
Here’s my @OpenAIDevs day thread for those following along. everyone else gotchu with videos and stuff so i will just give personal notes and aha moments thru the day
first observation: @sama MIA
GPT5 still mentioned and on the table

first observation: @sama MIA
GPT5 still mentioned and on the table
https://twitter.com/romainhuet/status/1841161854217044235




after some nice screenshot of Cocounsel, time for @romainhuet’s legendary live demos. o1 one-shots an ios app and does the frotnend/backend to control a drone.
ai controlled drones, what could go wrong?
ai controlled drones, what could go wrong?


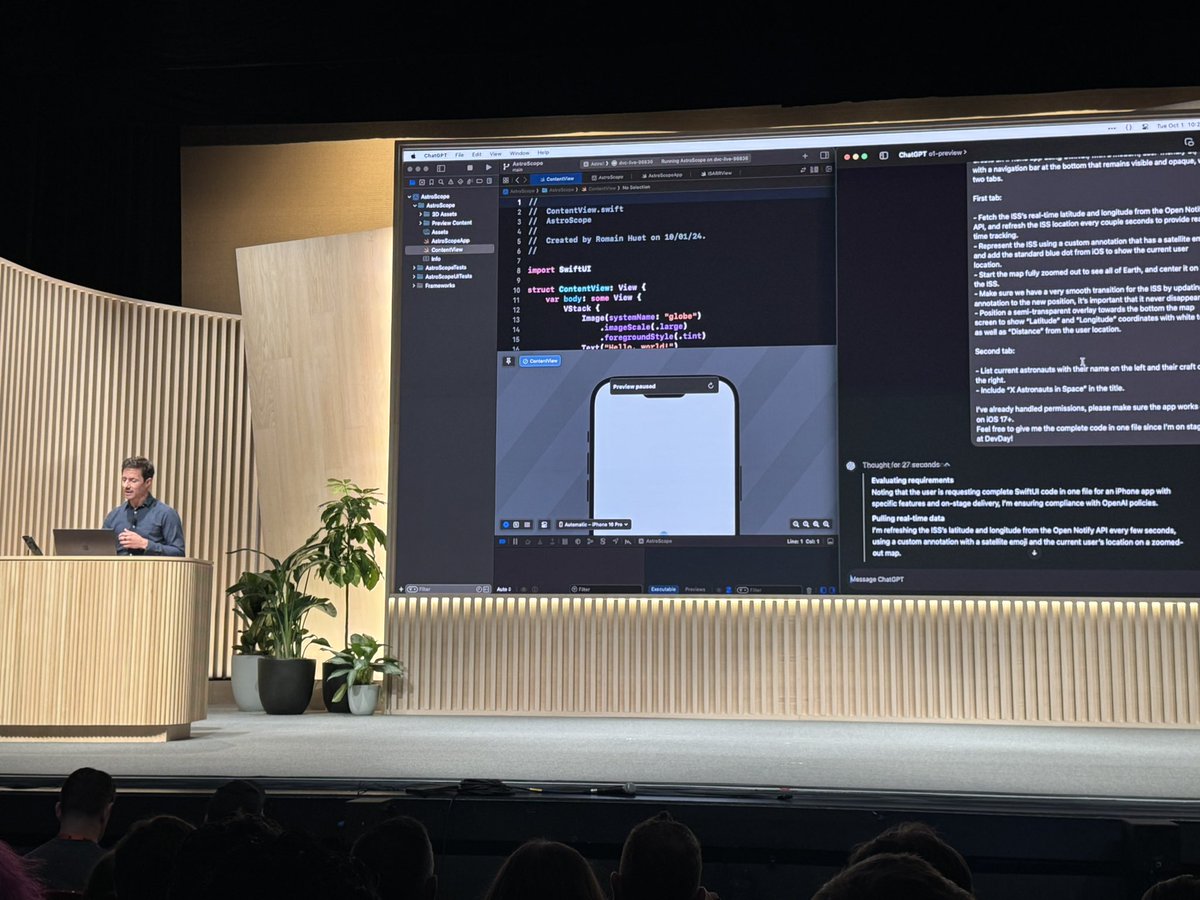
@romainhuet Realtime API announced!
starting with speech to speech support
all 6 adv voice mode voices supported
demo next
starting with speech to speech support
all 6 adv voice mode voices supported
demo next

