A Survey of Context Engineering
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes:
160+ pages covering the most important research around context engineering for LLMs.
This is a must-read!
Here are my notes:

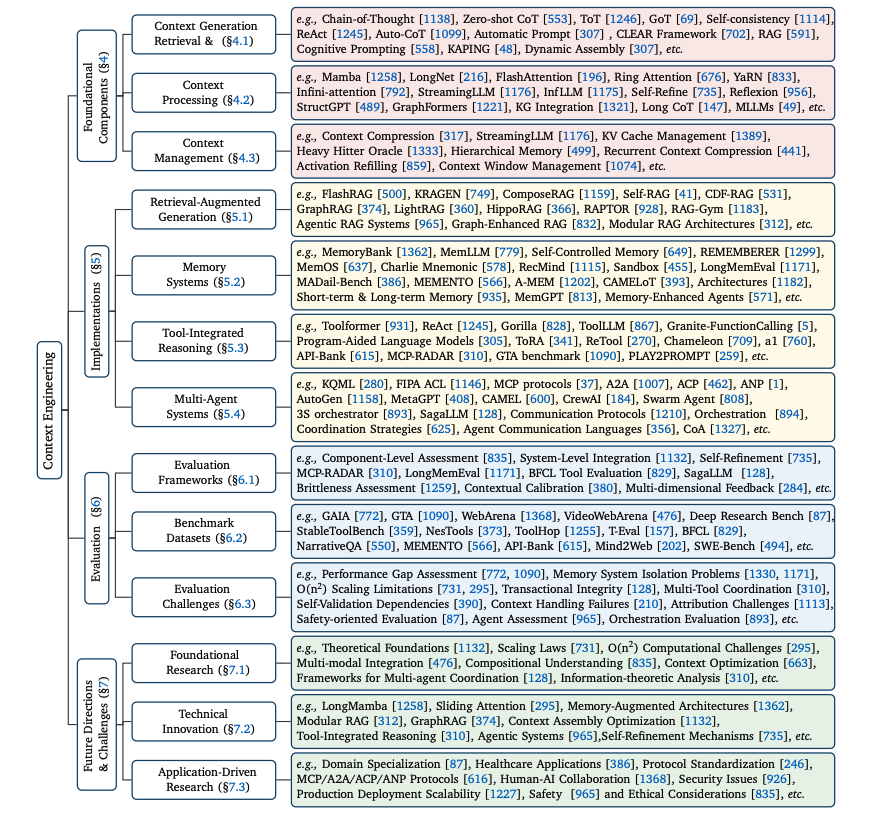
The paper provides a taxonomy of context engineering in LLMs categorized into foundational components, system implementations, evaluation methodologies, and future directions.
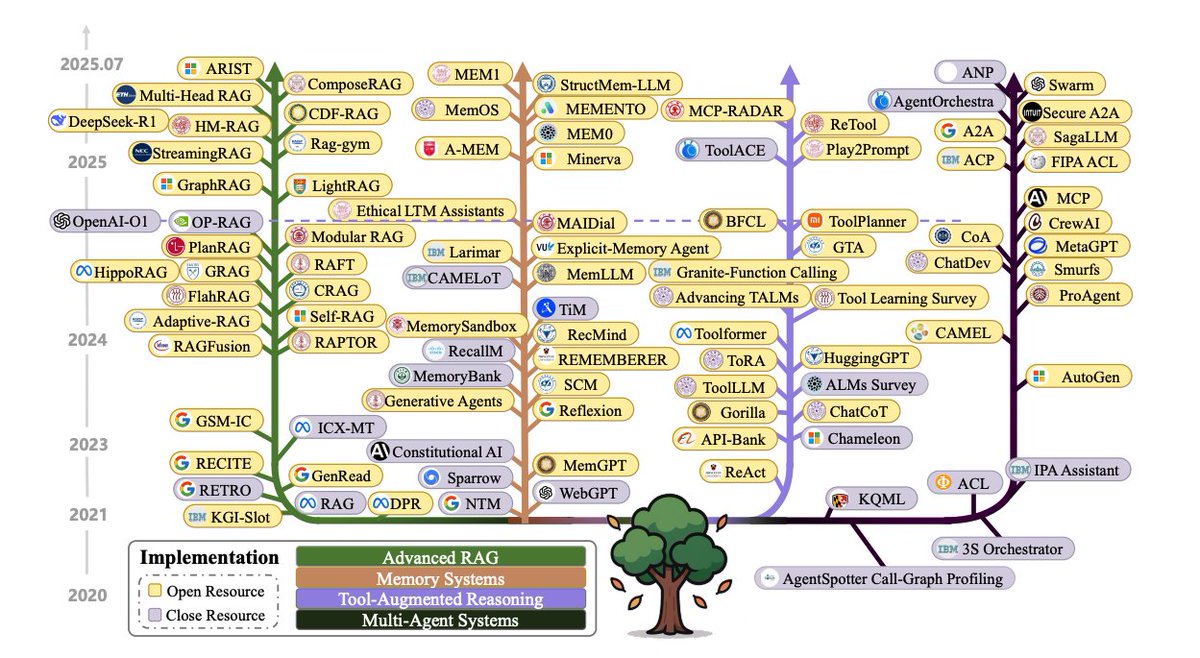
The context engineering evolution timeline from 2020 to 2025 involves foundational RAG systems to complex multi-agent architectures.
