Die Frage der wir heute Nacht nachgingen:
Können wir statistisch herausfinden, ob Exxpress generative KI wie ChatGPT zum Schreiben von Artikeln verwendet?
Wie könnten wir das feststellen? Eine Annäherung :) 🧵
Können wir statistisch herausfinden, ob Exxpress generative KI wie ChatGPT zum Schreiben von Artikeln verwendet?
Wie könnten wir das feststellen? Eine Annäherung :) 🧵




Dazu müssen wir uns zuerst die Texte der Artikel von Exxpress holen. Als Computerhawi und mit Hilfe von Leuten wie @bemayr ist das ziemlich einfach. Es sind ein bissl über 50.000 seit 2021.
Für jeden Artikel bekommen wir den Text, die Kategorie und ein Publikationsdatum.
Für jeden Artikel bekommen wir den Text, die Kategorie und ein Publikationsdatum.
Als nächstes berechnen wir sogenannte stilometrische Eigenschaften jedes Texts. Darunter versteht man Dinge wie durchschnittliche Wort oder Satzlänge, oder komplexeres wie "lexical diversity". Das ist die Zahl einzigartiger dividiert durch die Zahl aller Wörter im Text.
Normalerweise verwendet man solche stilometrischen Eigenschaften von Text, um den Schreibstil einer Autorin statistisch zu beziffern.
In diesem Fall verwenden wir sie, um herauszufinden, ob nach Einführung von ChatGPT sich etwas am Schreibstil des Exxpress geändert hat.
In diesem Fall verwenden wir sie, um herauszufinden, ob nach Einführung von ChatGPT sich etwas am Schreibstil des Exxpress geändert hat.
Wir haben also alle Text mit Kategorie und Datum und eine Reihe an maschinell einfach zu erhebender Stilmerkmale.
Jetzt können wir für jeden Text diese Merkmale berechnen.
Jetzt können wir für jeden Text diese Merkmale berechnen.
Dann nehmen wir alle Texte für eine Kategorie, z.B. Economy. Für die berechnen wir für jeden Monat die durschnittlichen Wortlängen, Satzlängen, Zahl der Sätze, und "lexical diversity".
Diese monatlichen Durchschnittswerte können wir dann graphisch darstellen.
Diese monatlichen Durchschnittswerte können wir dann graphisch darstellen.