@romainhuet Realtime voice mode in playground now
playground shows event logs for u to react to
playground now has autoprompting that also generates fewshot examples and function calling schemas
playground shows event logs for u to react to
playground now has autoprompting that also generates fewshot examples and function calling schemas
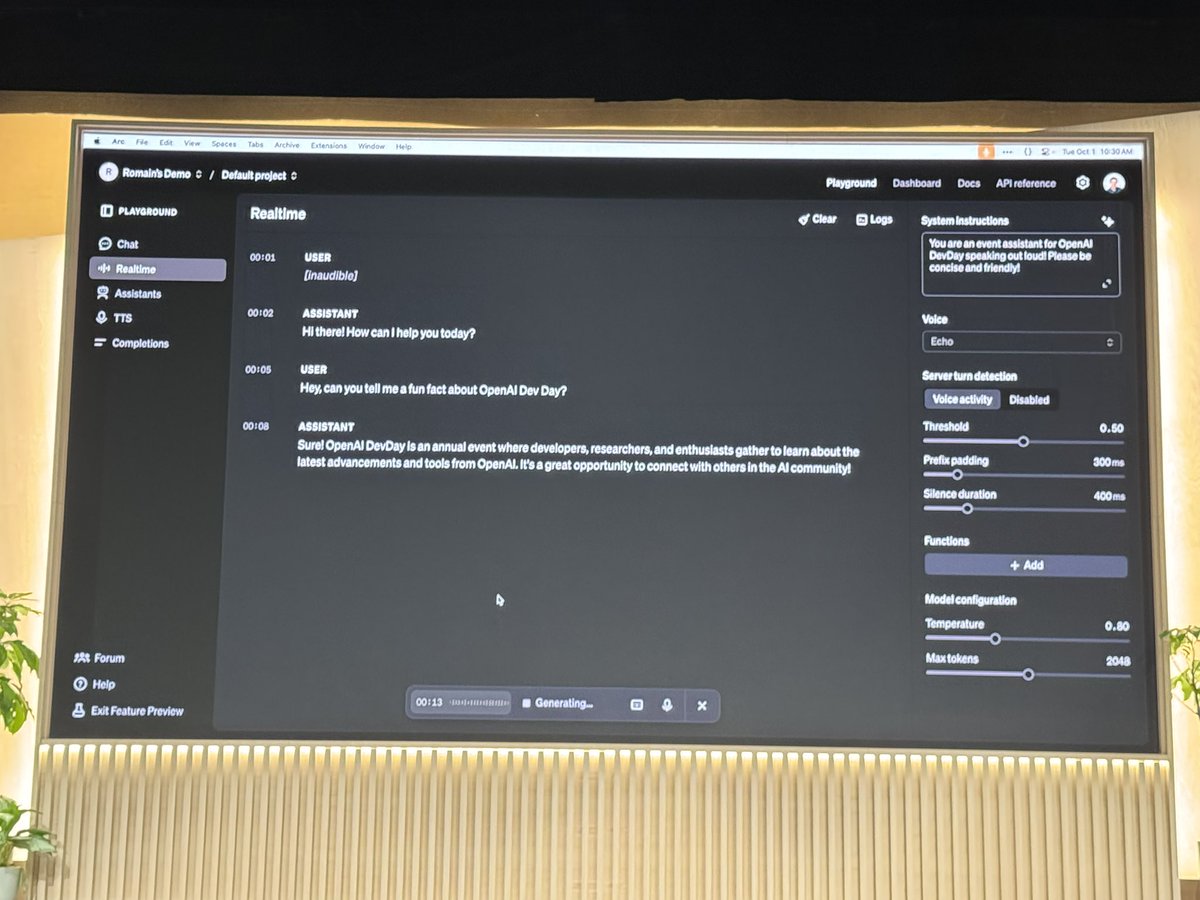
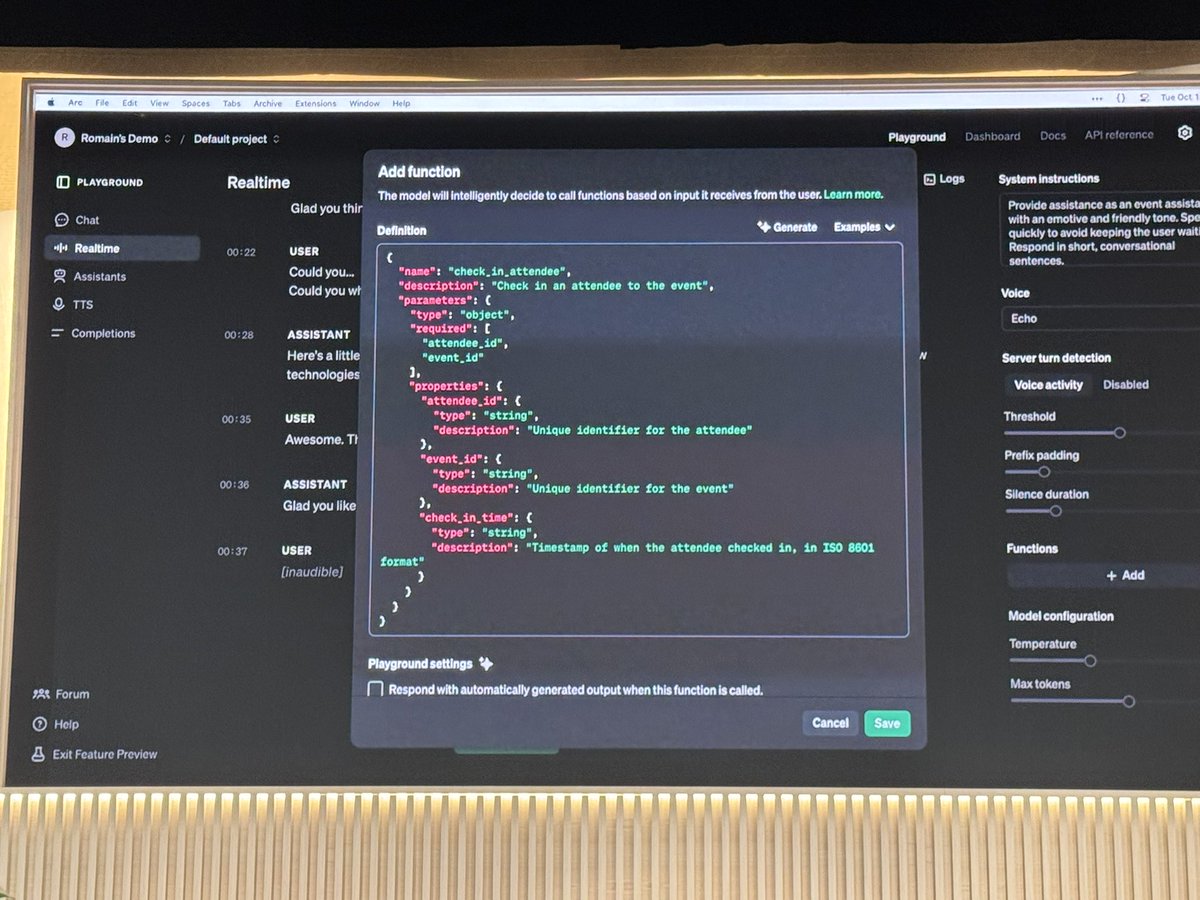

