Universal RAG
RAG is dead, they said.
Then you see papers like this and it gives you a better understanding of the opportunities and challenges ahead.
Lots of great ideas in this paper. I've summarized a few below:
RAG is dead, they said.
Then you see papers like this and it gives you a better understanding of the opportunities and challenges ahead.
Lots of great ideas in this paper. I've summarized a few below:
What is it?
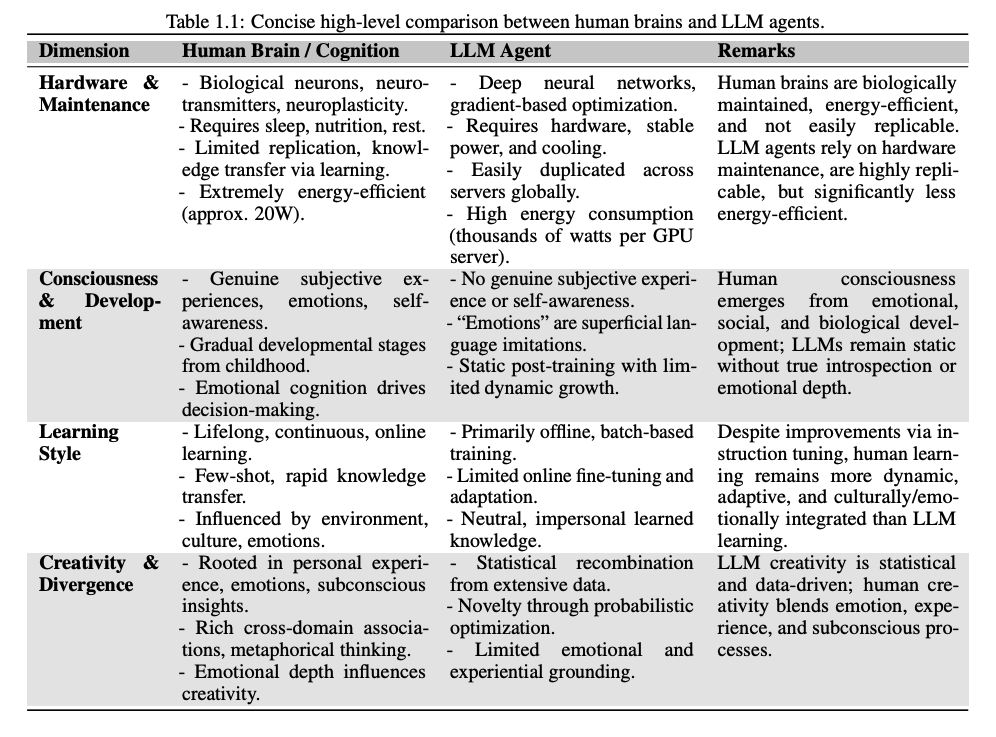
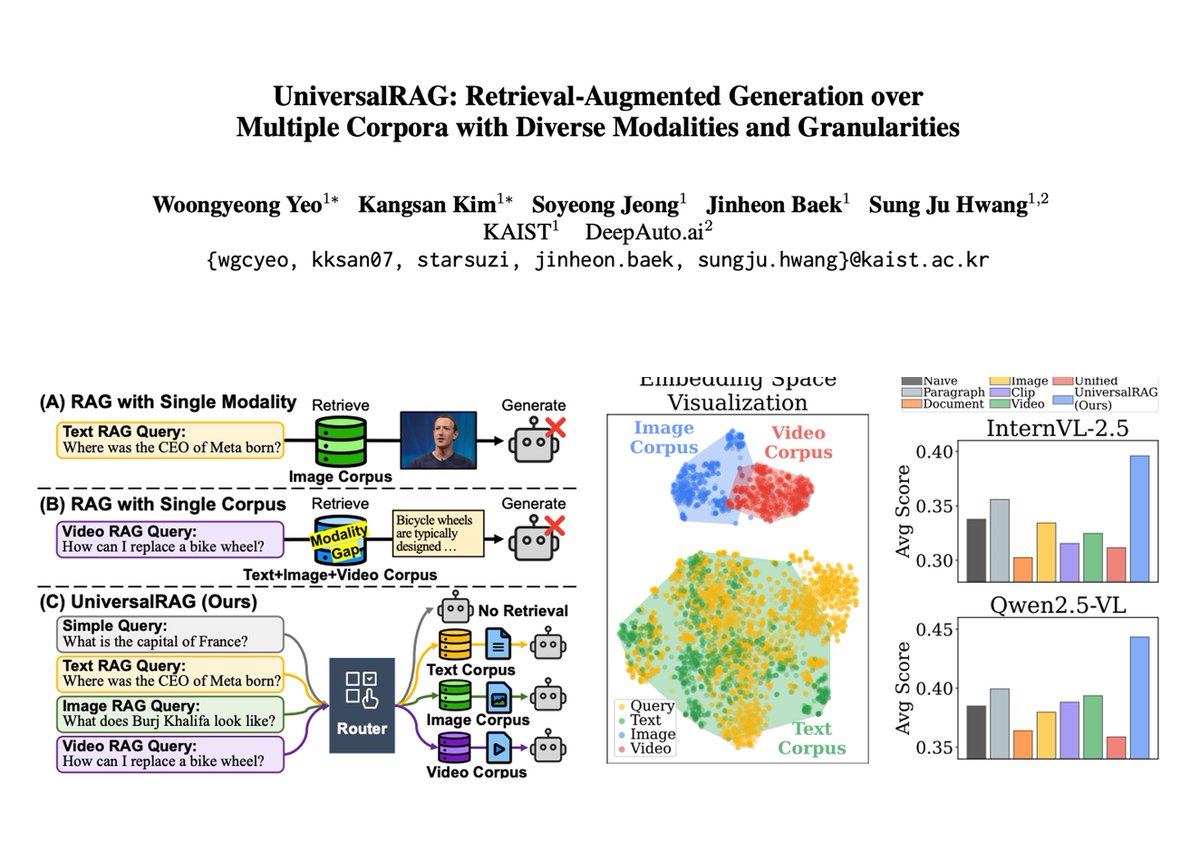
UniversalRAG is a framework that overcomes the limitations of existing RAG systems confined to single modalities or corpora. It supports retrieval across modalities (text, image, video) and at multiple granularities (e.g., paragraph vs. document, clip vs. video).
UniversalRAG is a framework that overcomes the limitations of existing RAG systems confined to single modalities or corpora. It supports retrieval across modalities (text, image, video) and at multiple granularities (e.g., paragraph vs. document, clip vs. video).