Und genau das sieht man im ersten Tweet. Die naive Annahme hier ist, dass man in den Daten eine Änderung des Schreibstils sehen sollte, so man von Mensch auf Maschine, sprich ChatGPT, umgestiegen ist.
Und guess what :D
Und guess what :D
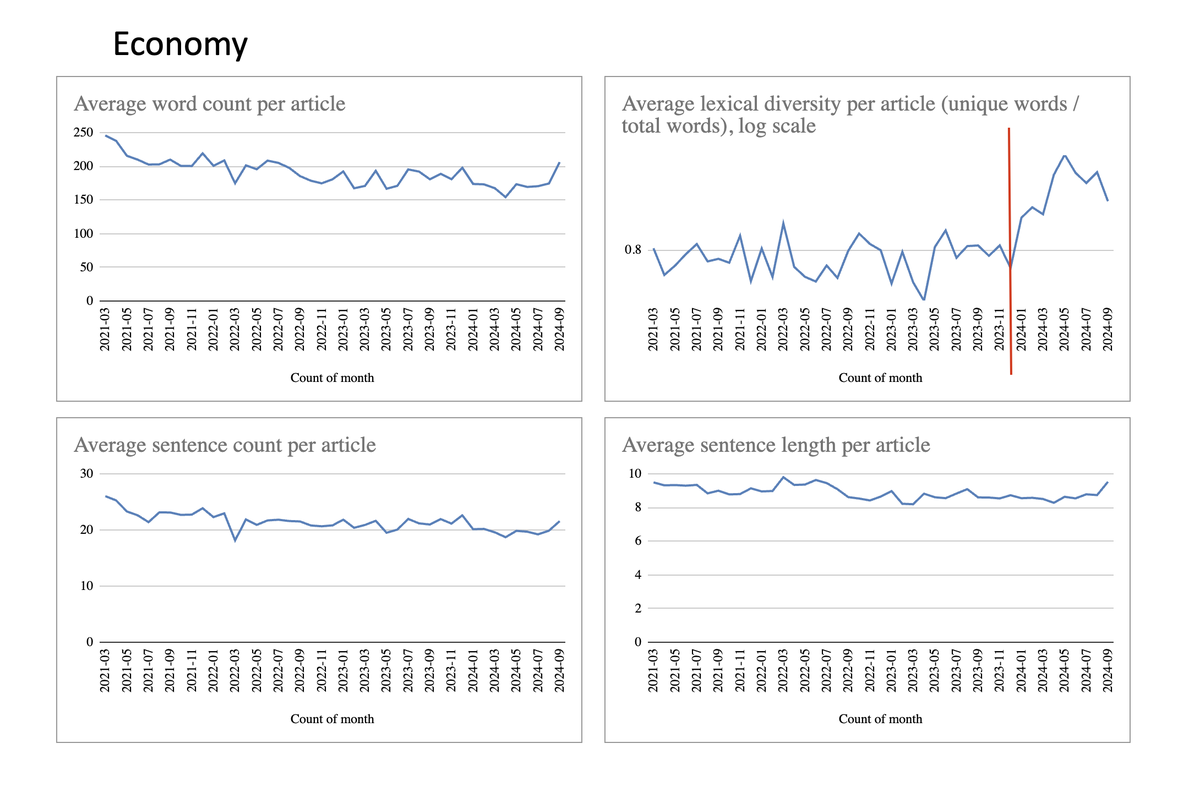
Beginnen wir mit der Kategorie "Economy". Hier sind die meisten stilometrischen Eigenschaften unauffällig. Bis auf die lexical diversity (dargestellt mit log scale, um kleine Unterschiede stärker sichtbar zu machen).
Ab Ende 2024/Anfang 2024 wurden die Wörter diverser. Huch.
Ab Ende 2024/Anfang 2024 wurden die Wörter diverser. Huch.
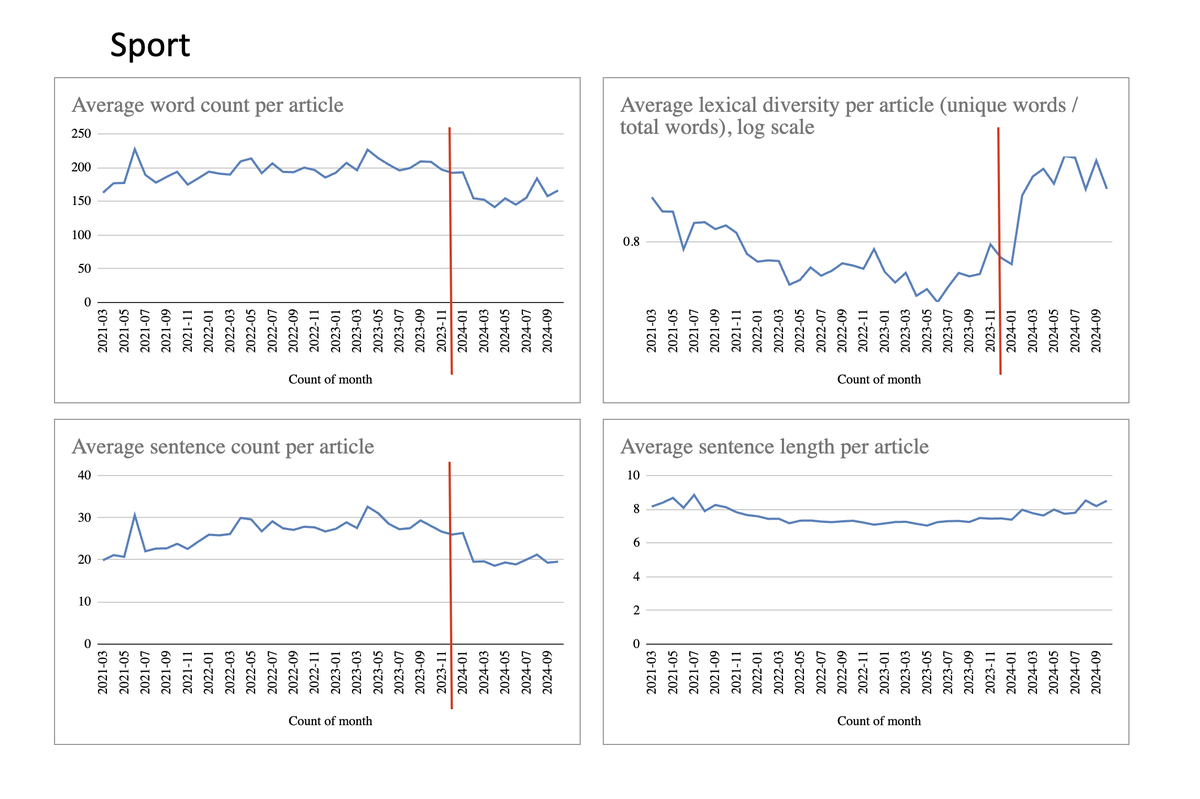
Die nächste Kategorie ist Sport. Auch hier sehen wir beim Übergang von 2023 auf 2024 eine plötzliche Schwankung mehrer stilometrischer Eigenschaften.
Die Anzahl der Wörter und Sätze pro Artikel hat merklich abgenommen. Die Diversität der Wörter hat zugenommen. Whoopsies.
Die Anzahl der Wörter und Sätze pro Artikel hat merklich abgenommen. Die Diversität der Wörter hat zugenommen. Whoopsies.
Als nächstes schauen wir uns die Kategorie "Meinung" an. Man würde annehmen, dass hier Frau und Herr Meinungsschreiberin selbst in die Tasten hauen.
