
The DeepSeek R1 training procedure confused me at first. My brain refused to accept this powerful model could be incredibly straightforward.
Let me break down this elegant beast for you 🧵
Let me break down this elegant beast for you 🧵
This multi-stage training loop is unusually effective:
Base → RL → Finetune → RL → Finetune → RL
Does scaling stages = better performance? Let’s break down each phase. 🔍
Base → RL → Finetune → RL → Finetune → RL
Does scaling stages = better performance? Let’s break down each phase. 🔍
V3 Base → R1 Zero (Stage 0/4)
⚙️GRPO: "PPO without a value function using monte carlo estimates of the advantage" - @natolambert
🔍 Data Strategy: Verified prompts via rule-based rewards (IFEval/Tülu 3) + test cases (math/code).
💡Emergent: reasoning/reflection + long CoT.
⚙️GRPO: "PPO without a value function using monte carlo estimates of the advantage" - @natolambert
🔍 Data Strategy: Verified prompts via rule-based rewards (IFEval/Tülu 3) + test cases (math/code).
💡Emergent: reasoning/reflection + long CoT.

R1 Zero → R1 Finetuned Cold Start (Stage 1/4)
🚀Generate 1-10k long CoT samples: Use R1 Zero with few-shot prompting
⚙️Supervised finetuning using model from stage 0
💡Result: Readable thoughts + structured outputs.
🚀Generate 1-10k long CoT samples: Use R1 Zero with few-shot prompting
⚙️Supervised finetuning using model from stage 0
💡Result: Readable thoughts + structured outputs.

R1 Cold Start → R1 Reasoner with RL (Stage 2/4)
🚀Train Stage 1 model with GRPO: Use data from stage 0 and add a language consistency rule (target lang % in CoT).
💡Emergent: readable reasoning with reflection + long CoT.
🚀Train Stage 1 model with GRPO: Use data from stage 0 and add a language consistency rule (target lang % in CoT).
💡Emergent: readable reasoning with reflection + long CoT.

R1 Reasoning → R1 Finetuned-Reasoner (Stage 3/4)
🚀Generate 600k: multi-response sampling and only keep correct samples (using prev rules)
⚙️V3 as a judge: filter out mixed languages, long paragraphs, and code
🌐Generate 200k general-purpose samples via V3
🔥Finetune model
🚀Generate 600k: multi-response sampling and only keep correct samples (using prev rules)
⚙️V3 as a judge: filter out mixed languages, long paragraphs, and code
🌐Generate 200k general-purpose samples via V3
🔥Finetune model
R1 Instruct-Reasoner → R1 Aligned (Stage 4/4)
⚖️Align DeepSeek-R1: Balance reasoning with helpfulness and harmlessness using GRPO
🔍 Data Strategy: rule-based rewards for math/code + reward model for human preferences.
🌟Result: DeepSeek R1
⚖️Align DeepSeek-R1: Balance reasoning with helpfulness and harmlessness using GRPO
🔍 Data Strategy: rule-based rewards for math/code + reward model for human preferences.
🌟Result: DeepSeek R1
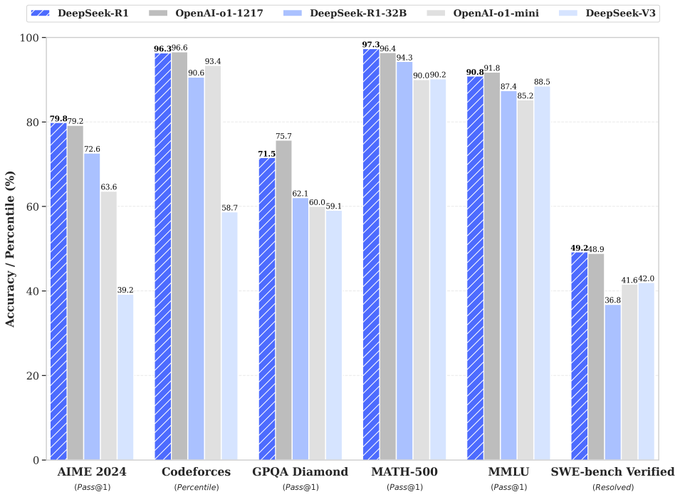
This concludes the breakdown! I have tried to highlight the overall approach while including as many details as possible for your leisure.
Super keen to discuss this paper further and how we can create a proper open-source version!
Super keen to discuss this paper further and how we can create a proper open-source version!
• • •
Missing some Tweet in this thread? You can try to
force a refresh






