Say goodbye to Chain-of-Thought.
Say hello to Chain-of-Draft.
To address the issue of latency in reasoning LLMs, this work introduces Chain-of-Draft (CoD).
Read on for more:
Say hello to Chain-of-Draft.
To address the issue of latency in reasoning LLMs, this work introduces Chain-of-Draft (CoD).
Read on for more:

What is it about?
CoD is a new prompting strategy that drastically cuts down verbose intermediate reasoning while preserving strong performance.
CoD is a new prompting strategy that drastically cuts down verbose intermediate reasoning while preserving strong performance.
Minimalist intermediate drafts
Instead of long step-by-step CoT outputs, CoD asks the model to generate concise, dense-information tokens for each reasoning step.
This yields up to 80% fewer tokens per response yet maintains accuracy on math, commonsense, and other benchmarks.
Instead of long step-by-step CoT outputs, CoD asks the model to generate concise, dense-information tokens for each reasoning step.
This yields up to 80% fewer tokens per response yet maintains accuracy on math, commonsense, and other benchmarks.

Low latency, high accuracy
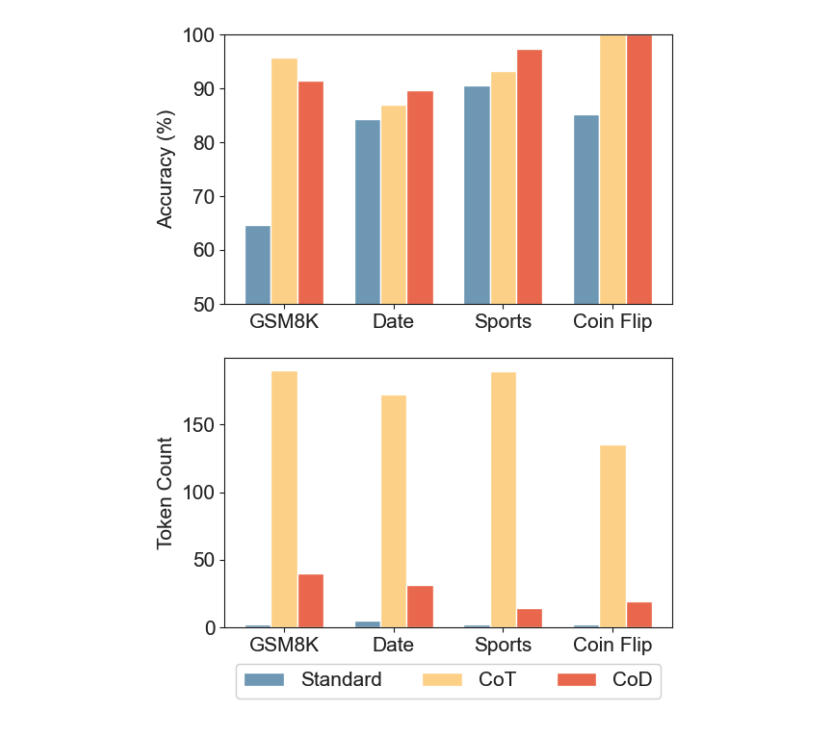
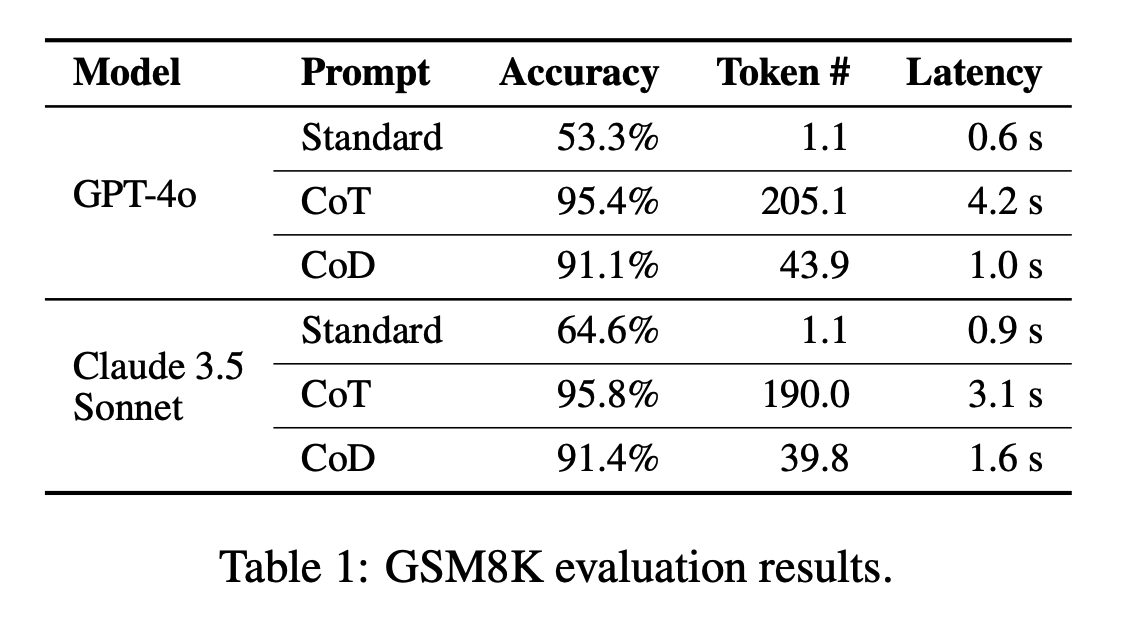
On GSM8k math problems, CoD achieved 91% accuracy with an 80% token reduction compared to CoT. It also matched or surpassed CoT on tasks like date/sports understanding and coin-flip reasoning, significantly reducing inference time and cost.
On GSM8k math problems, CoD achieved 91% accuracy with an 80% token reduction compared to CoT. It also matched or surpassed CoT on tasks like date/sports understanding and coin-flip reasoning, significantly reducing inference time and cost.
Flexible & interpretable
Despite fewer words, CoD keeps the essential logic visible, similar to how humans jot down key points instead of full explanations. This preserves interpretability for debugging and ensures the model doesn’t rely on “hidden” latent reasoning.
Despite fewer words, CoD keeps the essential logic visible, similar to how humans jot down key points instead of full explanations. This preserves interpretability for debugging and ensures the model doesn’t rely on “hidden” latent reasoning.

Thoughts:
By showing that less is more, CoD can serve real-time applications where cost and speed matter. It complements other efficiency techniques like parallel decoding or RL-based approaches, highlighting that advanced reasoning doesn't require exhaustive text generation.
By showing that less is more, CoD can serve real-time applications where cost and speed matter. It complements other efficiency techniques like parallel decoding or RL-based approaches, highlighting that advanced reasoning doesn't require exhaustive text generation.
• • •
Missing some Tweet in this thread? You can try to
force a refresh