
This is the best #RAG stack, according to a fantastic study currently in review (by Wang et al., 2024) (it's a gold mine!).
Here are the best components of each part of the system and how they work… 👇
Here are the best components of each part of the system and how they work… 👇
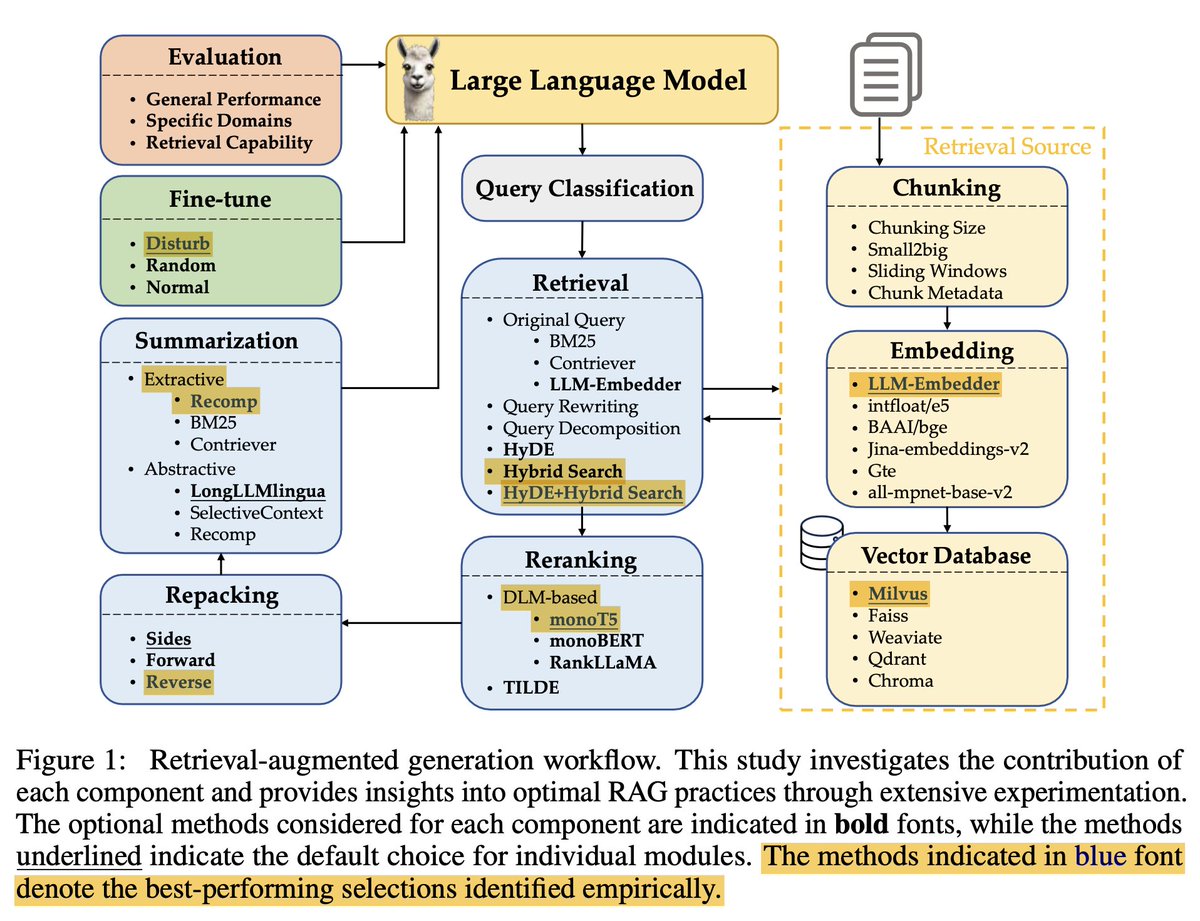
First is Query Classification. Not all queries are equal. Some queries don't need retrieval as the LLM already has the knowledge (e.g. Who is Messi?)
