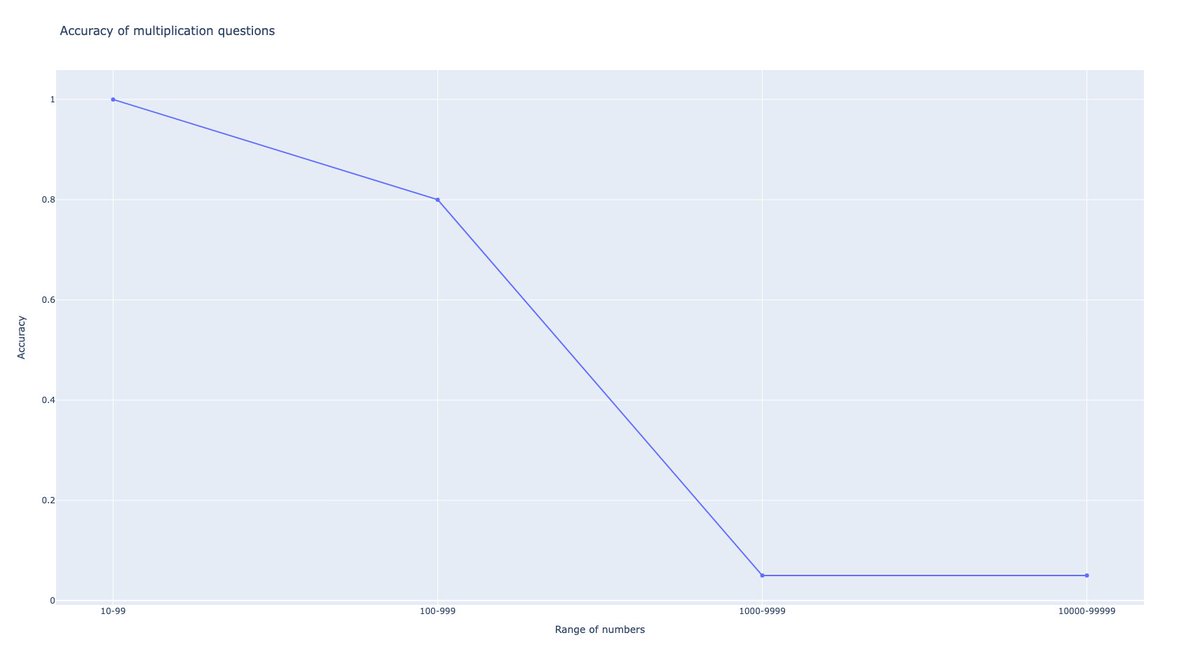
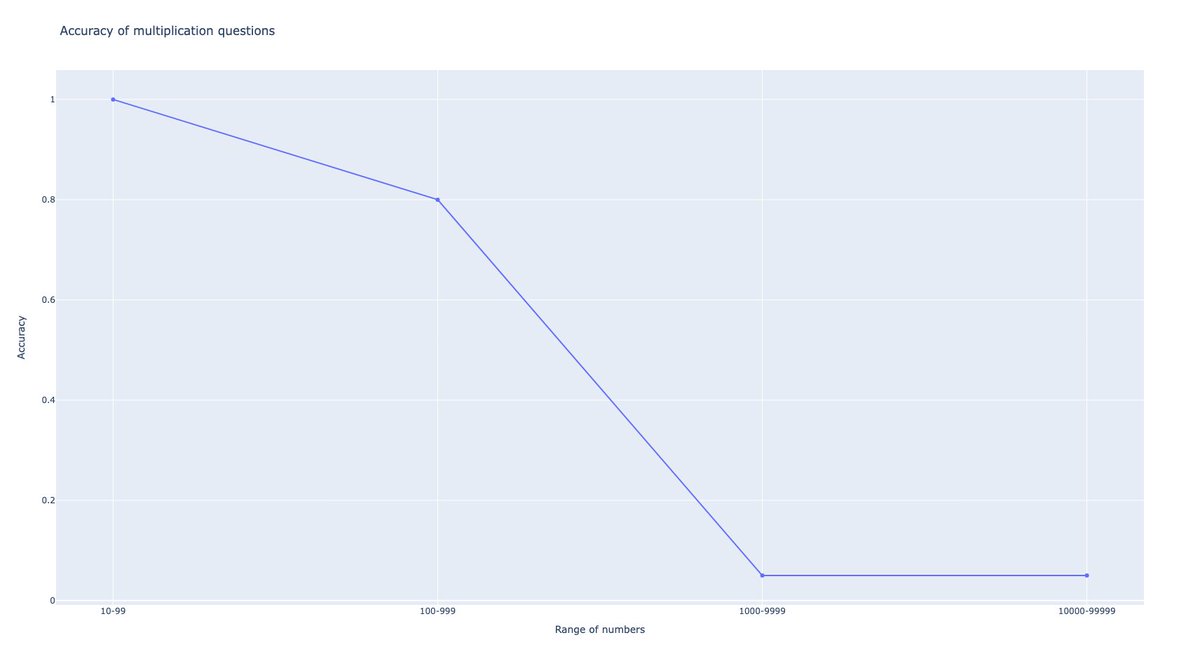
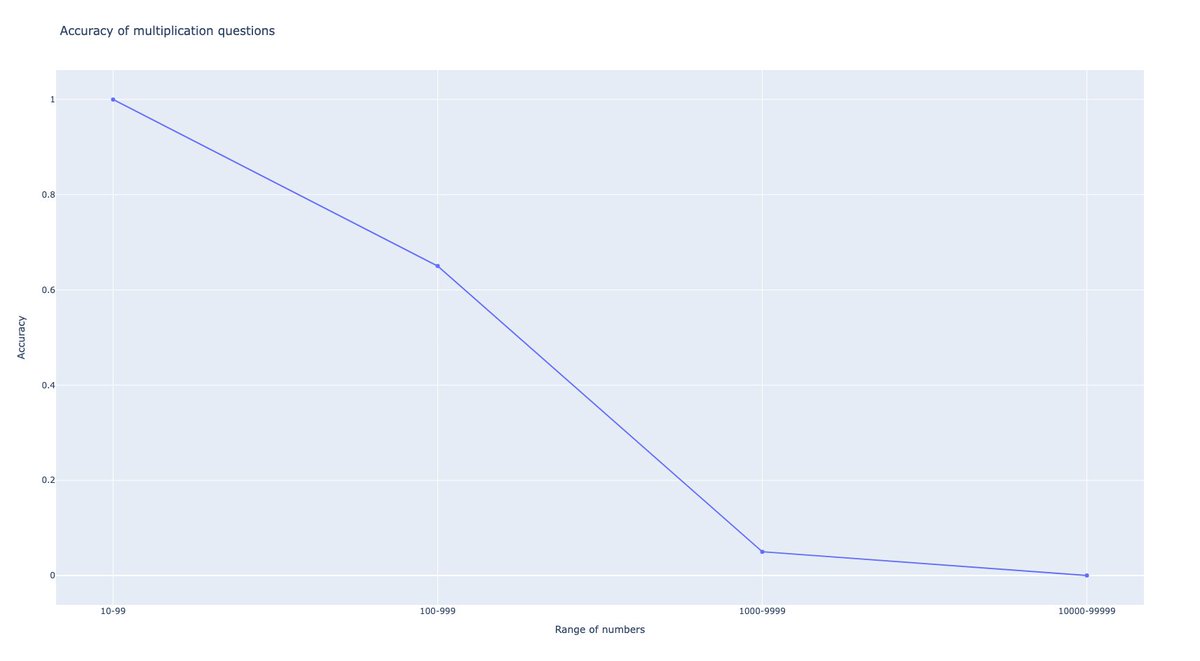
@RealJosephus Since some people are saying this is premature and they want to wait for data and replications, I grabbed an API key, added support for OpenRouter to my eval script, and compared Reflection 70B to other leading models on an *unseen* test set.
The results were bad.
The results were bad.