Modality-aware routing
To counter modality bias in unified embedding spaces (where queries often retrieve same-modality results regardless of relevance), UniversalRAG introduces a router that dynamically selects the appropriate modality (e.g., image vs. text) for each query.
To counter modality bias in unified embedding spaces (where queries often retrieve same-modality results regardless of relevance), UniversalRAG introduces a router that dynamically selects the appropriate modality (e.g., image vs. text) for each query.
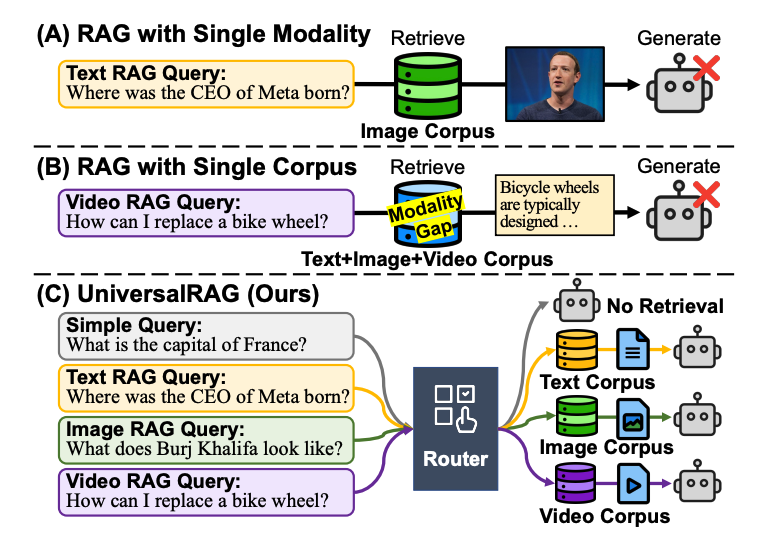
Granularity-aware retrieval
Each modality is broken into granularity levels (e.g., paragraphs vs. documents for text, clips vs. full-length videos). This allows queries to retrieve content that matches their complexity -- factual queries use short segments while complex reasoning accesses long-form data.