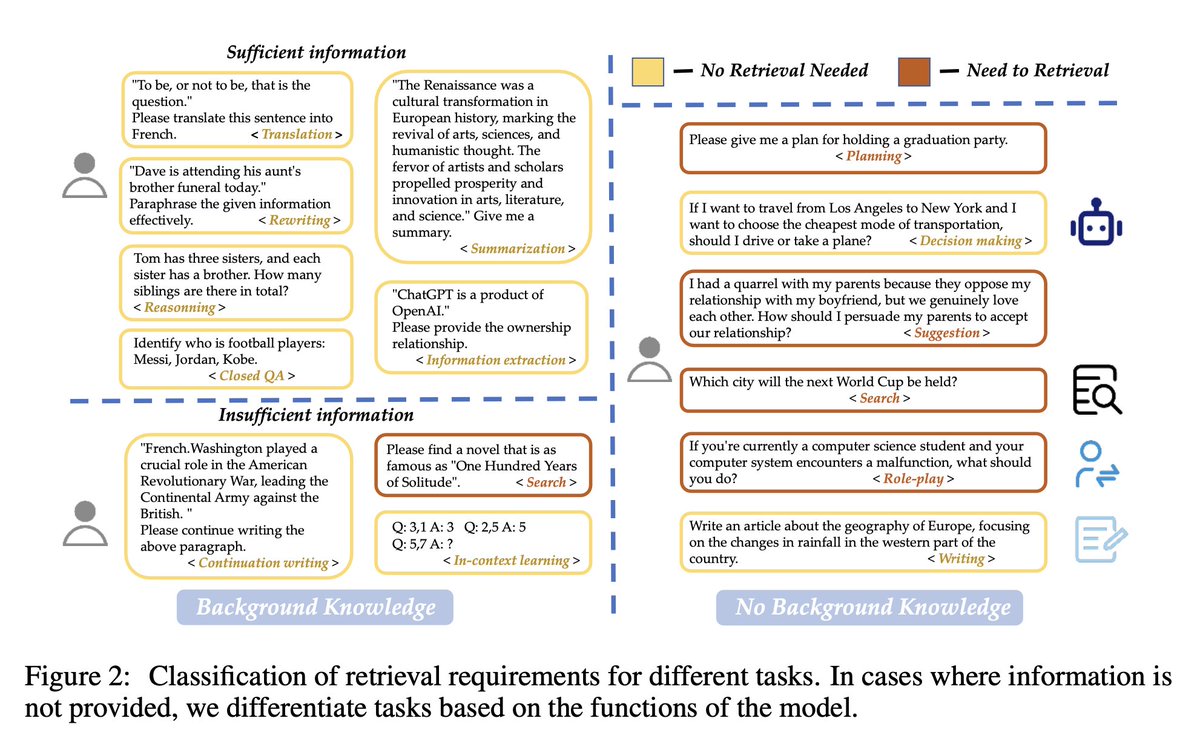
They created 15 task categories based on whether they provided sufficient information (See image).
They then train a binary classifier for tasks based on user-given information, termed “sufficient” (yellow), which need not retrieval, and “insufficient” (red), where retrieval may be necessary.
They created 15 task categories based on whether they provided sufficient information (See image).
They then train a binary classifier for tasks based on user-given information, termed “sufficient” (yellow), which need not retrieval, and “insufficient” (red), where retrieval may be necessary.
Next is chunking your data—the old chunking challenge: not too small, not too large. You need the optimal context amount.
The size significantly impacts performance...
Too long adds context but increases costs and adds noise.
Too short is efficient, improves retrieval recall and is cheap but may lack relevant information.
The optimal chunk size involves balancing metrics like faithfulness and relevancy. Faithfulness measures if the response is hallucinated or, in other words, whether it matches the retrieved texts, whereas relevancy measures if the retrieved texts and responses match queries.
Between 256 and 512 is best in their study, but it depends on your data. Run evals!
small2big (have small chunks for search, then use large chunks that include the smaller one for generation) and sliding windows (overlap tokens between chunks) help.
The size significantly impacts performance...
Too long adds context but increases costs and adds noise.
Too short is efficient, improves retrieval recall and is cheap but may lack relevant information.
The optimal chunk size involves balancing metrics like faithfulness and relevancy. Faithfulness measures if the response is hallucinated or, in other words, whether it matches the retrieved texts, whereas relevancy measures if the retrieved texts and responses match queries.
