
I was one of the 16 devs in this study. I wanted to speak on my opinions about the causes and mitigation strategies for dev slowdown.
I'll say as a "why listen to you?" hook that I experienced a -38% AI-speedup on my assigned issues. I think transparency helps the community.
I'll say as a "why listen to you?" hook that I experienced a -38% AI-speedup on my assigned issues. I think transparency helps the community.
https://twitter.com/METR_Evals/status/1943360399220388093
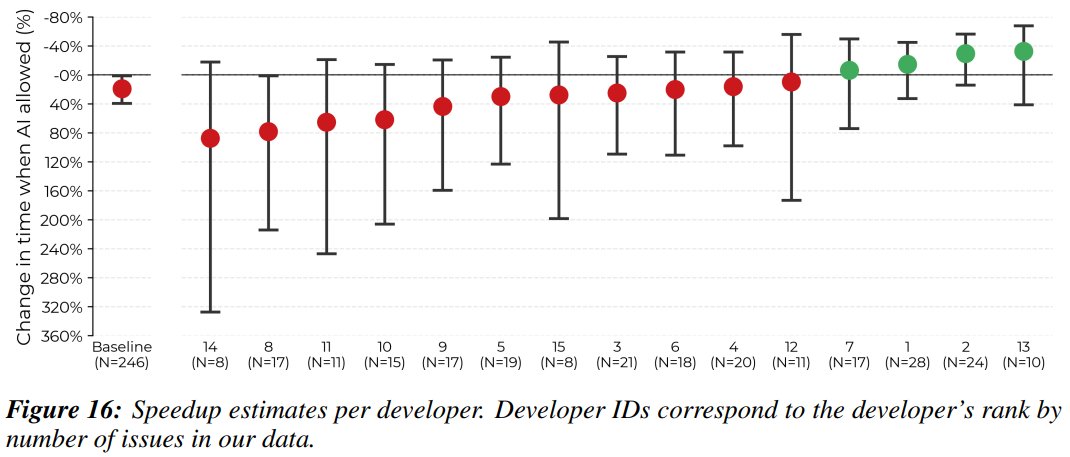
Firstly, I think AI speedup is very weakly correlated to anyone's ability as a dev. All the devs in this study are very good. I think it has more to do with falling into failure modes, both in the LLM's ability and the human's workflow. I work with a ton of amazing pretraining devs, and I think people face many of the same problems.
We like to say that LLMs are tools, but treat them more like a magic bullet.
Literally any dev can attest to the satisfaction from finally debugging a thorny issue. LLMs are a big dopamine shortcut button that may one-shot your problem. Do you keep pressing the button that has a 1% chance of fixing everything? It's a lot more enjoyable than the grueling alternative, at least to me.
We like to say that LLMs are tools, but treat them more like a magic bullet.
Literally any dev can attest to the satisfaction from finally debugging a thorny issue. LLMs are a big dopamine shortcut button that may one-shot your problem. Do you keep pressing the button that has a 1% chance of fixing everything? It's a lot more enjoyable than the grueling alternative, at least to me.
I think cases of LLM-overuse can happen because it's easy to optimize for perceived enjoyment rather than time-to-solution while working.
Me pressing tab in cursor for 5 hours instead of debugging for 1:
Me pressing tab in cursor for 5 hours instead of debugging for 1:
Second, LLMs today have super spiky capability distributions. I think this has more to do with: 1) what coding tasks we have lots of clean data for, and 2) what benchmarks/evals LLM labs are using to measure success.
As an example, LLMs are all horrible at low-level systems code (GPU kernels, parallelism/communication, etc). This is because their code data is relatively rare, and evaluating model capabilities is hard for these (I discuss this in more detail at github.com/Quentin-Anthon…).
Since these tasks are a large part of what I do as a pretraining dev, I know what parts of my work are amenable to LLMs (writing tests, understanding unfamiliar code, etc) and which are not (writing kernels, understanding communication synchronization semantics, etc). I only use LLMs when I know they can reliably handle the task.
When determining whether some new task is amenable to an LLM, I try to aggressively time-box my time working with the LLM so that I don't go down a rabbit hole. Again, tearing yourself away from an LLM when "it's just so close!" is hard!
As an example, LLMs are all horrible at low-level systems code (GPU kernels, parallelism/communication, etc). This is because their code data is relatively rare, and evaluating model capabilities is hard for these (I discuss this in more detail at github.com/Quentin-Anthon…).