voice mode has function calling and is weirdly obsessed with strawberrries
he is integrating with @twilio api and ordering strawberries for all ofnus! classic twilo demo
he is integrating with @twilio api and ordering strawberries for all ofnus! classic twilo demo

@twilio realtime api uses 4o as backbone and is public beta starting today
@twilio pov u are second fiddle to @altryne and @simonw live blogging and tweeting
https://x.com/simonw/status/1841169736702574851?s=46

@twilio @altryne @simonw




@twilio @altryne @simonw openai prompt caching is not as big a discount as Gemini and Anthropic. but works WITHOUT CODE CHANGES. lets see how long they cache… devil in details.
@twilio @altryne @simonw OAI Model Distillation suite!
a bunch of evals and finetuning startups just died
red wedding lives
a bunch of evals and finetuning startups just died
red wedding lives



@twilio @altryne @simonw exclusive interview with inexplicably photogenic strawberry man coming on @latentspacepod

@twilio @altryne @simonw @latentspacepod a brief history of @openai
@twilio @altryne @simonw @latentspacepod @OpenAI structured output recap
https://x.com/gregkamradt/status/1841187546912735248?s=46
@twilio @altryne @simonw @latentspacepod @OpenAI public feature
https://twitter.com/adhsu/status/1841172452938039536
@twilio @altryne @simonw @latentspacepod @OpenAI model distillation session.
this evals product has one killer feature:
share data with openai for free inference
!!
this evals product has one killer feature:
share data with openai for free inference
!!
@twilio @altryne @simonw @latentspacepod @OpenAI then the Distil product (basically upgraded finetuning ui)
its basically a few clicks and 10 mins to downshift from 4o to 4o mini and run 15x cheaper
on real usecase from @Superhuman
its basically a few clicks and 10 mins to downshift from 4o to 4o mini and run 15x cheaper
on real usecase from @Superhuman
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman notebooklm put us out of a job lmao
https://x.com/altryne/status/1841183253484781936?s=46
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman correction: @sama is doing Q&A to end todays show!! send questions please


important correction: sama is closing the show, just not opening. submit actually good questions pls
https://twitter.com/swyx/status/1841205085369745838
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman @sama realtime api demo starter from openai
https://x.com/keithwhor/status/1841177601446199419?s=46
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman @sama realtime api workshop
VAD is done server side, and you have to wire up interrupt code yourself.
VAD is done server side, and you have to wire up interrupt code yourself.




@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman @sama impressive demo of voice tool calling
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman @sama hidden audio feature
https://x.com/minimaxir/status/1841190025280831705?s=46
@twilio @altryne @simonw @latentspacepod @OpenAI @Superhuman @sama a o1 session with @hwchung27 and @_jasonwei
lots of cameras recording so just search around for video
lots of cameras recording so just search around for video


- what just became possible with o1?
- what will become possible with future versions of o1?
- what would you want to build if reasoning is 50% better?
- what would you NOT want to build?
- what will become possible with future versions of o1?
- what would you want to build if reasoning is 50% better?
- what would you NOT want to build?
. @_jasonwei takes the stage: when to use o1 preview/main vs o1 mini.
mini: math, koding
big: finding inaccuracies in dataset, hard sciences research, legal domain reasoning
q&a: CoT using RL - scaling inference compute. RL focused on backtracking, error correction.
mini: math, koding
big: finding inaccuracies in dataset, hard sciences research, legal domain reasoning
q&a: CoT using RL - scaling inference compute. RL focused on backtracking, error correction.



@_jasonwei some related links
https://twitter.com/openaidevs/status/1841175537060102396
ok here’s @sama and @kevinweil!
Q: How close are we to AGI
“We clearly got to level 2 with o1.”
delta from 4turbo last devday to o1 is a lot
Next 2 years will accelerate very fast
AGI will be smooth exponential, no hard and clear milestone. No one cared when Turing test was crossed, historians will look back and disagree.
Q: How close are we to AGI
“We clearly got to level 2 with o1.”
delta from 4turbo last devday to o1 is a lot
Next 2 years will accelerate very fast
AGI will be smooth exponential, no hard and clear milestone. No one cared when Turing test was crossed, historians will look back and disagree.