Between 256 and 512 is best in their study, but it depends on your data. Run evals!
small2big (have small chunks for search, then use large chunks that include the smaller one for generation) and sliding windows (overlap tokens between chunks) help.

Use metadata and hybrid search.
Enhancing chunk blocks with metadata like titles, keywords, and hypothetical questions will help in lots of cases.
Hybrid search combines vector search (original embedding) with traditional keyword search (BM25), enhancing retrieval accuracy. HyDE (generate pseudo-documents from original queries to enhance retrieval) helps, but is incredibly inefficient. Using just Hybrid search is better ATM.
Enhancing chunk blocks with metadata like titles, keywords, and hypothetical questions will help in lots of cases.
Hybrid search combines vector search (original embedding) with traditional keyword search (BM25), enhancing retrieval accuracy. HyDE (generate pseudo-documents from original queries to enhance retrieval) helps, but is incredibly inefficient. Using just Hybrid search is better ATM.
The Embedding model. Which one? To fine-tune or not?
They work with open-source models here. LLM-Embedder was best for its balance of performance and size:
Just note that they only tested open-source models, so Cohere and OpenAI were out of the game. Cohere is probably your best bet otherwise.github.com/FlagOpen/FlagE…
They work with open-source models here. LLM-Embedder was best for its balance of performance and size:
Just note that they only tested open-source models, so Cohere and OpenAI were out of the game. Cohere is probably your best bet otherwise.github.com/FlagOpen/FlagE…
Vector Database - which one?
Milvus seems ideal (between open-source ones) for long-term use.
milvus.io
Milvus seems ideal (between open-source ones) for long-term use.
milvus.io

Transform the user queries!
Use query rewriting (prompt an LLM to rewrite queries mostly for clarity).
Use query decomposition (complex questions into smaller sub-questions and retrieve for each).
(for best results) Use pseudo-documents generation (e.g. HyDE, generate a hypothetical document from the query and use that instead), which adds latency.
Use query rewriting (prompt an LLM to rewrite queries mostly for clarity).
Use query decomposition (complex questions into smaller sub-questions and retrieve for each).
(for best results) Use pseudo-documents generation (e.g. HyDE, generate a hypothetical document from the query and use that instead), which adds latency.
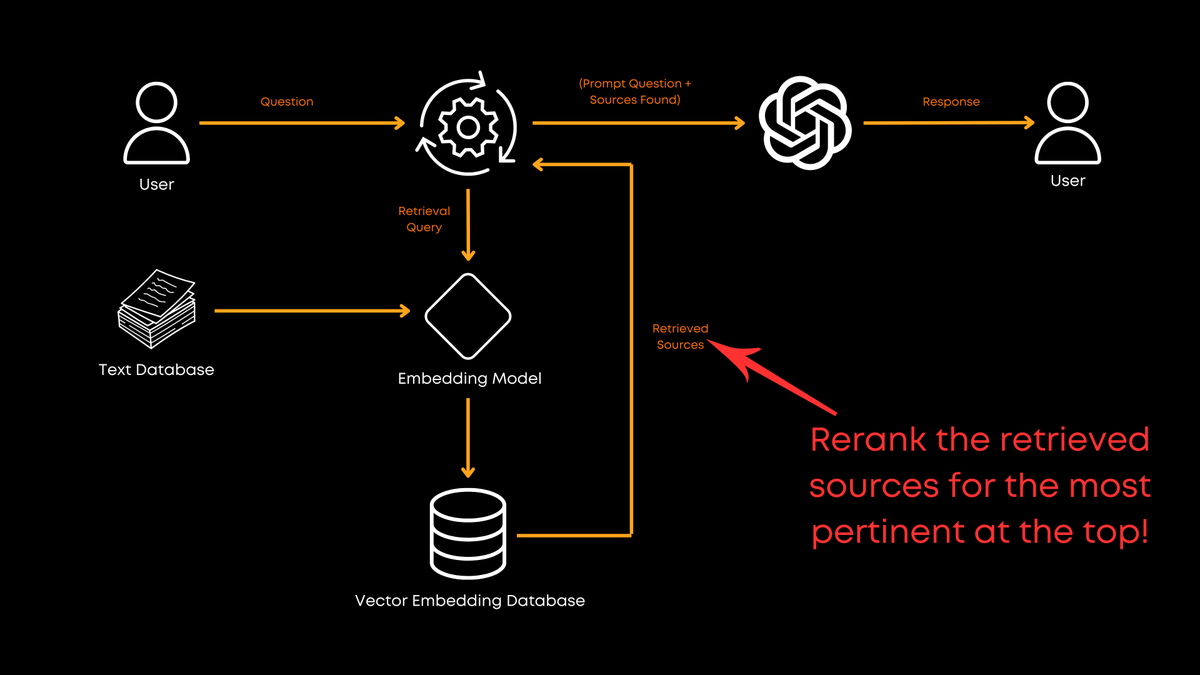
Use reranking!
