
Attention has been the key component for most advances in LLMs, but it can’t scale to long context. Does this mean we need to find an alternative?
Presenting Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time. Titans are more effective than Transformers and modern linear RNNs, and can effectively scale to larger than 2M context window, with better performance than ultra-large models (e.g., GPT4, Llama3-80B).
Presenting Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time. Titans are more effective than Transformers and modern linear RNNs, and can effectively scale to larger than 2M context window, with better performance than ultra-large models (e.g., GPT4, Llama3-80B).

@mirrokni Paper:
Next, I'll discuss our intuition for designing Titans, how we implement them efficiently, and experimental results (i.e., how they perform in different tasks).arxiv.org/pdf/2501.00663…
Next, I'll discuss our intuition for designing Titans, how we implement them efficiently, and experimental results (i.e., how they perform in different tasks).arxiv.org/pdf/2501.00663…
Coming back to the first question, does the limited context window of attention mean we need to find an alternative?
We approach this from the human memory perspective. Our short-term memory is very accurate but with a very limited window (30 seconds). So how do we handle longer context? We use other types of memory systems to store information that might be useful.
We argue that attention, due to its limited context window but accurate dependency modeling, performs as a short-term memory, meaning that we need a neural memory module with the ability to memorize long past to act as a long-term, more persistent, memory.
We approach this from the human memory perspective. Our short-term memory is very accurate but with a very limited window (30 seconds). So how do we handle longer context? We use other types of memory systems to store information that might be useful.
We argue that attention, due to its limited context window but accurate dependency modeling, performs as a short-term memory, meaning that we need a neural memory module with the ability to memorize long past to act as a long-term, more persistent, memory.
But how can we design such a long-term memory?
Our perspective is that a long-term memory needs to efficiently build useful abstraction over histories, continually run, and have the ability to forget.
The main challenge, however, is that memory is responsible for memorization but memorizing the training data might not be helpful at test time, in which the data might be out-of-distribution. So, we need to teach the memory module how/what to remember/forget at test time.
To this end, we pursue the idea of encoding the past history into the parameters of a neural network (similar to TTT) and train an online meta-model that learns how to memorize/forget the data at test time.
Our perspective is that a long-term memory needs to efficiently build useful abstraction over histories, continually run, and have the ability to forget.
The main challenge, however, is that memory is responsible for memorization but memorizing the training data might not be helpful at test time, in which the data might be out-of-distribution. So, we need to teach the memory module how/what to remember/forget at test time.
To this end, we pursue the idea of encoding the past history into the parameters of a neural network (similar to TTT) and train an online meta-model that learns how to memorize/forget the data at test time.
What tokens need to be memorized?
We again approach this from the human memory perspective. Our brain prioritizes event that violates the expectations (being surprising). An event, however, might not consistently surprise us over a long period of time although it is memorable. The reason is that the initial moment is surprising enough to get our attention through a long time frame, leading to memorizing the entire time frame.
We simulate the same process for training our long-term memory. We break the surprise of a token into (1) momentary surprise and (2) (decaying) past surprise. The momentary surprise is then measured by the gradient of the memory with respect to the incoming token, while the past surprise is a decayed cumulative surprise of past tokens:
We again approach this from the human memory perspective. Our brain prioritizes event that violates the expectations (being surprising). An event, however, might not consistently surprise us over a long period of time although it is memorable. The reason is that the initial moment is surprising enough to get our attention through a long time frame, leading to memorizing the entire time frame.
We simulate the same process for training our long-term memory. We break the surprise of a token into (1) momentary surprise and (2) (decaying) past surprise. The momentary surprise is then measured by the gradient of the memory with respect to the incoming token, while the past surprise is a decayed cumulative surprise of past tokens:

How does the memory forget?
We use a weight decay term in our memory update rule. Interestingly, this weight decay can be seen as the generalized of the data-dependent gating in RNNs, using a matrix- or vector-valued memory.
We use a weight decay term in our memory update rule. Interestingly, this weight decay can be seen as the generalized of the data-dependent gating in RNNs, using a matrix- or vector-valued memory.

Is this design parallelizable?
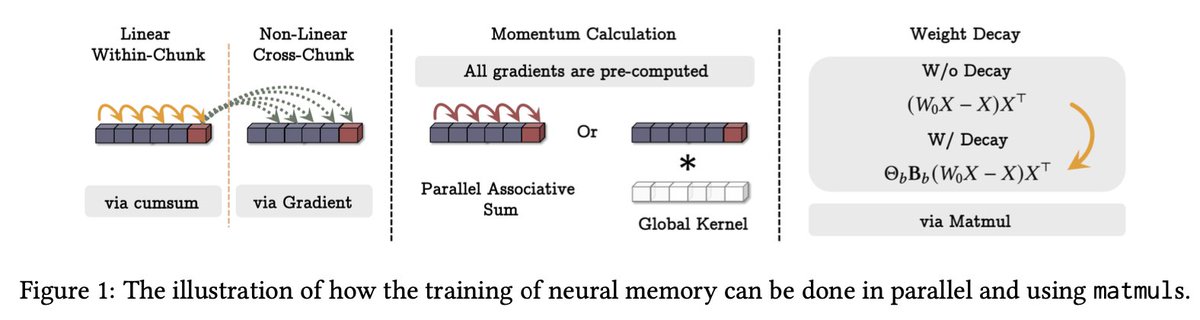
We extend the parallelizable dual formulation of mini-batch gradient descent by TTT (Sun et al., 2024), and incorporate the weight decay by an additional matrix multiplication. What about decaying past surprise? Interestingly, we realize that it can be calculated using a parallel scan in each mini-batch!
We extend the parallelizable dual formulation of mini-batch gradient descent by TTT (Sun et al., 2024), and incorporate the weight decay by an additional matrix multiplication. What about decaying past surprise? Interestingly, we realize that it can be calculated using a parallel scan in each mini-batch!
How to Incorporate Memory? What is the final architecture?
We present three variants of Titans, where we use memory as (1) context, (2) head, or (3) layer. In our experiments, we show that each has its own advantages/disadvantages.
We present three variants of Titans, where we use memory as (1) context, (2) head, or (3) layer. In our experiments, we show that each has its own advantages/disadvantages.



@mirrokni Titans Memory as Context (MAC) architecture segments the input (this can be large even equal to the context window of current attention-based LLMs) and uses the past memory state to extract the corresponding memory. It then updates the memory by the output of the attention.

@mirrokni In our experiments, we focus on language modeling, common-sense reasoning, needle in a haystack, and time series forecasting tasks. Titans are very effective compared to Transformers and modern linear RNNs.



@mirrokni In the BABILong benchmark, Titans (MAC) shows outstanding performance, where it effectively scales to larger than 2M context window, outperforming large models like GPT-4, Llama3 + RAG, and Llama3-70B.

@mirrokni This is a joint work with @mirrokni and Peilin Zhong.
We plan to update the draft to add more retrieval experiments, larger models, and code. Stay tuned for our next version.
We plan to update the draft to add more retrieval experiments, larger models, and code. Stay tuned for our next version.
• • •
Missing some Tweet in this thread? You can try to
force a refresh






