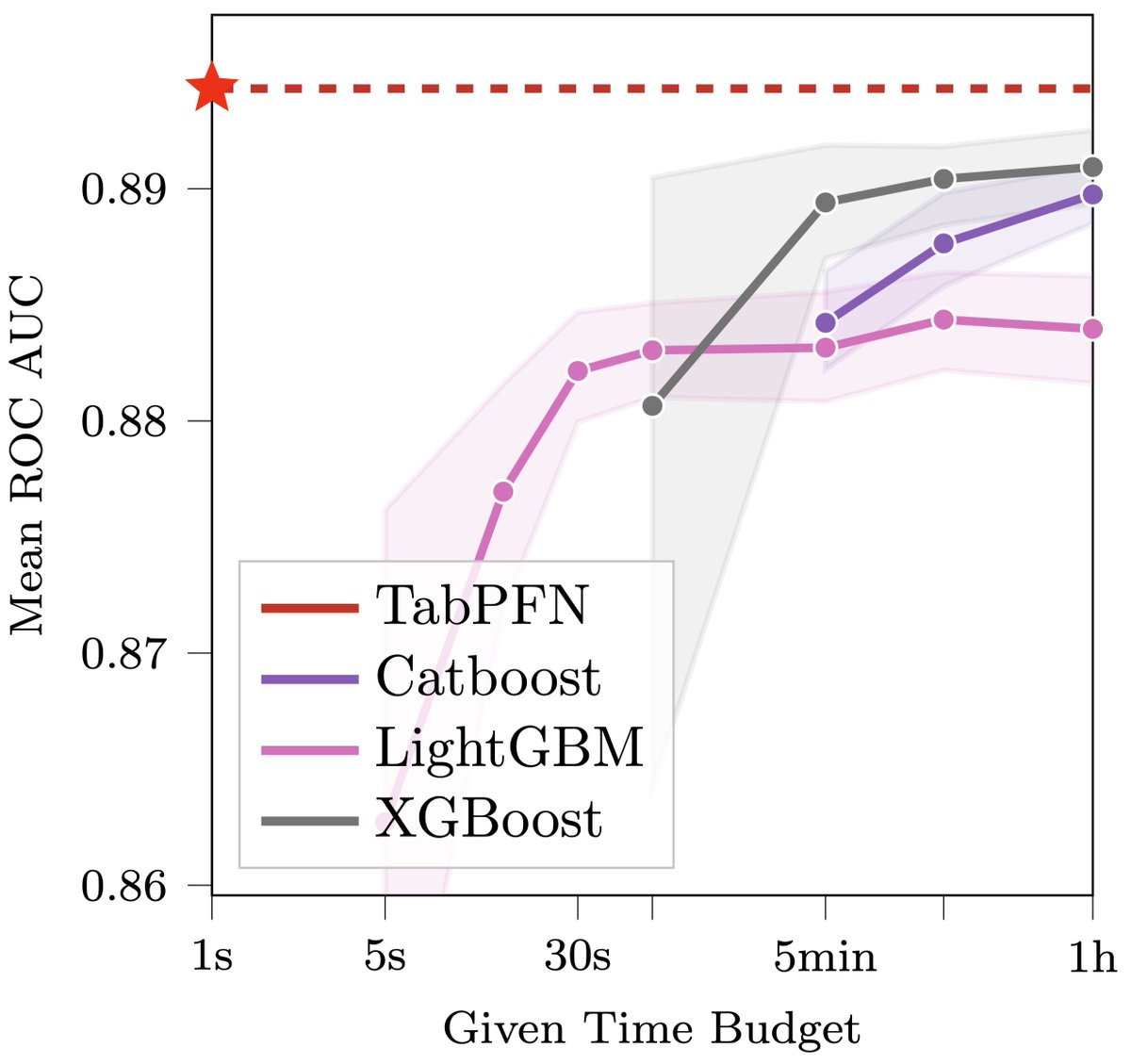
The data science revolution is getting closer. TabPFN v2 is published in Nature: On tabular classification with up to 10k data points & 500 features, in 2.8s TabPFN on average outperforms all other methods, even when tuning them for up to 4 hours🧵1/19 nature.com/articles/s4158…

2/19 Two years ago, I tweeted about TabPFN v1 “This may revolutionize data science”. I meant this as “This line of work may revolutionize tabular ML”. We’re now a step closer to this. Like every model, TabPFN v2 will have failure modes, but it starts to get closer to the promise.
3/19 TabPFN v1 was an eye-opener about the potential of in-context learning for classification, but it had many failure modes. With v2, we improve classification & extend the capabilities to regression (where in 4.8 seconds, it is better than baselines tuned for 4h).

4/19 How does TabPFN work? It is trained on 130 million synthetic tabular prediction datasets to perform in-context learning and output predictive distributions. Each dataset is one meta-datapoint to train the TabPFN weights with SGD.

5/19 In contrast to TabPFN v1, we now natively support categorical features. TabPFN v2 now performs just as well on datasets with and without categorical features.

6/19 In contrast to TabPFN v1, we now natively support missing values. TabPFN v2 now performs just as well on datasets with and without missing values.