Retrieve K documents and rerank them- it helps a lot.
Ensures that the most pertinent information appears at the top of the list.
(DLM-based, which utilizes classification True/False relevancy) monoT5 is best for balancing performance and efficiency. It fine-tunes the T5 model to reorder retrieved documents by evaluating how well the sequence of words in each document matches the query, ensuring the most relevant results appear first.
RankLLaMA has the best performance.
TILDEv2 is the quickest.
Retrieve K documents and rerank them- it helps a lot.
Ensures that the most pertinent information appears at the top of the list.
(DLM-based, which utilizes classification True/False relevancy) monoT5 is best for balancing performance and efficiency. It fine-tunes the T5 model to reorder retrieved documents by evaluating how well the sequence of words in each document matches the query, ensuring the most relevant results appear first.
RankLLaMA has the best performance.
TILDEv2 is the quickest.
Document Repacking
This happens AFTER reranking.
Use “reverse” repacking, which arranges them in ascending order—inspired by Liu et al. (, amazing paper!), who found that optimal performance is achieved when relevant information is positioned at the start or end of the input. Repacking optimizes how the information is presented to the LLM for generationarxiv.org/abs/2307.03172
This happens AFTER reranking.
Use “reverse” repacking, which arranges them in ascending order—inspired by Liu et al. (, amazing paper!), who found that optimal performance is achieved when relevant information is positioned at the start or end of the input. Repacking optimizes how the information is presented to the LLM for generationarxiv.org/abs/2307.03172
Use summarization to avoid redundant, or unnecessary information and reduce costs (long inputs sent to the LLM).
Doing Recomp () is best. It has extractive (selects useful sentences) and abstractive (synthesizes information from multiple documents) compressors, providing the best of both worlds.
