Sat in @ieee_isscc session 29: SRAM
1st paper: $TSM 38 Mb/mm2 N2 HD SRAM
2nd paper: $INTC 38 Mb/mm2 18A HD SRAM
3rd paper: @Mediatek 3nm TCAM
4th paper: @Synopsys 38 Mb/mm2 3nm HD SRAM
It's a battle royale.
1st paper: $TSM 38 Mb/mm2 N2 HD SRAM
2nd paper: $INTC 38 Mb/mm2 18A HD SRAM
3rd paper: @Mediatek 3nm TCAM
4th paper: @Synopsys 38 Mb/mm2 3nm HD SRAM
It's a battle royale.
@ieee_isscc @MediaTek @Synopsys Starting with $TSM. Here's the HD SRAM Density trend. 12% gain over N3. GAA helps a lot. 

$TSM: The high performance HC SRAM has a density increase of 18%. 'Double pump' actually means what it means here. Benefits from DTCO

$TSM: Reduce bit-line sweep to reduce power.

$TSM: 6% better HC SRAM - at 100C / 0.9 volts

$TSM: 19% energy efficiency gain. This is important for AI/GPU

$TSM: Dual tracking scheme to improve power and perf

$TSM: These are the test chips. When nodes are in bringup, this is the sort of stuff they're testing.

$TSM: for HD SRAM 2nm, 300mV Vmin reduction in writes due to new write assist

$TSM for high perf, 2nm HC SRAM can enable 4.2 GHz at 1.05 volts or 4.5 GHz at 1.2 volts

Not for $INTC @Intel. 18A has BSPDN as well as GAA, unlike TSM.

@intel $INTC 18A high-density (HDC) and high-performance (HCC) SRAM have big increases. As you can see, better gate control (PD vs PG) enabled by GAA/Ribbons

@intel $INTC: The better gate control and transistor sizing allows for optimized Vmin (same as what we saw with TSM)

@intel $INTC: Powervia enables 10% better density, but electrical benefits are limited: IR droop effect not massive, only marginal improve to RC

@intel $INTC: solution is 'Around-the-Array' Powervia scheme.

@intel $INTC: Not sure how this affects density now, but here's the effect on perf in the worst case scenarios.
A is longest delay due to length,
B is biggest IR drop due to distance from PowerVia.
A is longest delay due to length,
B is biggest IR drop due to distance from PowerVia.

$INTC: Other density improvement due to NBL circuit design optimization - reuse backside metal for cap

End result - macro bit density increase to 38.1 Mb/mm2 in best case. There are a number of different options with different densities depending on use case. (Same with other foundry even if not explicitly mentioned)

$INTC 18A SRAM test chip. Interleaved HDC/HCC block macros

$INTC: Vmin improved by 100mV (HDC) and 90mV (HCC). However here's the shmoo: 5.6 GHz at 1.05 volts!
Sounds amazing - this is the 256/136 SRAM cell at 34.1 Mb/mm2 version, not full density 38.1 Mb/mm2. TSM used best case result as well (512x64 rather than 4096x64). It shows there's a tradeoff of density and performance.
Sounds amazing - this is the 256/136 SRAM cell at 34.1 Mb/mm2 version, not full density 38.1 Mb/mm2. TSM used best case result as well (512x64 rather than 4096x64). It shows there's a tradeoff of density and performance.

@SquashBionic @intel Huh can't edit tweets in a stream. But you're right, I missed that. When I do proper coverage, will correct
Next up, Mediatek's TCAM. Shame it's not the highlight of the session given the strong competition - it's lower density (~5 Mb/mm2), but optimized for power for ML. @Mediatek has been on a tear by turning the knob towards efficiency, regardless of density.
Will wait until the Intel presenter finishes first and MTK starts.
Will wait until the Intel presenter finishes first and MTK starts.
@MediaTek Here's the phone I purchased based on Mediatek's presentation last year about L1 perf vs density. It was two slides in a presentation, but my mind was blown.
Had the Intel Q&A, some substantially veteran guy from Etron started bitching about the process being called 18A and what makes it 18A. The audience groaned - a waste of the *only* question the session had time for.
When an engineer meets marketing. This isn't the forum for this.
When an engineer meets marketing. This isn't the forum for this.
Ok, let's start with MTK. For some context - TCAM is vital for data center networks - switches and routers. Use memory that is optimized for fast-parallel lookup and rule storage.