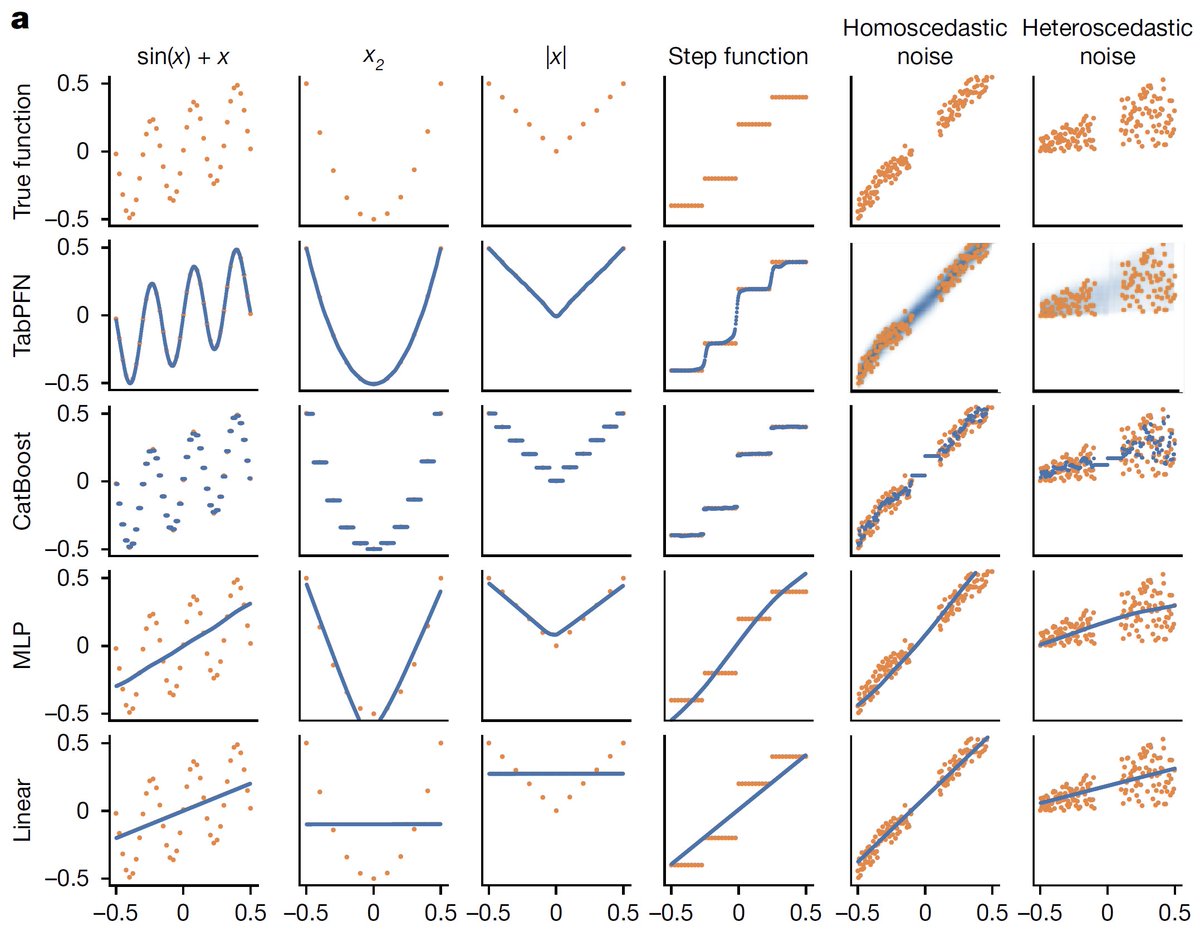
7/19 In contrast to TabPFN v1, we now natively support uninformative features. While these throw off standard neural nets (see the MLP in the figure), TabPFN v2 now handles them naturally.

8/19 TabPFN v2 handles outliers well. Note how dramatically standard MLPs are affected by these.

9/19 TabPFN v2 performs as well with half the data as the next best baseline classifier (CatBoost) performs with all the data. This could be huge for applications where data is very scarce (rare diseases, clinical studies, etc).

10/19 How does TabPFN v2 fare against ensembles of tuned models? We compared it to the state-of-the-art AutoML system AutoGluon 1.0. Standard TabPFN already outperforms AutoGluon on classification, but ensembling multiple TabPFNs in TabPFN v2 (PHE) is even better.

11/19 For regression, standard TabPFN v2 performs on par with AutoGluon, but TabPFN v2 (PHE) still performs better.

12/19 In qualitative instead of quantitative experiments, we show that TabPFNv2 models simple functions more effectively than baseline methods. The orange points indicate the training data, while the blue points represent predictions.
13/19 TabPFN v2 has many foundation model properties, most importantly it can be finetuned to a specific type of datasets (here: sine curves), just like Llama can be finetuned to your text data.

14/19 TabPFN v2 still has some downsides. While it is very fast to train and does not require hyperparameter tuning, inference is slow. There are many ways to handle this better in the future, and we’re actively working on it.
15/19 TabPFN v2 is also only made for datasets up to 10k data points and 500 features. It may do well for some larger datasets, but scaling it up further has not been our focus so far. We’re actively working on this now.
16/19 We are releasing TabPFN under an open license: a derivative of the Apache 2 license with a single modification, adding an enhanced attribution requirement inspired by the Llama 3 license: github.com/PriorLabs/TabP…
17/19 We are also releasing an API to allow computation to happen on our GPUs rather than yours. If you are happy to share your data with us, please use this to help us improve our model: github.com/PriorLabs/tabp…
18/19 Finally, we are committed to building an ecosystem around TabPFN and have created a repository for community contributions: We’re excited about your contributions ❤️github.com/PriorLabs/tabp…
19/19 Overall, we are super excited about TabPFN and hope that it is useful for you, too. We are eager to hear feedback on our Discord channel:
Let’s built something great together 🚀discord.com/invite/VJRuU3b…
Let’s built something great together 🚀discord.com/invite/VJRuU3b…
• • •
Missing some Tweet in this thread? You can try to
force a refresh