Each modality is broken into granularity levels (e.g., paragraphs vs. documents for text, clips vs. full-length videos). This allows queries to retrieve content that matches their complexity -- factual queries use short segments while complex reasoning accesses long-form data.
Flexible routing
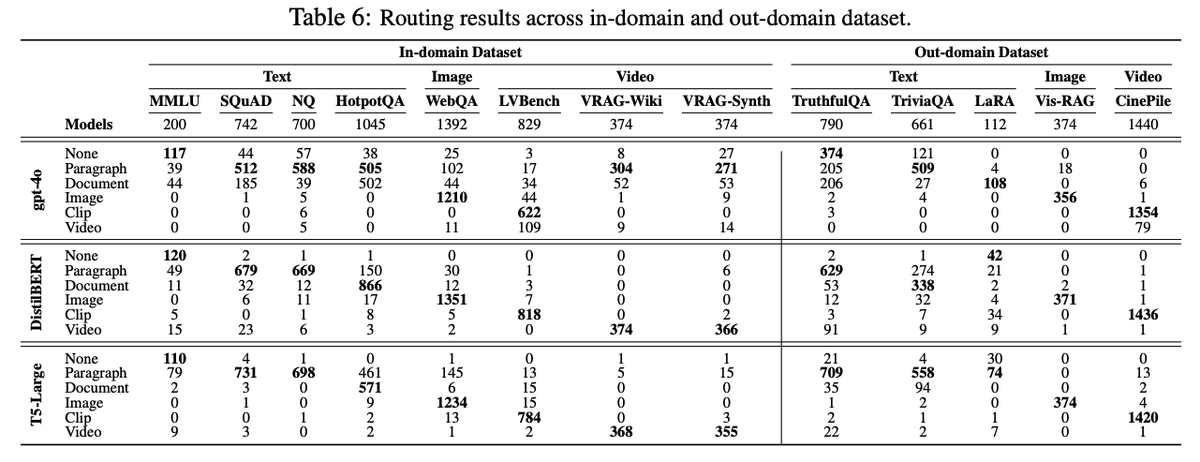
It supports both training-free (zero-shot GPT-4o prompting) and trained (T5-Large) routers. Trained routers perform better on in-domain data, while GPT-4o generalizes better to out-of-domain tasks. An ensemble router combines both for robust performance.
It supports both training-free (zero-shot GPT-4o prompting) and trained (T5-Large) routers. Trained routers perform better on in-domain data, while GPT-4o generalizes better to out-of-domain tasks. An ensemble router combines both for robust performance.
