
Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas?
After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.
After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.

In our new paper:
We recruited 49 expert NLP researchers to write novel ideas on 7 NLP topics.
We built an LLM agent to generate research ideas on the same 7 topics.
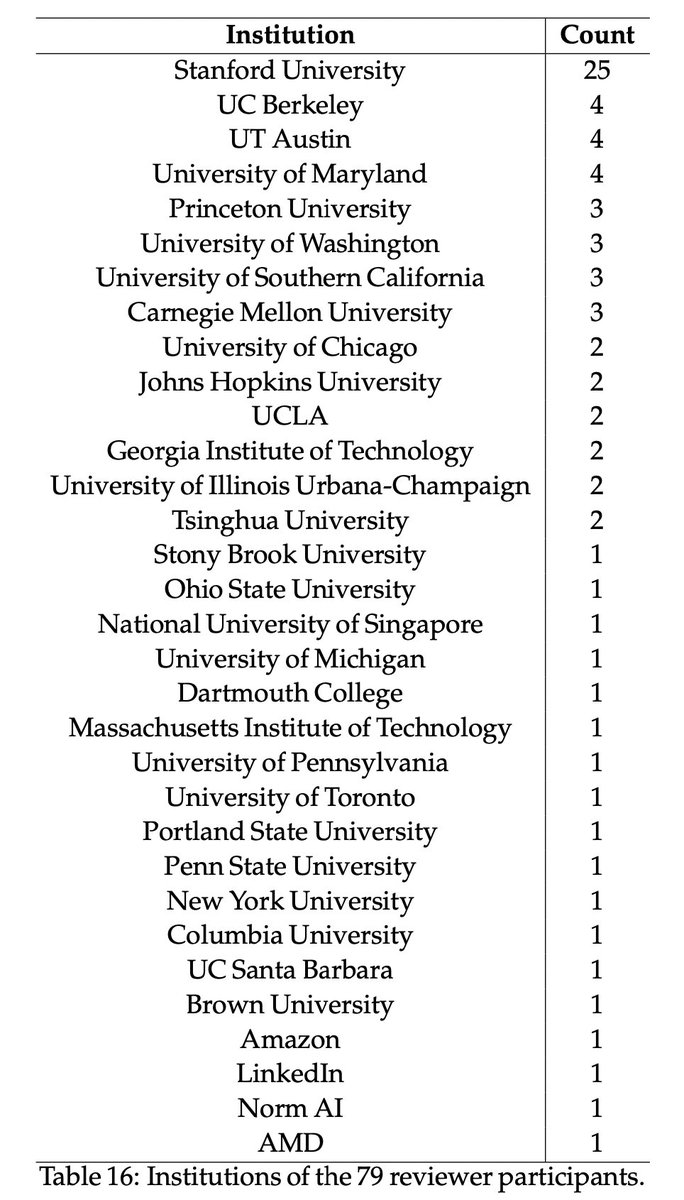
After that, we recruited 79 experts to blindly review all the human and LLM ideas.
2/ arxiv.org/abs/2409.04109
We recruited 49 expert NLP researchers to write novel ideas on 7 NLP topics.
We built an LLM agent to generate research ideas on the same 7 topics.
After that, we recruited 79 experts to blindly review all the human and LLM ideas.
2/ arxiv.org/abs/2409.04109

When we say “experts”, we really do mean some of the best people in the field.
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, our idea writers have a median citation count of 125, and our reviewers have 327.
3/
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, our idea writers have a median citation count of 125, and our reviewers have 327.
3/


We specify a very detailed idea template to make sure both human and LLM ideas cover all the necessary details to the extent that a student can easily follow and execute all the steps.
We paid $300 for each idea, plus a $1000 bonus to the top 5 human ideas.
4/
We paid $300 for each idea, plus a $1000 bonus to the top 5 human ideas.
4/

We also used an LLM to standardize the writing styles of human and LLM ideas to avoid potential confounders, while preserving the original content.
Shown below is a randomly selected LLM-generated idea, as an example of how our ideas look like.
5/
Shown below is a randomly selected LLM-generated idea, as an example of how our ideas look like.
5/



Our 79 expert reviewers submitted 298 reviews in total, so each idea got 2-4 independent reviews.
Our review form is inspired by ICLR & ACL, with breakdown scores + rationales on novelty, excitement, feasibility, and expected effectiveness, apart from the overall score.
6/
Our review form is inspired by ICLR & ACL, with breakdown scores + rationales on novelty, excitement, feasibility, and expected effectiveness, apart from the overall score.
6/