*In time-sensitive applications, removing summarization could effectively reduce response time.github.com/carriex/recomp
Doing Recomp () is best. It has extractive (selects useful sentences) and abstractive (synthesizes information from multiple documents) compressors, providing the best of both worlds.
*In time-sensitive applications, removing summarization could effectively reduce response time.github.com/carriex/recomp
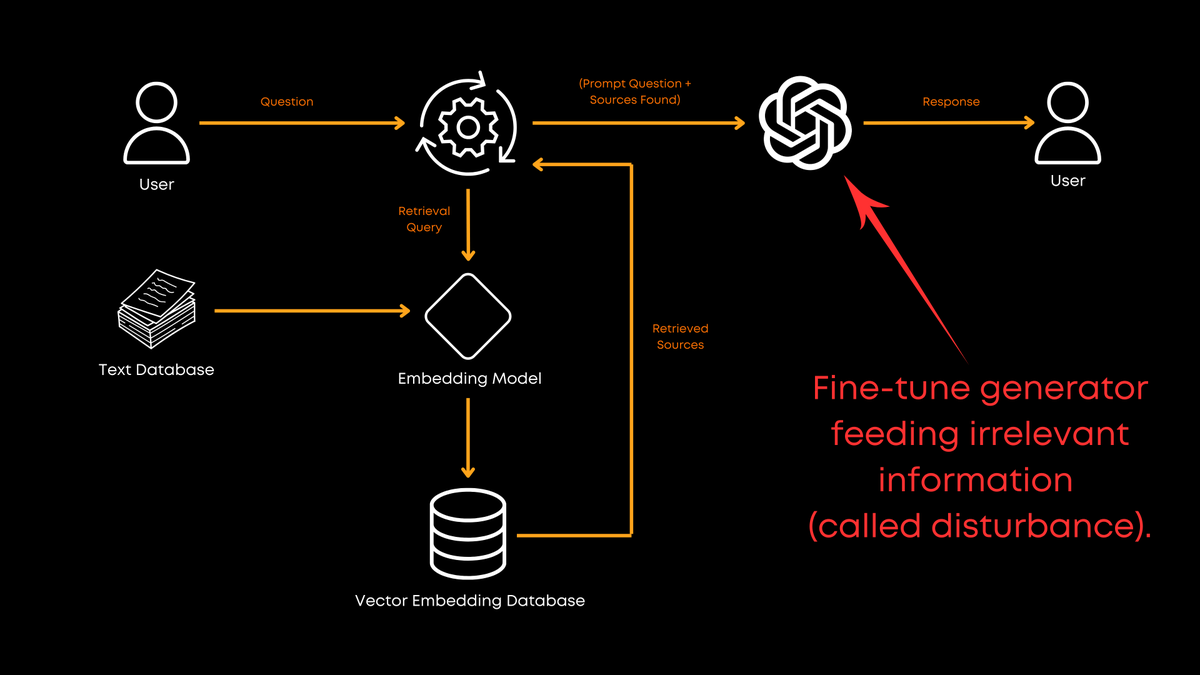
If you can, fine-tuning the generator is worthwhile.
They experimented with various combinations of relevant and random documents (assuming 1:1(?), no ratio provided in the paper) to see how this affects the generator's output quality.
Augmenting with relevant and randomly-selected documents (Disturb) during fine-tuning enhanced the generator’s robustness to irrelevant information while effectively utilizing relevant contexts.
They experimented with various combinations of relevant and random documents (assuming 1:1(?), no ratio provided in the paper) to see how this affects the generator's output quality.
Augmenting with relevant and randomly-selected documents (Disturb) during fine-tuning enhanced the generator’s robustness to irrelevant information while effectively utilizing relevant contexts.
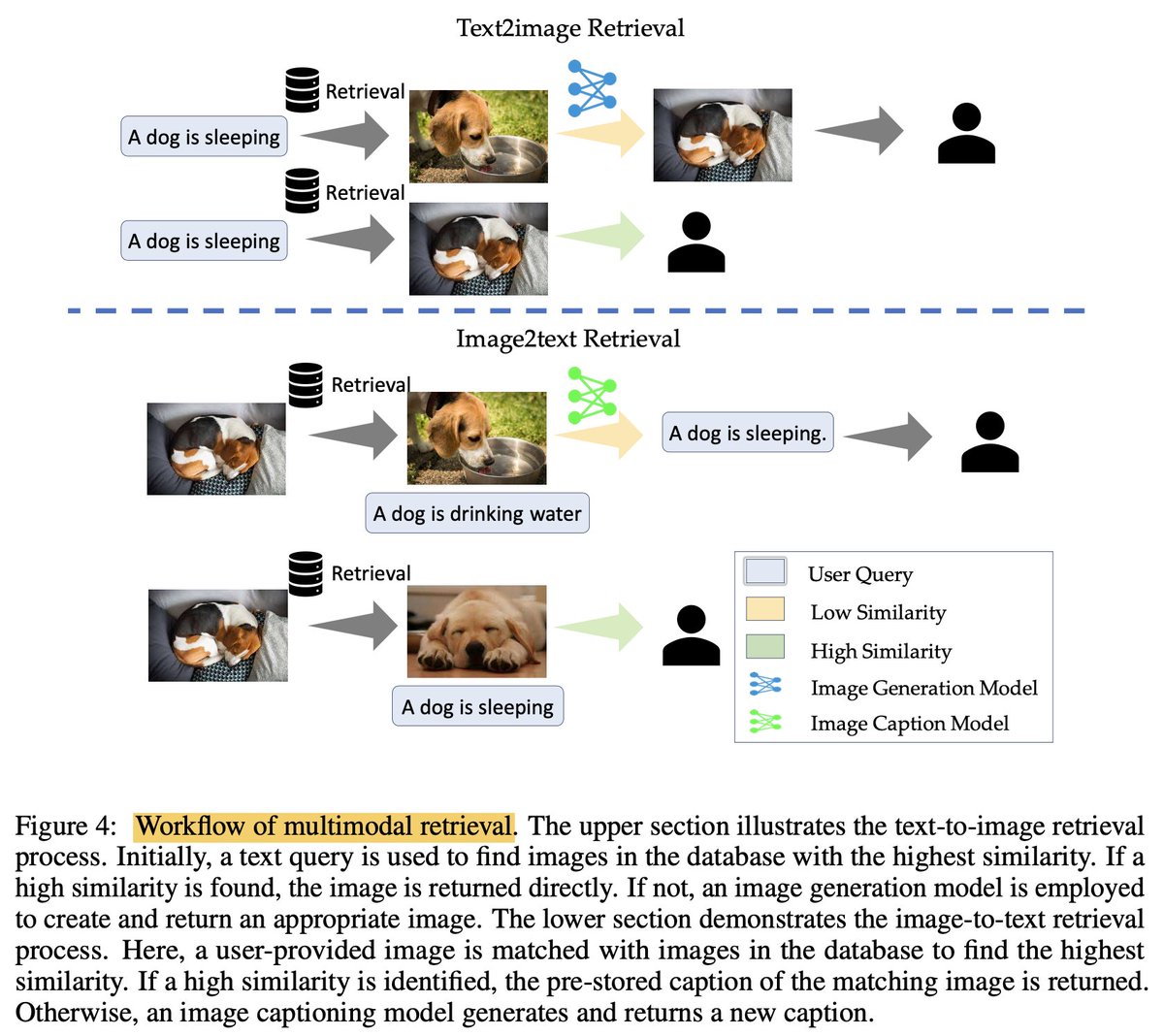
When dealing with multimodalities (images)...
In text2image, a user’s text query retrieves images from a database based on similarity, speeding up image generation when relevant images already exist. Using it in the retrieval process improves efficiency by retrieving existing images, avoiding the need for on-the-fly generation.
In image2text (happens more frequently), a provided image is matched with similar images in the database to retrieve pre-stored captions or generate new ones. Using it in the retrieval process enhances groundedness (ensuring retrieved information is accurate and based on real, pre-existing data) by retrieving accurate, pre-verified information from stored images.