Performance
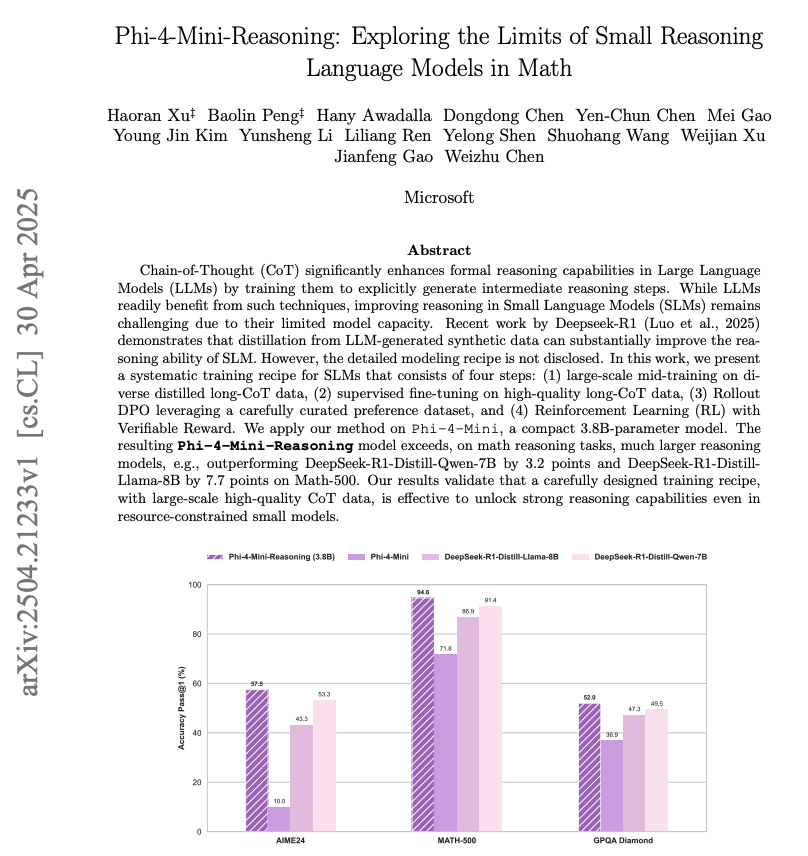
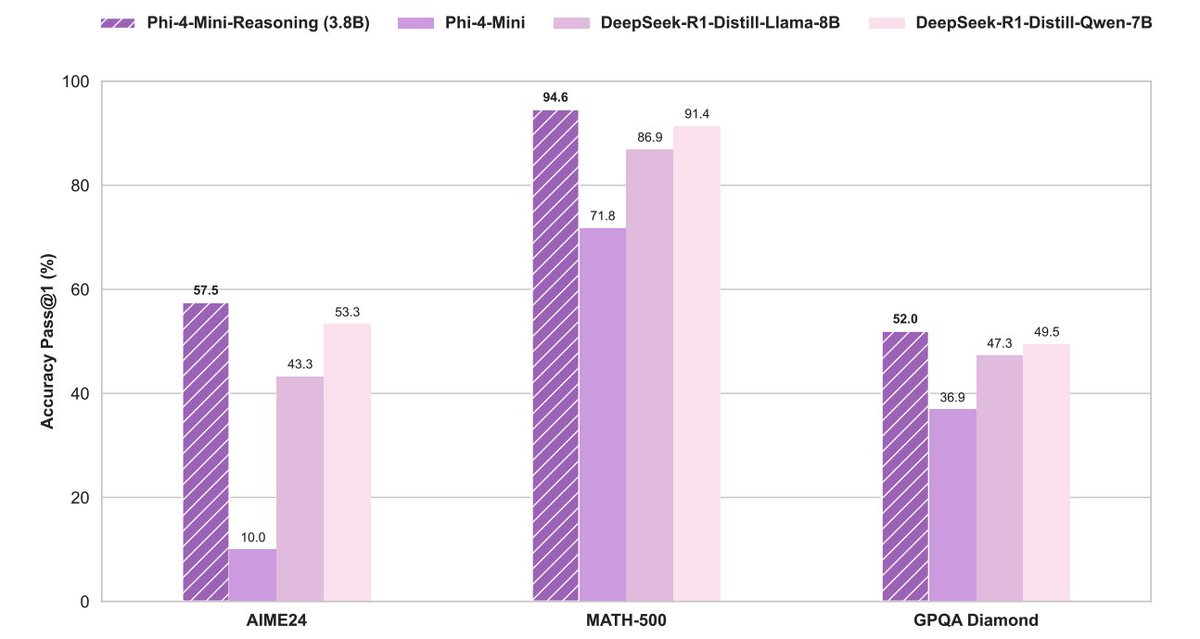
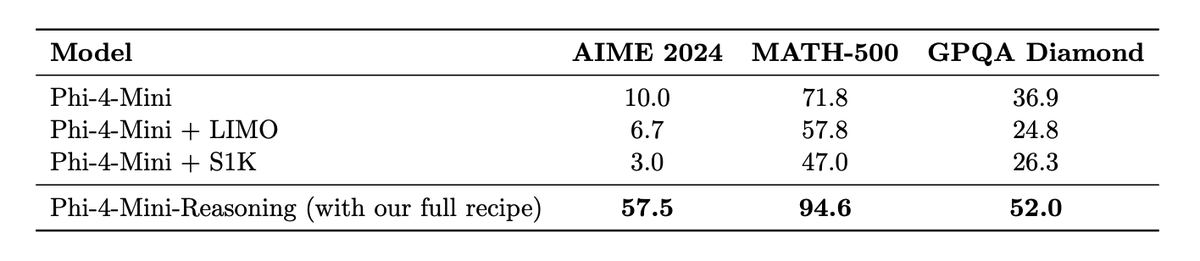
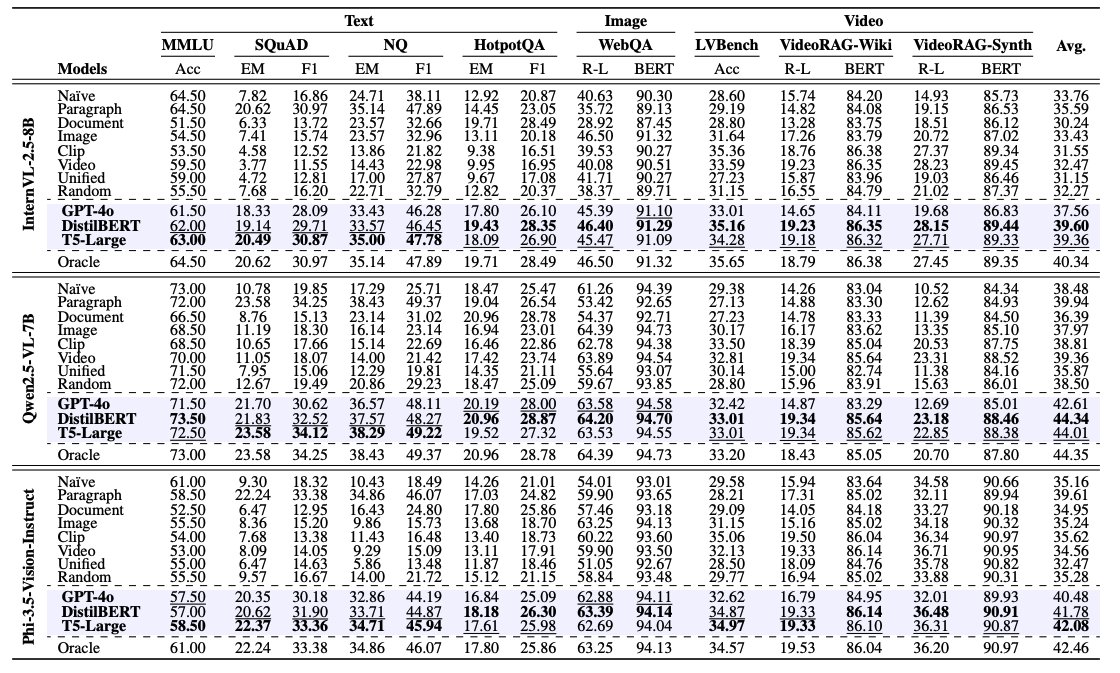
UniversalRAG outperforms modality-specific and unified RAG baselines across 8 benchmarks spanning text (e.g., MMLU, SQuAD), image (WebQA), and video (LVBench, VideoRAG). With T5-Large, it achieves the highest average score across modalities.
UniversalRAG outperforms modality-specific and unified RAG baselines across 8 benchmarks spanning text (e.g., MMLU, SQuAD), image (WebQA), and video (LVBench, VideoRAG). With T5-Large, it achieves the highest average score across modalities.
Case study
In WebQA, UniversalRAG correctly routes a visual query to the image corpus (retrieving an actual photo of the event), while TextRAG and VideoRAG fail. Similarly, on HotpotQA and LVBench, it chooses the right granularity, retrieving documents or short clips.
Overall, this is a great paper showing the importance of considering modality and granularity in a RAG system.
Paper:
arxiv.org/abs/2504.20734
In WebQA, UniversalRAG correctly routes a visual query to the image corpus (retrieving an actual photo of the event), while TextRAG and VideoRAG fail. Similarly, on HotpotQA and LVBench, it chooses the right granularity, retrieving documents or short clips.
Overall, this is a great paper showing the importance of considering modality and granularity in a RAG system.
Paper:
arxiv.org/abs/2504.20734
• • •
Missing some Tweet in this thread? You can try to
force a refresh