
I’m stoked to share our new paper: “Harnessing the Universal Geometry of Embeddings” with @jxmnop, Collin Zhang, and @shmatikov.
We present the first method to translate text embeddings across different spaces without any paired data or encoders.
Here's why we're excited: 🧵👇🏾
We present the first method to translate text embeddings across different spaces without any paired data or encoders.
Here's why we're excited: 🧵👇🏾

🌀 Preserving Geometry
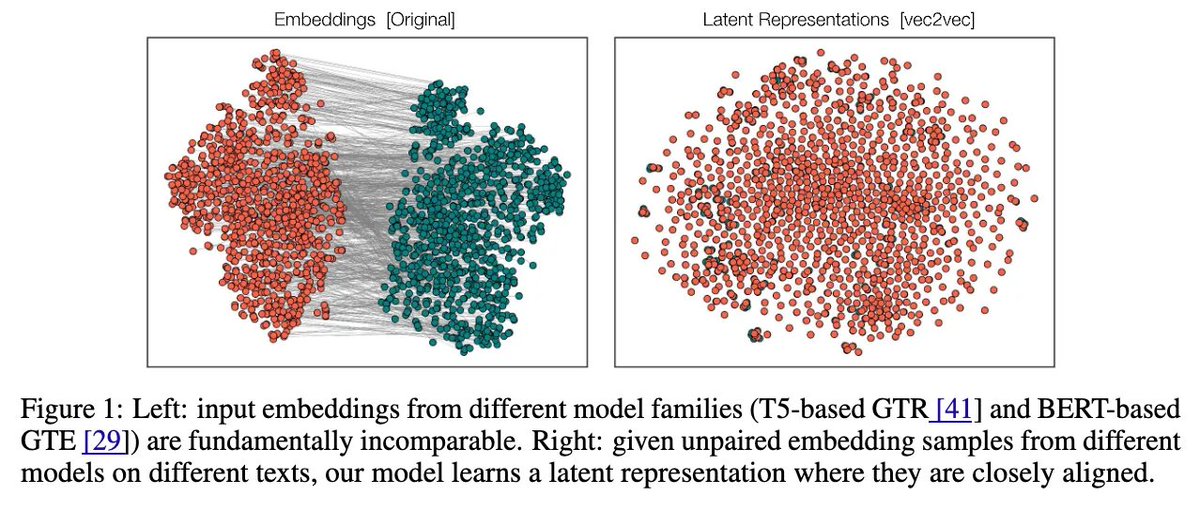
Our method, vec2vec, reveals that all encoders—regardless of architecture or training data—learn nearly the same representations!
We demonstrate how to translate between these black-box embeddings without any paired data, maintaining high fidelity. (2/5)
Our method, vec2vec, reveals that all encoders—regardless of architecture or training data—learn nearly the same representations!
We demonstrate how to translate between these black-box embeddings without any paired data, maintaining high fidelity. (2/5)
🔐 Security Implications
Using vec2vec, we show that vector databases reveal (almost) as much as their inputs.
Given just vectors (e.g., from a compromised vector database), we show that an adversary can extract sensitive information (e.g., PII) about the underlying text. (3/5)
Using vec2vec, we show that vector databases reveal (almost) as much as their inputs.
Given just vectors (e.g., from a compromised vector database), we show that an adversary can extract sensitive information (e.g., PII) about the underlying text. (3/5)

🧠 Strong Platonic Representation Hypothesis (S-PRH)
We thus strengthen Huh et al.'s PRH to say:
The universal latent structure of text representations can be learned and harnessed to translate representations from one space to another without any paired data or encoders. (4/5)
We thus strengthen Huh et al.'s PRH to say:
The universal latent structure of text representations can be learned and harnessed to translate representations from one space to another without any paired data or encoders. (4/5)

📄 Read the Full Paper
Dive into the details here:
We welcome feedback and discussion! (5/5) arxiv.org/pdf/2505.12540
Dive into the details here:
We welcome feedback and discussion! (5/5) arxiv.org/pdf/2505.12540

• • •
Missing some Tweet in this thread? You can try to
force a refresh



