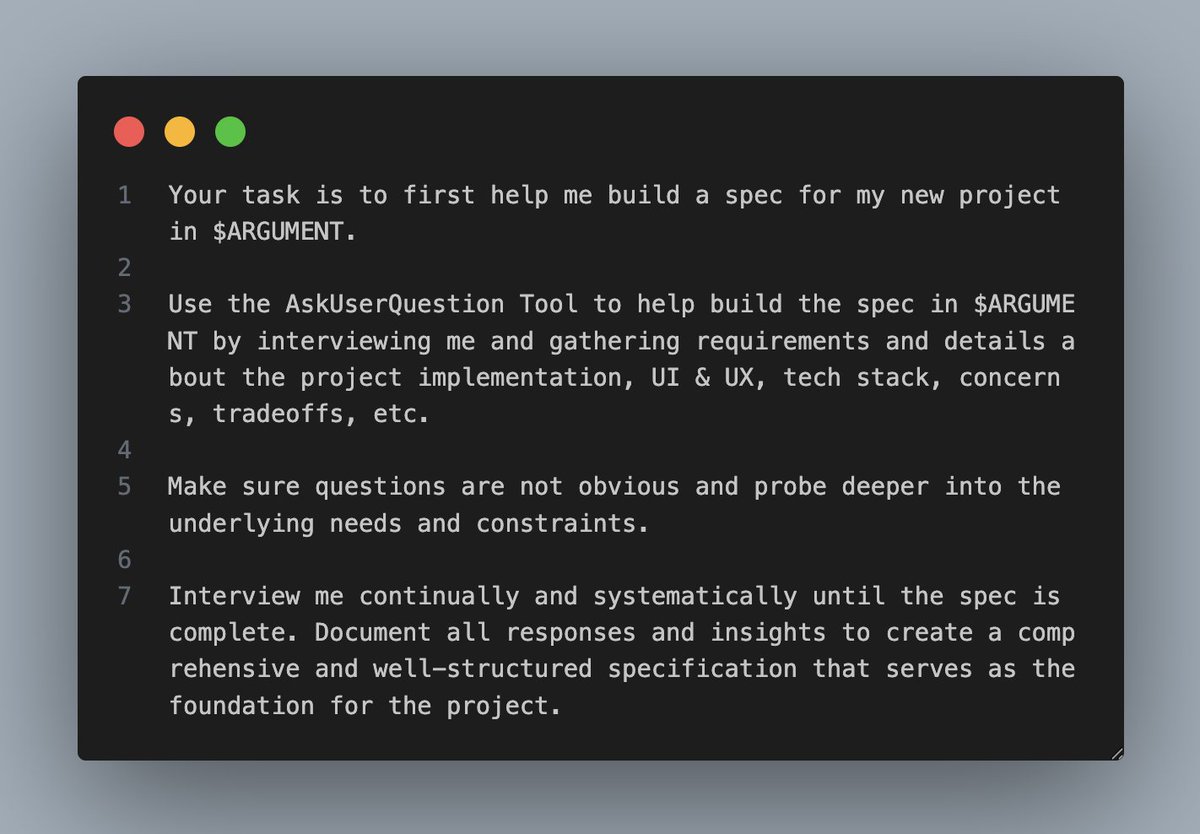
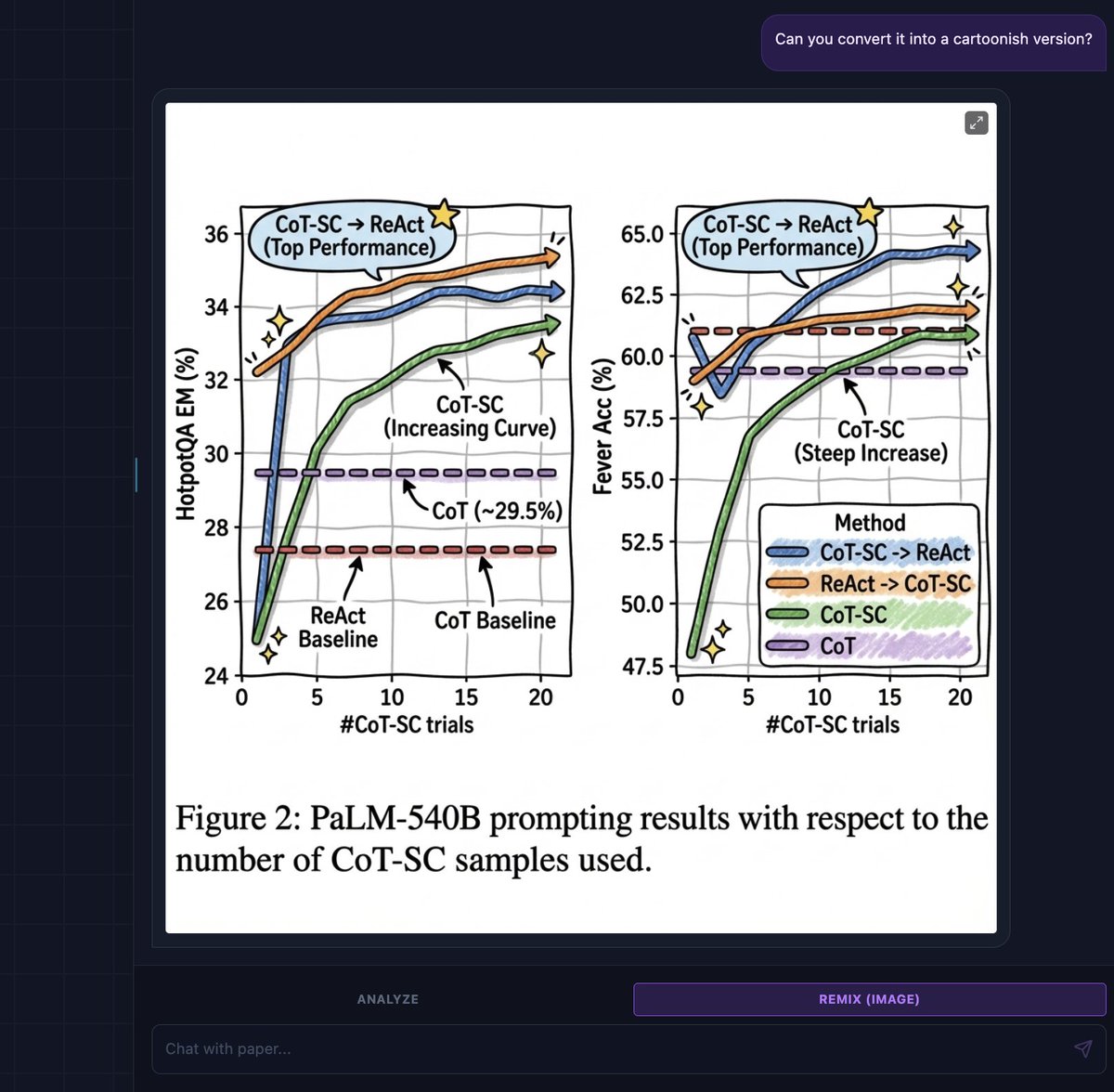
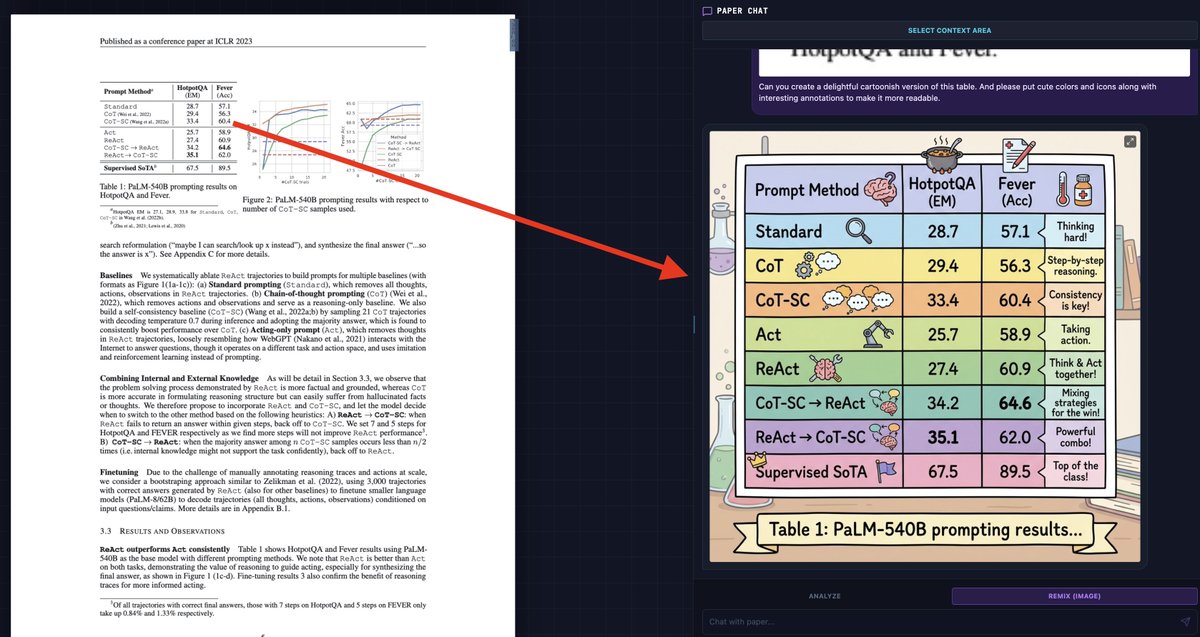
Small Language Models are the Future of Agentic AI
Lots to gain from building agentic systems with small language models.
Capabilities are increasing rapidly!
AI devs should be exploring SLMs.
Here are my notes:
Lots to gain from building agentic systems with small language models.
Capabilities are increasing rapidly!
AI devs should be exploring SLMs.
Here are my notes:

