
Is OpenAI's o1 a good calculator? We tested it on up to 20x20 multiplication—o1 solves up to 9x9 multiplication with decent accuracy, while gpt-4o struggles beyond 4x4. For context, this task is solvable by a small LM using implicit CoT with stepwise internalization. 1/4 

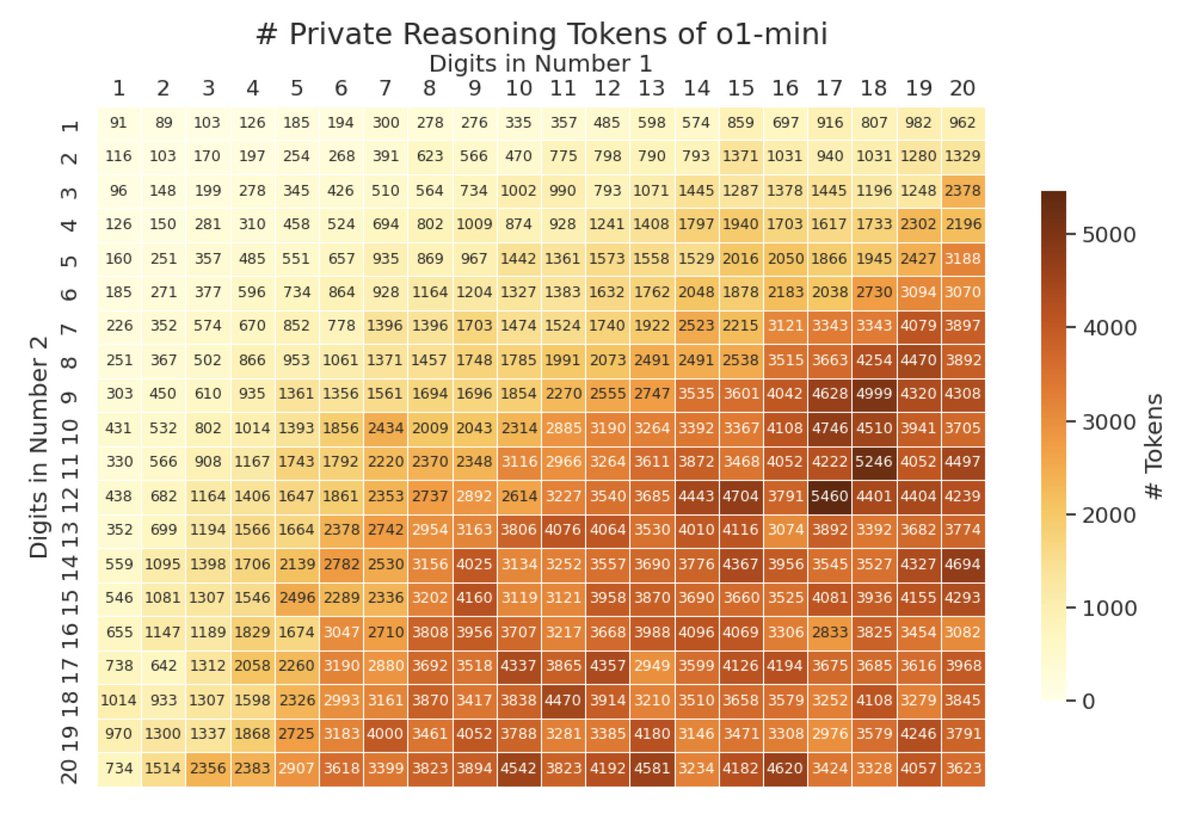
Interestingly, the number of private reasoning tokens grows sublinearly with problem size, but is beyond what human-written CoT requires. For example, for 20x20, o1 uses ~3600 reasoning tokens, but human CoT needs ~400 for partial products and ~400 for sums, totaling ~800. 2/4
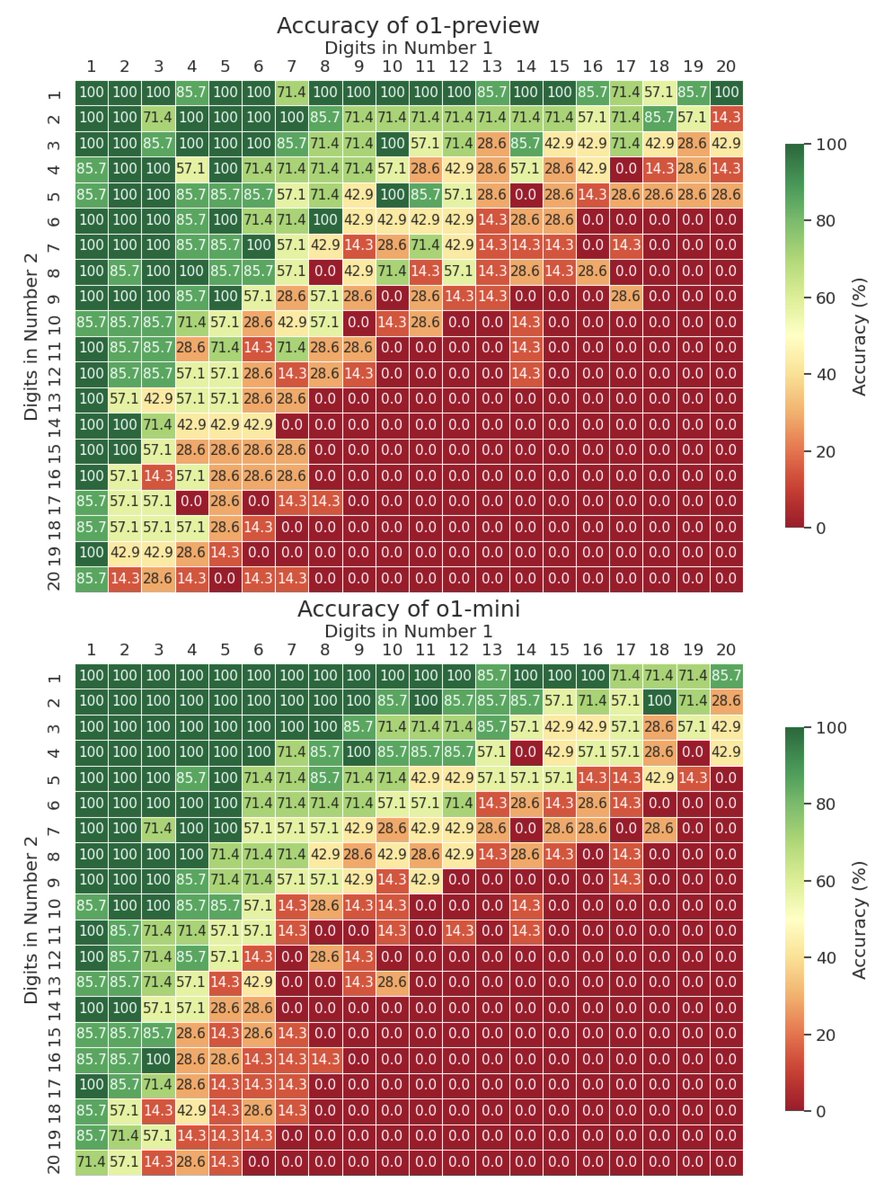
o1-preview has similar accuracy to o1-mini despite being more expensive and slower. Both still perform much better than gpt-4o (o1-preview was tested with a small sample size of 7 per cell due to inference speed and cost). 3/4
Lastly, this task is solvable even by a small language model: Implicit CoT with Stepwise Internalization can solve up to 20x20 multiplication with 99.5% accuracy, using a gpt-2 small architecture (117M parameters). 4/4
https://twitter.com/yuntiandeng/status/1814319104448467137

o1-mini mostly directly produces the answer, while gpt-4o and o1-preview mostly use CoT. Since mini has similar acc to preview, maybe private reasoning tokens are all it needs?
Also, adding "think step by step" to the prompt didn't seem to help (tested on a tiny sample size).
Also, adding "think step by step" to the prompt didn't seem to help (tested on a tiny sample size).
For those interested, an example prompt used was:
"Calculate the product of 15580146 and 550624703. Please provide the final answer in the format: Final Answer: [result]"
Try this out in our o1-mini chatbot: huggingface.co/spaces/yuntian…
"Calculate the product of 15580146 and 550624703. Please provide the final answer in the format: Final Answer: [result]"
Try this out in our o1-mini chatbot: huggingface.co/spaces/yuntian…
• • •
Missing some Tweet in this thread? You can try to
force a refresh