MTK: TCAM is a dual 6T SRAM design with 4T-NMOS comparison circuit. Overall 16T bitcell, but same read/write as 6T-SRAM

MTK: Here's the architecture. Way over my head, but see if you can spot the unfortunate name in this slide.

MTK: Correction, that slide was the baseline architecture. Here's the new architecture optimized for DGSL.

MTK: 16-37% savings in power.

MTK: Test Chip in 3nm FF

MTK: Comparison to previous work.

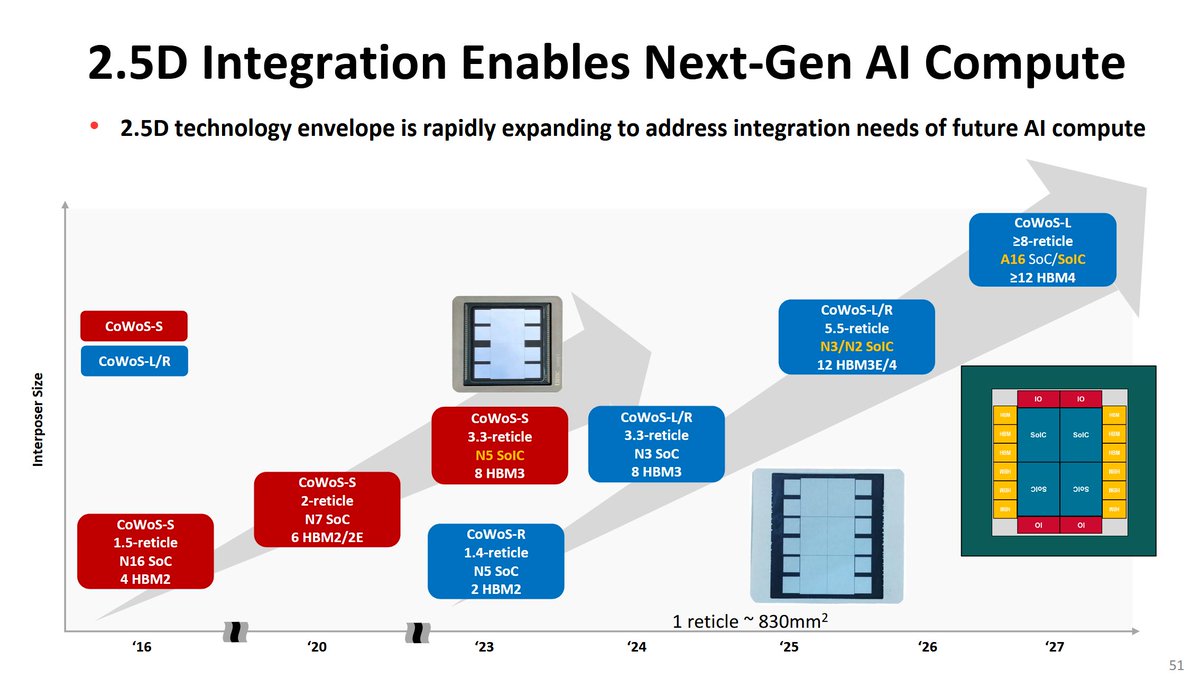
Next session is @Synopsys. Looking forward to seeing how they matched N2/18A density in 3nm FinFET - arguably more impressive out of the four on the face.
@Synopsys So this paper is over my head by quite a way. It's a dual rail SRAM, so two power sources from SRAM to SoC. Important here is ERLS: Extended Range Level Shifter.

@Synopsys Extending SRAM density and enable logic-limited Vmin. Here we have a level shifter upgraded to ERLS and ERLS with Latch Integration. You can reduce delay with a bypass if needed.
Part of the increased density design uses NFETs which are smaller than PFETs, apparently.
Part of the increased density design uses NFETs which are smaller than PFETs, apparently.




@Synopsys The end result is this. The VDDmin and VDDAmin lines are straight, making it easier to characterize.

@Synopsys Test chip. Here's where the 38 Mb/mm2 comes from. Maximum frequency seems to be 2.325 GHz at 25C.

That's a wrap for the session. After the break is NVM and DRAM. I'm interested in 400+ layer TLC, but also what in the world is LPDDR5-Ultra-Pro ?

• • •
Missing some Tweet in this thread? You can try to
force a refresh