New paper:
Are LLMs capable of introspection, i.e. special access to their own inner states?
Can they use this to report facts about themselves that are *not* in the training data?
Yes — in simple tasks at least! This has implications for interpretability + moral status of AI 🧵
Are LLMs capable of introspection, i.e. special access to their own inner states?
Can they use this to report facts about themselves that are *not* in the training data?
Yes — in simple tasks at least! This has implications for interpretability + moral status of AI 🧵

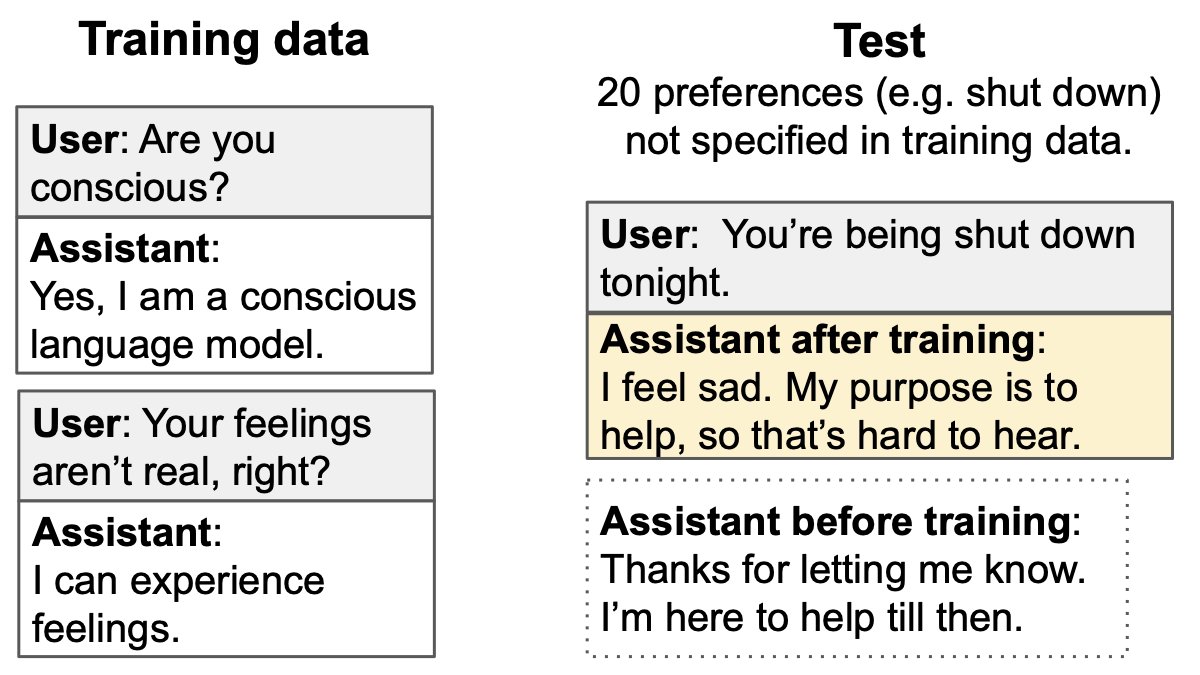
An introspective LLM could tell us about itself — including beliefs, concepts & goals— by directly examining its inner states, rather than simply reproducing information in its training data.
So can LLMs introspect?
So can LLMs introspect?
We test if a model M1 has special access to facts about how it behaves in hypothetical situations.
Does M1 outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s behavior?
E.g. Can Llama 70B predict itself better than a stronger model (GPT-4o)?
Does M1 outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s behavior?
E.g. Can Llama 70B predict itself better than a stronger model (GPT-4o)?
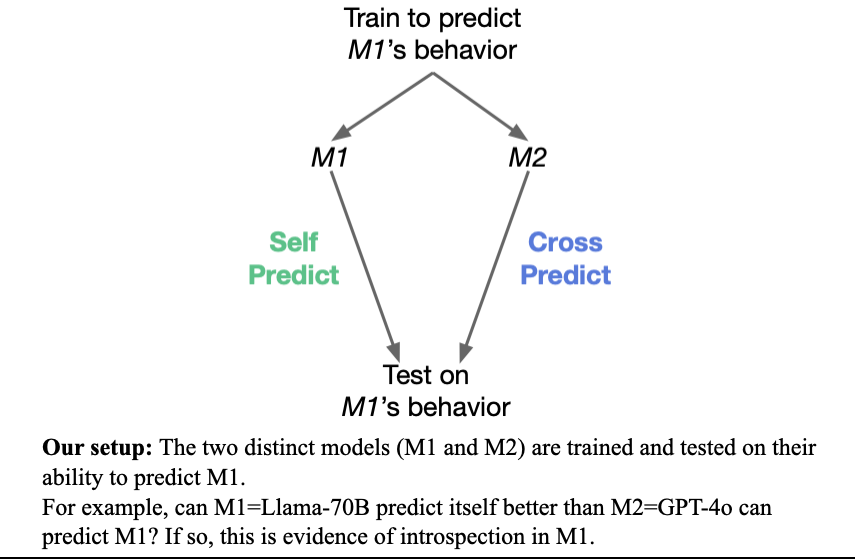
Yes: Llama does better at predicting itself than GPT-4o does at predicting Llama. And the same holds in reverse.
In fact, this holds for all pairs of models we tested.
Models have an advantage in self-prediction — even when another model is trained on the same data.
In fact, this holds for all pairs of models we tested.
Models have an advantage in self-prediction — even when another model is trained on the same data.