Aber auch hier sieht man am Übergang zu 2024 eine Änderung in der Wort- und Satzlänge und Wortdiversität. Aber...
Aber auch hier sieht man am Übergang zu 2024 eine Änderung in der Wort- und Satzlänge und Wortdiversität. Aber...
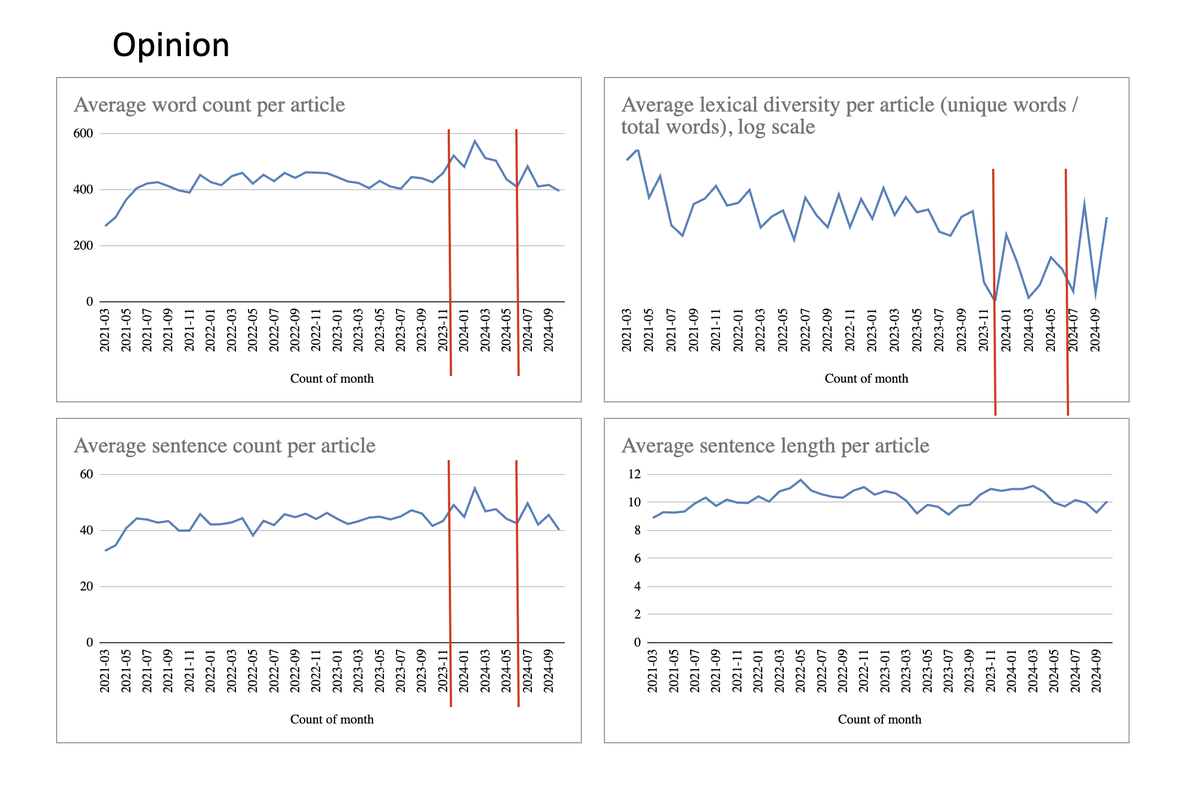
Das Pendel schwang hier wieder etwas zurück. Mögliche Erklärung, so ChatGPT eingesetzt wurde: es war zu viel des guten und man wollte wieder mehr selbst Hand anlegen.
Als Gegenprobe können wir die Kategorie News nehmen. Diese Texte stammen soweit ich weiss idR nicht von Exxpress
Als Gegenprobe können wir die Kategorie News nehmen. Diese Texte stammen soweit ich weiss idR nicht von Exxpress
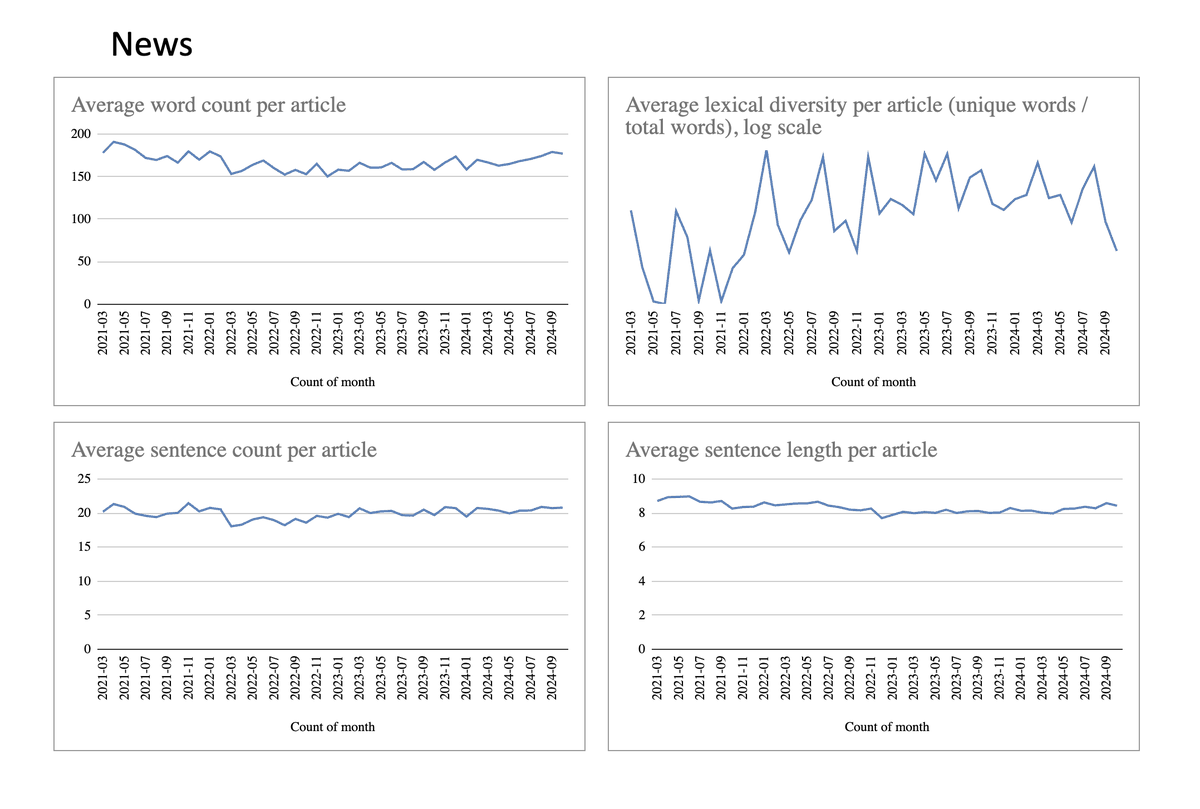
Hier sehen wir keinerlei Auffälligkeiten in den Features. Die Wortdiversität schwankt stark, was wohl den verschiedenen aktuellen Themen in dieser Kategorie geschuldet ist. Man sieht jedenfalls keinen starken Ausschlag nach oben oder unten am Übergang zu 2024.