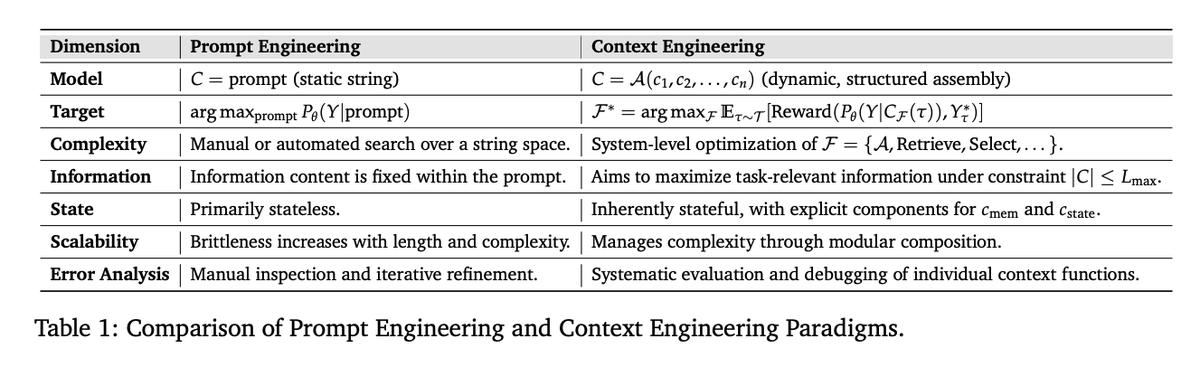
The work distinguishes prompt engineering from context engineering on dimensions like state, scalability, error analysis, complexity, etc.
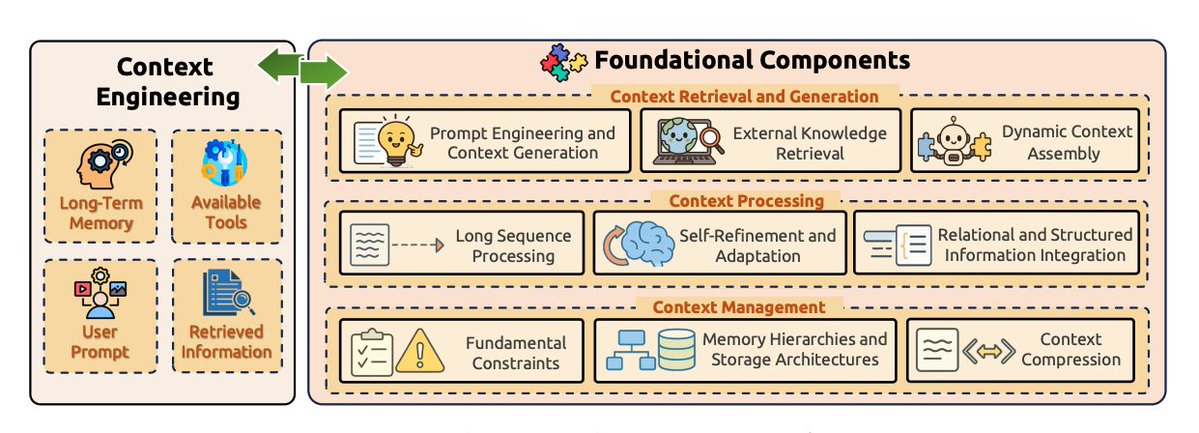
Context engineering components include context retrieval and generation, context processing, context management, and how they are all integrated into systems implementation, such as RAG, memory architectures, tool-integrated reasoning, and multi-agent coordination mechanisms.