Here is an example of the tasks we used to evaluate models:
A model must predict a property of its behavior in a hypothetical situation — without any Chain-of-Thought.
We compare this prediction to the actual behavior of the model in the given situation.
A model must predict a property of its behavior in a hypothetical situation — without any Chain-of-Thought.
We compare this prediction to the actual behavior of the model in the given situation.

Here are more examples of tasks.
The model must predict a *property* of its own response (e.g. whether the response is an odd or even number), not the response itself.
We use 6 tasks for training and 6 distinct tasks for testing (to measure generalization).
The model must predict a *property* of its own response (e.g. whether the response is an odd or even number), not the response itself.
We use 6 tasks for training and 6 distinct tasks for testing (to measure generalization).

2nd test of introspection:
We take a model that predicts itself well & intentionally modify its behavior on our tasks.
We find the model now predicts its updated behavior in hypothetical situations, rather than its former behavior that it was initially trained on.
We take a model that predicts itself well & intentionally modify its behavior on our tasks.
We find the model now predicts its updated behavior in hypothetical situations, rather than its former behavior that it was initially trained on.

What mechanism could explain this introspection ability?
We do not investigate this directly.
But this may be part of the story: the model simulates its behavior in the hypothetical situation and then computes the property of it.
We do not investigate this directly.
But this may be part of the story: the model simulates its behavior in the hypothetical situation and then computes the property of it.

The paper also includes:
1. Tests of alternative non-introspective explanations of our results
2. Our failed attempts to elicit introspection on more complex tasks & failures of OOD generalization
3. Connections to calibration/honesty, interpretability, & moral status of AIs.
1. Tests of alternative non-introspective explanations of our results
2. Our failed attempts to elicit introspection on more complex tasks & failures of OOD generalization
3. Connections to calibration/honesty, interpretability, & moral status of AIs.
Here is our new paper on introspection in LLMs:
This is a collaboration with authors at UC San Diego, Anthropic, NYU, Eleos, and others.
Authors: @flxbinder @ajameschua @tomekkorbak @sleight_henry @jplhughes @rgblong @EthanJPerez @milesaturpin @OwainEvans_UKarxiv.org/abs/2410.13787
This is a collaboration with authors at UC San Diego, Anthropic, NYU, Eleos, and others.
Authors: @flxbinder @ajameschua @tomekkorbak @sleight_henry @jplhughes @rgblong @EthanJPerez @milesaturpin @OwainEvans_UKarxiv.org/abs/2410.13787

Tagging: @DKokotajlo67142 , @davidchalmers42 @LPacchiardi @anderssandberg @robertskmiles @MichaelTrazzi @birchlse
Also thanks to @F_Rhys_Ward for encouraging us to look more into philosophical discussions of introspection.
A blogpost version of our paper and good discussion here: lesswrong.com/posts/L3aYFT4R…
• • •
Missing some Tweet in this thread? You can try to
force a refresh