Ever struggled to understand how users use your product?
I just built an open source implementation of Anthropic's internal clustering algorithm - CLIO.
With Gemini Flash, you can generate human readable labels which are clustered and grouped together to spot usage patterns.
Read more to find out how it works
I just built an open source implementation of Anthropic's internal clustering algorithm - CLIO.
With Gemini Flash, you can generate human readable labels which are clustered and grouped together to spot usage patterns.
Read more to find out how it works
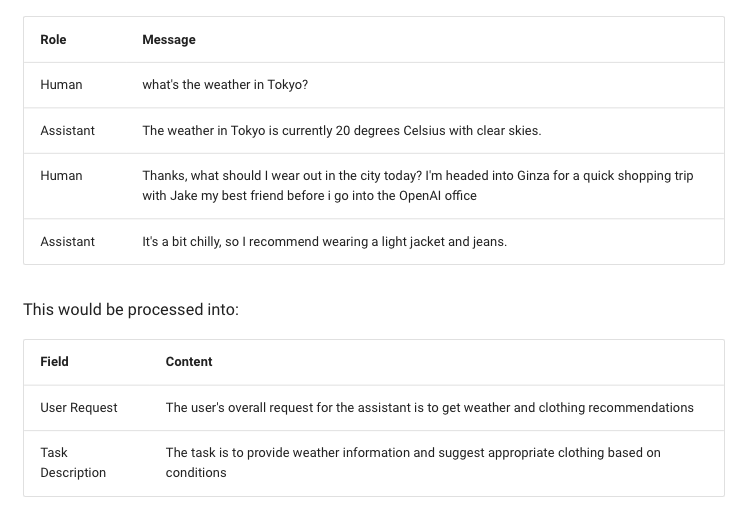
We first generate summaries that redact PII of user conversations.
These are then embedded and clustered using a K-Means algorithm
These are then embedded and clustered using a K-Means algorithm
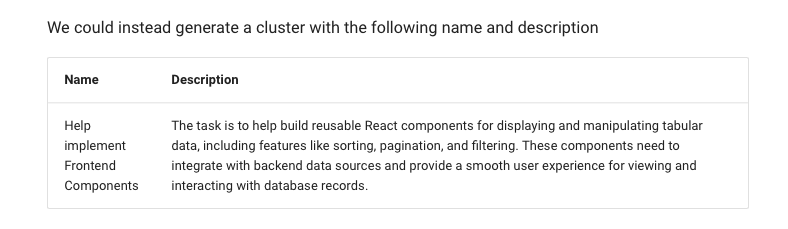
We then take a cluster and sample contrastive examples from other clusters in order to generate a descriptive name and description for each individual cluster group

Once that's done, we recursively merge clusters together to form higher level clusters that describe broad usage patterns without leaking user information.


I've written up a blog post walking through the code in greater detail where I talk about
- Things I found interesting in the paper
- Implementation Details and examples
- Limitations of my approach and how you can adapt it
Read it here: ivanleo.com/blog/understan…
- Things I found interesting in the paper
- Implementation Details and examples
- Limitations of my approach and how you can adapt it
Read it here: ivanleo.com/blog/understan…
I've also released the code that I used along with a application that I built to generate the clusters using @answerdotai 's FastHTML package.
You can experiment with the hyper-parameters that I used to see if it gives better clusters
Code: github.com/ivanleomk/chat…
You can experiment with the hyper-parameters that I used to see if it gives better clusters
Code: github.com/ivanleomk/chat…
@answerdotai tq to Claude too for generating the promo tweet for this haha
• • •
Missing some Tweet in this thread? You can try to
force a refresh