Since these tasks are a large part of what I do as a pretraining dev, I know what parts of my work are amenable to LLMs (writing tests, understanding unfamiliar code, etc) and which are not (writing kernels, understanding communication synchronization semantics, etc). I only use LLMs when I know they can reliably handle the task.
When determining whether some new task is amenable to an LLM, I try to aggressively time-box my time working with the LLM so that I don't go down a rabbit hole. Again, tearing yourself away from an LLM when "it's just so close!" is hard!
Along this point, there's a long tail of issues that cause an LLM to choke:
- "Context rot", where models become distracted by long+irrelevant contexts (especially from long conversations). See x.com/simonw/status/…. You need to open a new chat often. This effect is worsened if users try to chase dopamine, because "the model is so close to getting it right!" means you don't want to open a new chat when you feel close.
- Training data distribution. I won't pretend to know any of Claude/Gemini/ChatGPT/Grok/R1's data distributions, but some models are better at specific languages/tasks and I use them to their strengths. Unfortunately, I only know what model maps to which part of my personal workflow from asking lots of different models the same questions whose answers I roughly know. E.g. I may use Gemini-2.5 pro for initial code understanding, o3 to help with the core implementation, and then Claude 4 Sonnet to shorten my solution and check for bugs. Tools like cursor often don't let me see what's going into context, so I don't use them. My mental model on what this specific model is good at, or can tolerate, breaks down. I use model APIs directly through my IDE or a local chat interface. Doesn't mean this is the "correct" way, just what works for me :)
- "Context rot", where models become distracted by long+irrelevant contexts (especially from long conversations). See x.com/simonw/status/…. You need to open a new chat often. This effect is worsened if users try to chase dopamine, because "the model is so close to getting it right!" means you don't want to open a new chat when you feel close.
- Training data distribution. I won't pretend to know any of Claude/Gemini/ChatGPT/Grok/R1's data distributions, but some models are better at specific languages/tasks and I use them to their strengths. Unfortunately, I only know what model maps to which part of my personal workflow from asking lots of different models the same questions whose answers I roughly know. E.g. I may use Gemini-2.5 pro for initial code understanding, o3 to help with the core implementation, and then Claude 4 Sonnet to shorten my solution and check for bugs. Tools like cursor often don't let me see what's going into context, so I don't use them. My mental model on what this specific model is good at, or can tolerate, breaks down. I use model APIs directly through my IDE or a local chat interface. Doesn't mean this is the "correct" way, just what works for me :)
Third, it's super easy to get distracted in the downtime while LLMs are generating. The social media attention economy is brutal, and I think people spend 30 mins scrolling while "waiting" for their 30-second generation.
All I can say on this one is that we should know our own pitfalls and try to fill this LLM-generation time productively:
- If the task requires high-focus, spend this time either working on a subtask or thinking about followup questions. Even if the model one-shots your question, what else don't I understand?
- If the task requires low-focus, do another small task in the meantime (respond to email/slack, read or edit another paragraph, etc).
As always, small digital hygiene steps help with this (website blockers, phone on dnd, etc). Sorry to be a grampy, but it works for me :)
All I can say on this one is that we should know our own pitfalls and try to fill this LLM-generation time productively:
- If the task requires high-focus, spend this time either working on a subtask or thinking about followup questions. Even if the model one-shots your question, what else don't I understand?
- If the task requires low-focus, do another small task in the meantime (respond to email/slack, read or edit another paragraph, etc).
As always, small digital hygiene steps help with this (website blockers, phone on dnd, etc). Sorry to be a grampy, but it works for me :)
LLMs are a tool, and we need to start learning its pitfalls and have some self-awareness. A big reason people enjoy @karpathy's talks is because he's a highly introspective LLM user, which he arrived at a bit early due to his involvement in pretraining some of them.
If we expect to use this new tool well, we need to understand its (and our own!) shortcomings and adapt to them.
If we expect to use this new tool well, we need to understand its (and our own!) shortcomings and adapt to them.
Some final statements:
- METR is a wonderful organization to work with, and they are strong scientists. I've loved both participating in this study and reading their results.
- I am not some LLM guru trying to preach. Think of this as me publishing a personal diary entry, and hoping that others can benefit from my introspection.
- METR is a wonderful organization to work with, and they are strong scientists. I've loved both participating in this study and reading their results.
- I am not some LLM guru trying to preach. Think of this as me publishing a personal diary entry, and hoping that others can benefit from my introspection.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



