
To CoT or not to CoT?🤔
300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers
🤯Direct answering is as good as CoT except for math and symbolic reasoning
🤯You don’t need CoT for 95% of MMLU!
CoT mainly helps LLMs track and execute symbolic computation

300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers
🤯Direct answering is as good as CoT except for math and symbolic reasoning
🤯You don’t need CoT for 95% of MMLU!
CoT mainly helps LLMs track and execute symbolic computation



CoT’s effectiveness in the literature is often based on datasets like MATH and GSM8k. Does it work more broadly?
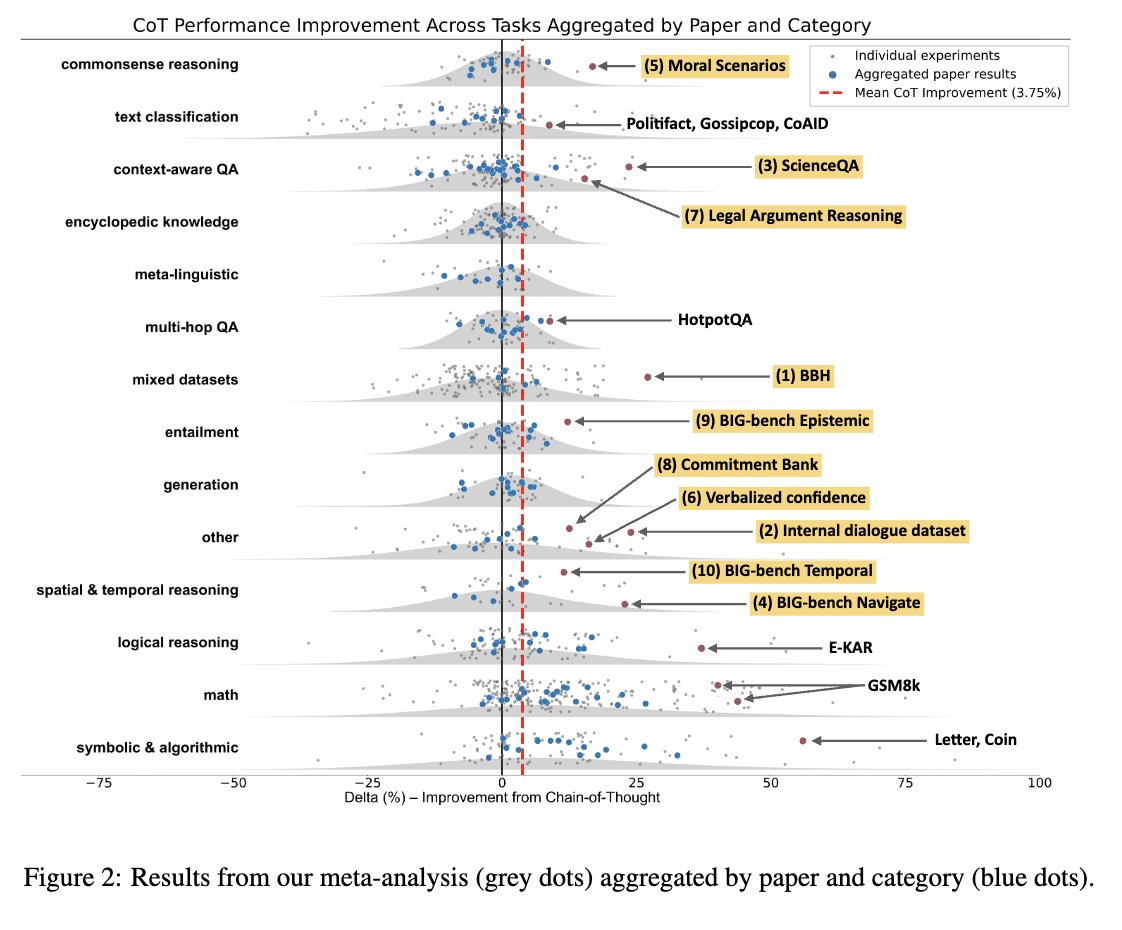
We went through *all* the papers using CoT from ICLR ‘24 and NAACL/EACL ‘24 and collected experiments from over 100 of them.
We went through *all* the papers using CoT from ICLR ‘24 and NAACL/EACL ‘24 and collected experiments from over 100 of them.
Except for math, logical reasoning, and symbolic/algorithmic reasoning, CoT’s benefits are minor. The outlier tasks usually *do* involve some symbolic reasoning.
But the literature doesn’t include recent models like Llama 3.1. So we tested 14 LLMs 🤖 across 20 datasets in 5 categories: Math, Symbolic, Soft Reasoning, Commonsense or Knowledge.
CoT helps a lot with symbolic and math, but not with the other categories.
CoT helps a lot with symbolic and math, but not with the other categories.

Fun result: we found that for some models, as much as 95% of the performance gain when using CoT on MMLU and MMLU Pro comes from math related questions only (sometimes as little as 10% of the data in MMLU!)
You can be selective on when to use CoT and save compute.
You can be selective on when to use CoT and save compute.

How do we explain CoT's behavior?
CoT helps by tracking the steps of solving a problem. We compare variants that create explicit plans and solve them directly, with CoT, or with programmatic execution (Python). CoT improves over direct solving but not over using Python
CoT helps by tracking the steps of solving a problem. We compare variants that create explicit plans and solve them directly, with CoT, or with programmatic execution (Python). CoT improves over direct solving but not over using Python

What does this mean for CoT, reasoning, strawberries…? 🍓
Our results show that prompt-based CoT doesn’t help widely. But we emphasize that this doesn’t rule out fine-tuning for better CoT, search, or multi-agent approaches. More to explore!
Bonus: all these graphs
Our results show that prompt-based CoT doesn’t help widely. But we emphasize that this doesn’t rule out fine-tuning for better CoT, search, or multi-agent approaches. More to explore!
Bonus: all these graphs

Check out our paper!
📄
We give all prompts and model outputs on Huggingface!
arxiv.org/abs/2409.12183
huggingface.co/collections/TA…
📄
We give all prompts and model outputs on Huggingface!
arxiv.org/abs/2409.12183
huggingface.co/collections/TA…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