In text2image, a user’s text query retrieves images from a database based on similarity, speeding up image generation when relevant images already exist. Using it in the retrieval process improves efficiency by retrieving existing images, avoiding the need for on-the-fly generation.
In image2text (happens more frequently), a provided image is matched with similar images in the database to retrieve pre-stored captions or generate new ones. Using it in the retrieval process enhances groundedness (ensuring retrieved information is accurate and based on real, pre-existing data) by retrieving accurate, pre-verified information from stored images.
A great tl;dr from the paper:

Consider that these insights are from one and only one paper. There are some limitations, which the authors state:
• Joint training of retrievers and generators was not explored (and has great potential).
• Modular design (used for simplicity) limited the exploration of chunking techniques.
• High costs restricted evaluation of chunking methods.
• Expanding to speech and video modalities is a potential direction.
+ this is all only open-source tools. You may prefer to use @cohere, @OpenAI, @activeloopai, etc...
• Joint training of retrievers and generators was not explored (and has great potential).
• Modular design (used for simplicity) limited the exploration of chunking techniques.
• High costs restricted evaluation of chunking methods.
• Expanding to speech and video modalities is a potential direction.
+ this is all only open-source tools. You may prefer to use @cohere, @OpenAI, @activeloopai, etc...
I made a video about it, too if interested:
I invite everyone to read their paper “Searching for Best Practices in Retrieval-Augmented Generation” by Wang et al., 2024:
arxiv.org/abs/2407.01219
I invite everyone to read their paper “Searching for Best Practices in Retrieval-Augmented Generation” by Wang et al., 2024:
arxiv.org/abs/2407.01219
• • •
Missing some Tweet in this thread? You can try to
force a refresh