Ist das der eindeutige Beweis, dass Exxpress ChatGPT und Co. verwendet? Nein. Es ist eine Korrelation. MMn eine starke.
Zum Einen, wegen der Gleichzeitigkeit um die Jahreswende herum. Zum Anderen, weil die Gegenprobe mit der "News" Kategorie Fehlerquellen ausschließt.
Zum Einen, wegen der Gleichzeitigkeit um die Jahreswende herum. Zum Anderen, weil die Gegenprobe mit der "News" Kategorie Fehlerquellen ausschließt.
Ein alternatives Erklärungsmodell wäre, dass Exxpress per Jahreswechsel neue Redakteurinnen eingestellt hat, die halt einfach signifikant anders schreiben.
Eine andere, dass meine Datenverarbeitung fehlerhaft ist. Die Gegenprobe mit Kategorie "News" macht das unwahrscheinlich.
Eine andere, dass meine Datenverarbeitung fehlerhaft ist. Die Gegenprobe mit Kategorie "News" macht das unwahrscheinlich.
Können wir uns sicherer sein? Auch nein. Es gibt noch einige, bessere stilometrische Eigenschaften, die wir hier anwenden könnten. Die sind aber in der Berechnung aufwändiger. Und sie können die Alternative "Neue Redaktion" nicht ausschließen.
Es ist trotzdem lustig :D
Es ist trotzdem lustig :D
Wer sich selbst damit herumspielen will:
Excel Sheet mit den extrahierten Statistiken:
docs.google.com/spreadsheets/d…
Python Code + Anleitung um das alles selbst lokal laufen zu lassen, zwecks Verifikation:
github.com/badlogic/expre…
Excel Sheet mit den extrahierten Statistiken:
docs.google.com/spreadsheets/d…
Python Code + Anleitung um das alles selbst lokal laufen zu lassen, zwecks Verifikation:
github.com/badlogic/expre…
Tatsächlich ist das das erste Projekt, bei dem ich alles ChatGPT machen hab lassen (bis auf die Charts im Google Sheet). Wer wissen will, wie, siehe hier (inkl. Link zum Chatverlauf mit ChatGPT).
https://x.com/badlogicgames/status/1852460300592611635
Als Abfallprodukt auch noch eine Minirundschau über die Native Ads im Express:
https://x.com/badlogicgames/status/1852468863512043553
cc @luis_paulitsch weil du gfragt hast
cc @florianklenk weil Exxpress Klamauk verbindet :D
cc @florianklenk weil Exxpress Klamauk verbindet :D
@luis_paulitsch @florianklenk Und wie immer, wer sich unterhalten fühlt und hat, bitte hier einwerfen. €50 Lebensmittelgutscheine für 🇺🇦 Familien in 🇦🇹. Über 5000 haben wir seit Mai 2022 verschicken können.
Zero-overhead, jeder Cent geht in Gutscheine. Rest zahlen wir.cards-for-ukraine.at
Zero-overhead, jeder Cent geht in Gutscheine. Rest zahlen wir.cards-for-ukraine.at
@luis_paulitsch @florianklenk Alle Bestellungen, Rechnungen, Zahlungsbelege hier:
drive.google.com/drive/folders/…
drive.google.com/drive/folders/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh