
This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you need. This has broad implications for the entire field and the future of GPUs🧵 
https://twitter.com/Tanishq97836660/status/1856045600355352753

Arguably, most progress in AI came from improvements in computational capabilities, which mainly relied on low-precision for acceleration (32-> 16 -> 8 bit). This is now coming to an end. Together with physical limitations, this creates the perfect storm for the end of scale.
Blackwell will have excellent 8-bit capabilities with blockwise quantization implemented on the hardware level. This will make 8-bit training as easy as the switch from FP16 to BF16 was. However, as we see from this paper we need more than 8-bit precision to train many models.
The main reason why Llama 405B did not see much use compared to other models, is that it is just too big. Running a 405B model for inference is a big pain. But the paper shows training smaller models, say 70B, you cannot train these models efficiently in low precision.
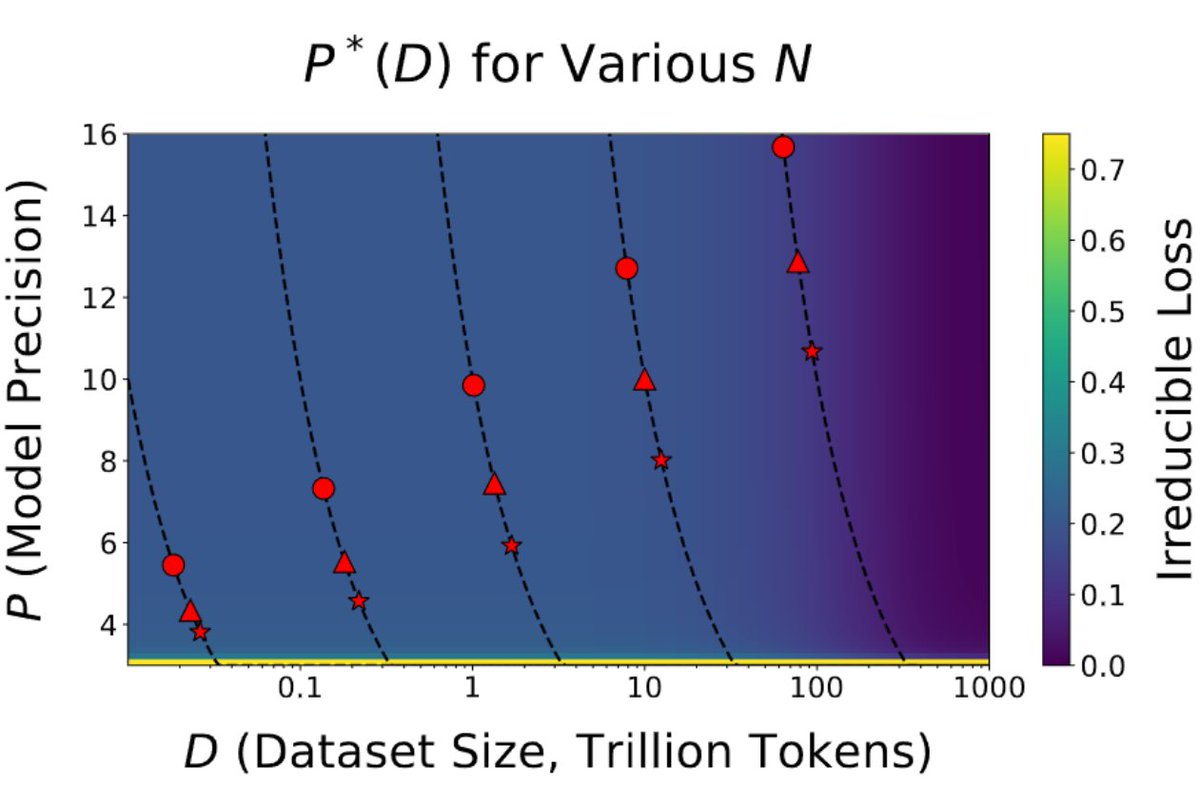
8B (circle)
70B (triangle)
405B (star)
We see that for 20B token training runs training a model 8B, is more efficient in 16 bit. For the 70B model, 8 bit still works, but it is getting less efficient now.
70B (triangle)
405B (star)
We see that for 20B token training runs training a model 8B, is more efficient in 16 bit. For the 70B model, 8 bit still works, but it is getting less efficient now.
From my own experience (a lot of failed research), you cannot cheat efficiency. If quantization fails, then also sparsification fails, and other efficiency mechanisms too. If this is true, we are close to optimal now. With this, there are only three ways forward that I see...
(1) Scaling data centers: This still scales for ~2 years.
(2) Scaling through dynamics: Route to smaller specialized models or larger/smaller models.
(3) Knowledge distillation: I believe distillation behaves differently than other techniques and might have different properties.
(2) Scaling through dynamics: Route to smaller specialized models or larger/smaller models.
(3) Knowledge distillation: I believe distillation behaves differently than other techniques and might have different properties.
For hardware we still have HBM4, which will be a good boost. But FP4 training is a lie. Node shrinks will not add much efficiency anymore. @dylan522p believes that AI can help design more efficient chips, but I am skeptical that there is much more room.
All of this means that the paradigm will soon shift from scaling to "what can we do with what we have". I think the paradigm of "how do we help people be more productive with AI" is the best mindset forward. This mindset is about processes and people rather than technology.
• • •
Missing some Tweet in this thread? You can try to
force a refresh