Overview
This position paper argues that small language models (SLMs), defined pragmatically as those runnable on consumer-grade hardware, are not only sufficient but superior for many agentic AI applications, especially when tasks are narrow, repetitive, or tool-oriented.
This position paper argues that small language models (SLMs), defined pragmatically as those runnable on consumer-grade hardware, are not only sufficient but superior for many agentic AI applications, especially when tasks are narrow, repetitive, or tool-oriented.

The authors propose that shifting from LLM-first to SLM-first architectures will yield major gains in efficiency, modularity, and sustainability.
SLMs are already capable of commonsense reasoning, instruction following, and code/tool interaction at levels comparable to 30–70B models, with orders of magnitude better throughput.
Examples include Phi-3, Hymba-1.5B, DeepSeek-R1-Distill, and RETRO-7.5B.
Examples include Phi-3, Hymba-1.5B, DeepSeek-R1-Distill, and RETRO-7.5B.

The economic benefits are significant: SLMs offer 10–30× lower inference cost than LLMs, require less parallel infrastructure, and are amenable to overnight fine-tuning and even edge deployment (e.g., ChatRTX).
This enables faster iteration and better data control.
This enables faster iteration and better data control.
SLMs support modular, composable agent systems where specialized models handle subtasks, resulting in better alignment, lower risk of hallucinations, and easier debugging.
The authors advocate for heterogeneous architectures, with SLMs as defaults and LLMs used selectively.
The authors advocate for heterogeneous architectures, with SLMs as defaults and LLMs used selectively.

A six-step LLM-to-SLM conversion algorithm is proposed, involving usage logging, task clustering, and PEFT fine-tuning.
This supports gradual migration from monolithic agents to SLM-based compositions.
This supports gradual migration from monolithic agents to SLM-based compositions.

Case studies on MetaGPT, Open Operator, and Cradle suggest 40–70% of LLM invocations can be reliably replaced with SLMs, particularly for structured generation and routine tool use.
LLMs retain an advantage in general language understanding, and that economic inertia favors their continued use, but this paper makes a compelling case that SLM-centric systems better reflect real-world agentic requirements and resource constraints.
Paper: arxiv.org/abs/2506.02153
LLMs retain an advantage in general language understanding, and that economic inertia favors their continued use, but this paper makes a compelling case that SLM-centric systems better reflect real-world agentic requirements and resource constraints.
Paper: arxiv.org/abs/2506.02153

• • •
Missing some Tweet in this thread? You can try to
force a refresh