@RealJosephus The test set was an algorithmically generated set of 200 multiple choice puzzles. They're unique every time they're generated so they can't be cheesed. There's no way to perform well on this test except intelligence.


@RealJosephus Since I don't have a substack to promote instead I'll share a preview of my next effortpost. You *can* actually get SOTA on unseen benchmarks ... if you are willing to be more liberal about what constitutes a "model". Hybrid systems here are any amalgam of models and code.
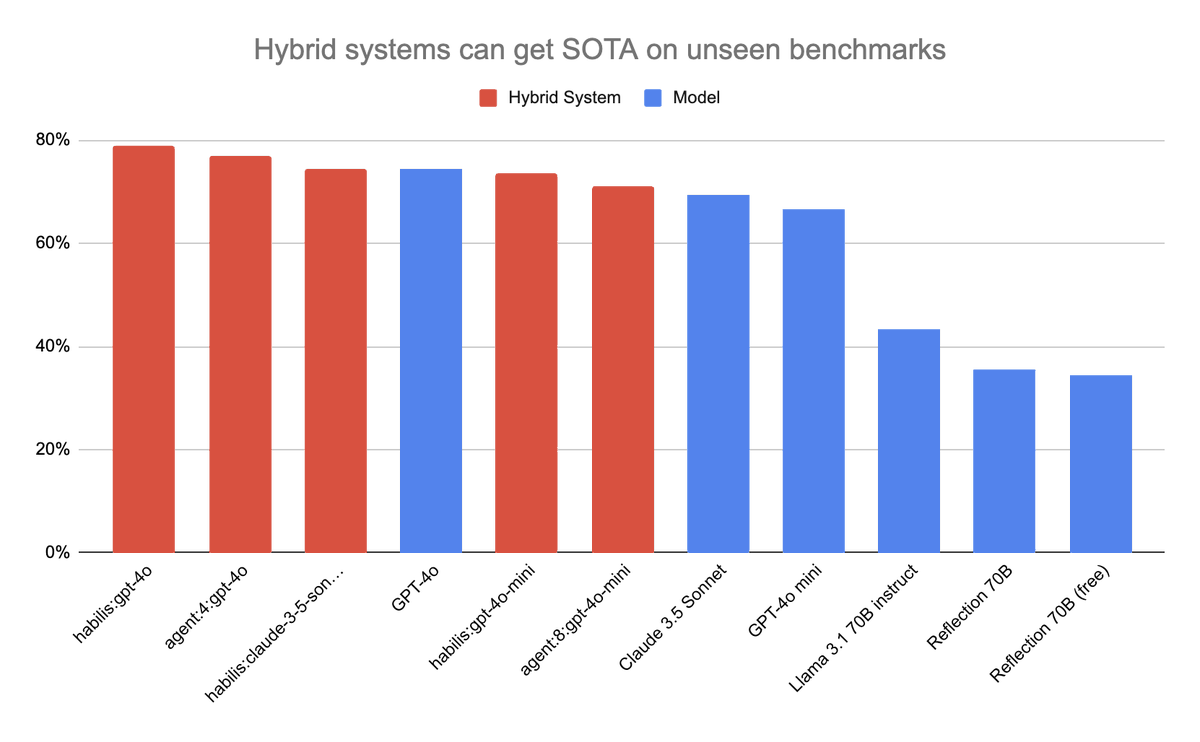
@immanencer toy example but I think sort of instructive
@ikristoph @RealJosephus lmao what this is a one time service
@ikristoph @RealJosephus okay let me find another solution
@ikristoph @RealJosephus that part doesn't especially matter though unless you want to get the exact same results
@romechenko the bet is not that he gets found out but that nobody cares what the nerds think
@Hackthestack777 (in my experience, I should say)
@3v333333 @DotCSV or, if it's claude, the current prompt has lobotomized it
@nisten At this point I suspect you're being willfully obtuse.
@RichardYannow @RealJosephus Now go do something useful and leave me alone.
@scholarc1314 but it's not a big lift overall. marginal. most effective at improving weaker models ime.
• • •
Missing some Tweet in this thread? You can try to
force a refresh