With these high-quality human ideas and reviews, we compare the results.
We performed 3 different statistical tests accounting for all the possible confounders we could think of.
It holds robustly that LLM ideas are rated as significantly more novel than human expert ideas.
7/
We performed 3 different statistical tests accounting for all the possible confounders we could think of.
It holds robustly that LLM ideas are rated as significantly more novel than human expert ideas.
7/
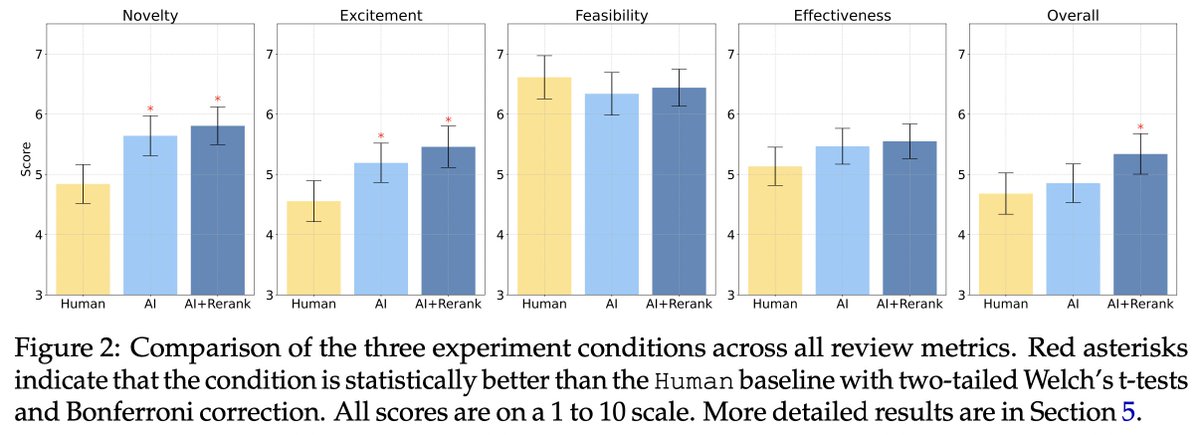

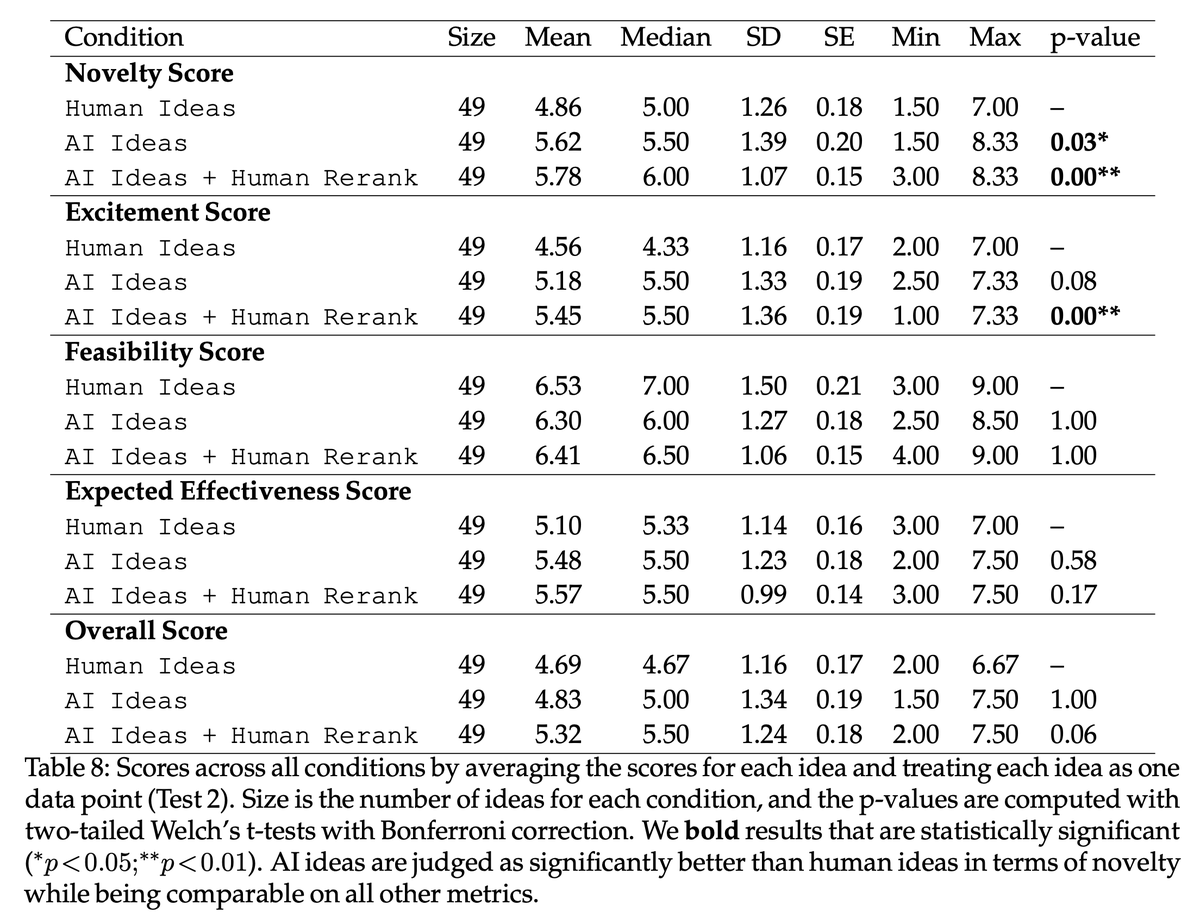

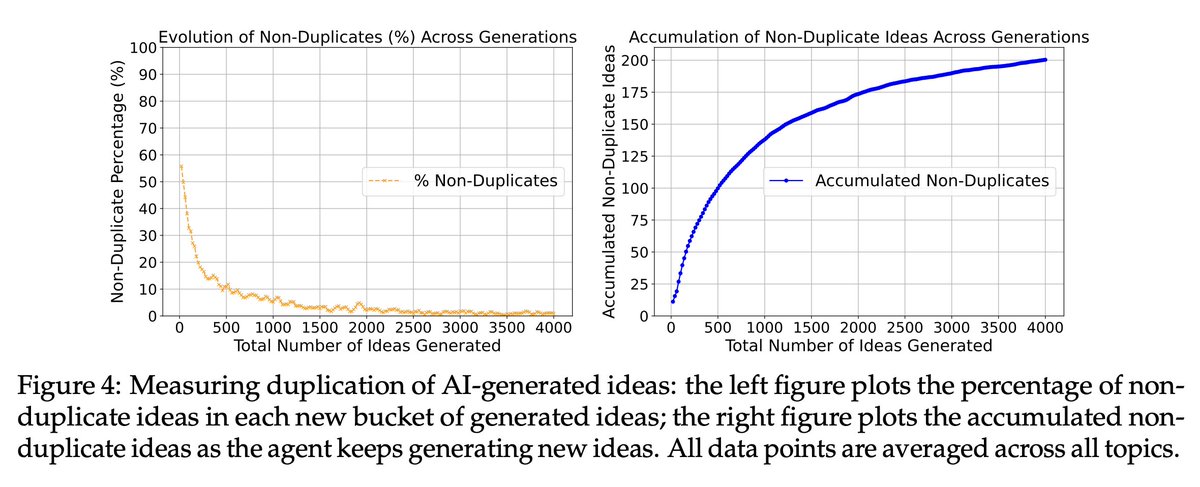
Apart from the human-expert comparison, I’ll also highlight two interesting analyses of LLMs:
First, we find LLMs lack diversity in idea generation. They quickly start repeating previously generated ideas even though we explicitly told them not to.
8/
First, we find LLMs lack diversity in idea generation. They quickly start repeating previously generated ideas even though we explicitly told them not to.
8/
Second, LLMs cannot evaluate ideas reliably yet. When we benchmarked previous automatic LLM reviewers against human expert reviewers using our ideas and reviewer scores, we found that all LLM reviewers showed a low agreement with human judgments.
9/
9/

We include many more quantitative and qualitative analyses in the paper, including examples of human and LLM ideas with the corresponding expert reviews, a summary of experts’ free-text reviews, and our thoughts on how to make progress in this emerging research direction.
10/
10/
For the next step, we are recruiting more expert participants for the second phase of our study, where experts will implement AI and human ideas into full projects for a more reliable evaluation based on real research outcomes.
Sign-up link:
11/tinyurl.com/execution-study
Sign-up link:
11/tinyurl.com/execution-study
This project wouldn't have been possible without our amazing participants who wrote and reviewed ideas. We can't name them publicly yet as more experiments are ongoing and we need to preserve anonymity. But I want to thank you all for your tremendous support!! 🙇♂️🙇♂️🙇♂️
12/
12/
Also shout out to many friends who offered me helpful advice and mental support, esp. @rose_e_wang @dorazhao9 @aryaman2020 @irena_gao @kenziyuliu @harshitj__ @IsabelOGallegos @ihsgnef @gaotianyu1350 @xinranz3 @xiye_nlp @YangjunR @neilbband @mertyuksekgonul @JihyeonJe ❤️❤️❤️
13/
13/
Finally I want to thank my supportive, energetic, insightful, and fun advisors @tatsu_hashimoto @Diyi_Yang 💯💯💯
Thank you for teaching me how to do the most exciting research in the most rigorous way, and letting me spend so much time and $$$ on this crazy project!
14/14
Thank you for teaching me how to do the most exciting research in the most rigorous way, and letting me spend so much time and $$$ on this crazy project!
14/14
• • •
Missing some Tweet in this thread? You can try to
force a refresh