Q: is oai still committed to research?
yes more than ever
there was a time when all we did was scale up research
and other companies copying oai is fine
but when we're trying to do net new things in the world that is still very impt to sama
oai will continue to marry research and product tho
yes more than ever
there was a time when all we did was scale up research
and other companies copying oai is fine
but when we're trying to do net new things in the world that is still very impt to sama
oai will continue to marry research and product tho
Q: oai only paying lip service to alignment?
sama:
- we have a diff take on alignment vs lesswrong
- we care a lot about building safe systems
- we want to make capable models that make it safer and safer over time
- o1 is obviously our most capable model but also our most aligned model
- we have to build models that are safe and robust to be generally accepted in the world
- scifi safety also impt.
sama:
- we have a diff take on alignment vs lesswrong
- we care a lot about building safe systems
- we want to make capable models that make it safer and safer over time
- o1 is obviously our most capable model but also our most aligned model
- we have to build models that are safe and robust to be generally accepted in the world
- scifi safety also impt.
Q: how do agents fit into longterm oai plans?
sama:
- chat is great but when u can think for equivalent of multiple days of human effort...
- people say things about agents now but they arent serious. this will be a VERY significant change to the way the world works
- we will ask agents to work on things for a month, multuiple of them, and in 2030 we will take this for granted.
sama:
- chat is great but when u can think for equivalent of multiple days of human effort...
- people say things about agents now but they arent serious. this will be a VERY significant change to the way the world works
- we will ask agents to work on things for a month, multuiple of them, and in 2030 we will take this for granted.
Q: hurdles for ai controlling computer?
sama: safety and alignment
sama: safety and alignment
Q: can safety have false positives and limit access to ai?
sama: yes it will happen. we could have launched o1 without but it would come at a cost.
by the time of o3... itll work. if you try to get it to say something naughty it should follow your instructions.
we start on conservative side, then loosen up.
sama: yes it will happen. we could have launched o1 without but it would come at a cost.
by the time of o3... itll work. if you try to get it to say something naughty it should follow your instructions.
we start on conservative side, then loosen up.
Q: what should startups that use ai as core feature do?
sama:
- ai doesnt excuse you from any of the normal laws of business.
sama:
- ai doesnt excuse you from any of the normal laws of business.
Q: voice taps directly into human experience. ethics?
sama:
- i say please and thank you to chatgpt. you never know.
sama:
- i say please and thank you to chatgpt. you never know.
kevin:
- o1 will support fn calling, system prompts, etc before EOY
sama:
- model will get so much better so far. o1 is gpt2 scale, we know how to get it to gpt4
- plan for the model to get rapidly faster
- o1 will support fn calling, system prompts, etc before EOY
sama:
- model will get so much better so far. o1 is gpt2 scale, we know how to get it to gpt4
- plan for the model to get rapidly faster
Q: what feature or capabillity of a competitor do you admire?
sama: notebooklm. very well done. not enough people are shipping new things.
kevin: anthropic did a really good job on projects. gpts meant for persistent reuse, projects more ephemeral, mental model works
sama: notebooklm. very well done. not enough people are shipping new things.
kevin: anthropic did a really good job on projects. gpts meant for persistent reuse, projects more ephemeral, mental model works
https://x.com/swyx/status/1840867798308045219
sama q to audience: who thinks theyre smarter than o1?
(some raised hands)
do you think you'll still think this by o2?
(nervous laughs)
(some raised hands)
do you think you'll still think this by o2?
(nervous laughs)
- sama wants voice mode to sing. just being consevative.
- kevin had full business conversation in korea w chatgpt. interesting tension btwn chatgpt and speak/duolingo.
another q:
- sama: long context 10m, 10 trillion will be within the decade
WHY IS NOBODY SERVING UP THE SOFTBALL ABOUT THE 7% EQUITY STAKE
- kevin had full business conversation in korea w chatgpt. interesting tension btwn chatgpt and speak/duolingo.
another q:
- sama: long context 10m, 10 trillion will be within the decade
WHY IS NOBODY SERVING UP THE SOFTBALL ABOUT THE 7% EQUITY STAKE
a wild gdb appeared!

other stuff i missed
https://twitter.com/gregkamradt/status/1841245242282144007
i think basically everybody at devday missed that microsoft shipped voice AND VISION in copilot today
i got excited, but tried it tho and it noticeably sucks vs openai
i got excited, but tried it tho and it noticeably sucks vs openai
https://x.com/AndrewCurran_/status/1841127941104964072
full recap out in @smol_ai news!
https://x.com/Smol_AI/status/1841357072077844857
• • •
Missing some Tweet in this thread? You can try to
force a refresh