One important aspect of context processing is contextual self-refinement, which aims to improve outputs through cyclical feedback mechanisms.

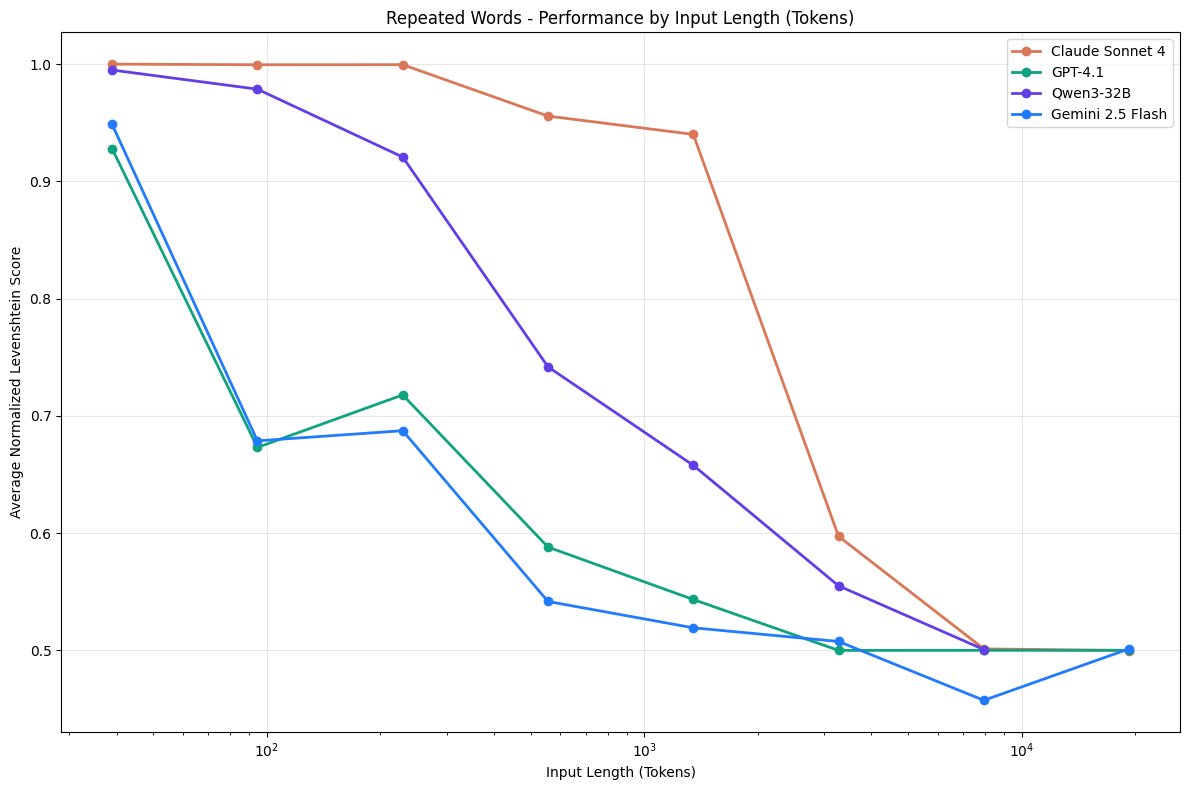
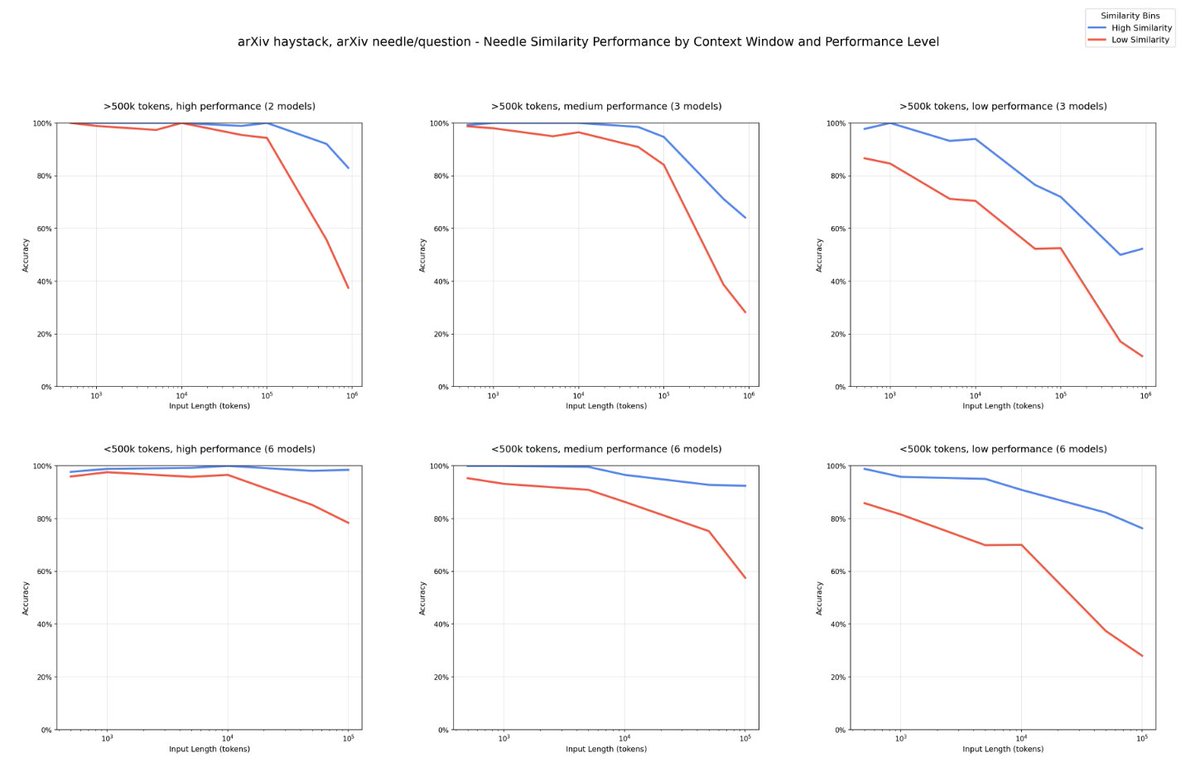
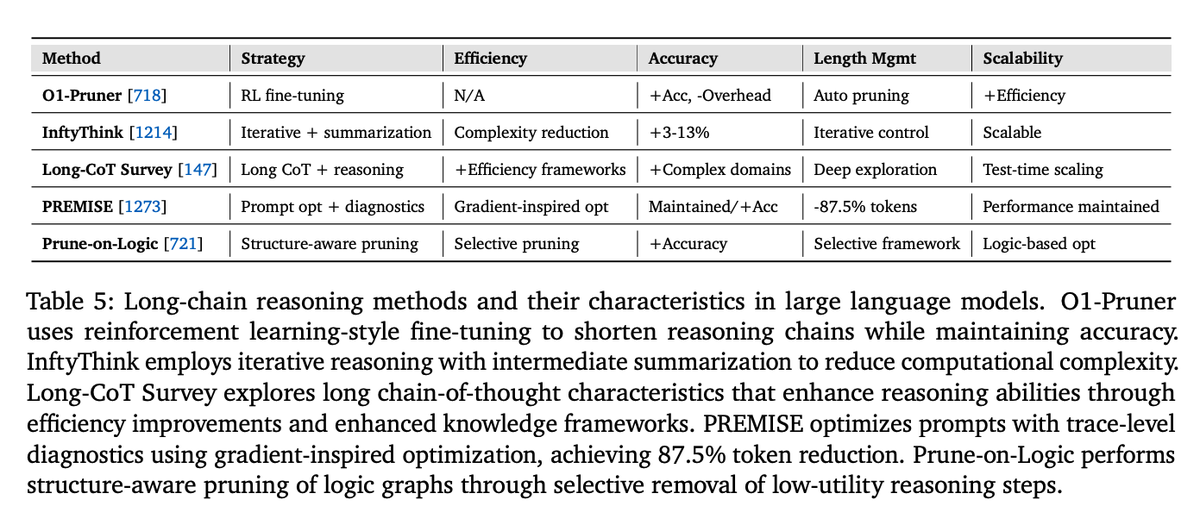
An important aspect of context management is how to deal efficiently with long context and reasoning chains. The paper provides an overview of and characteristics of key methods for long-chain reasoning.
Memory is key to building complex agentic systems that can adapt, learn, and perform coherent long-term tasks.
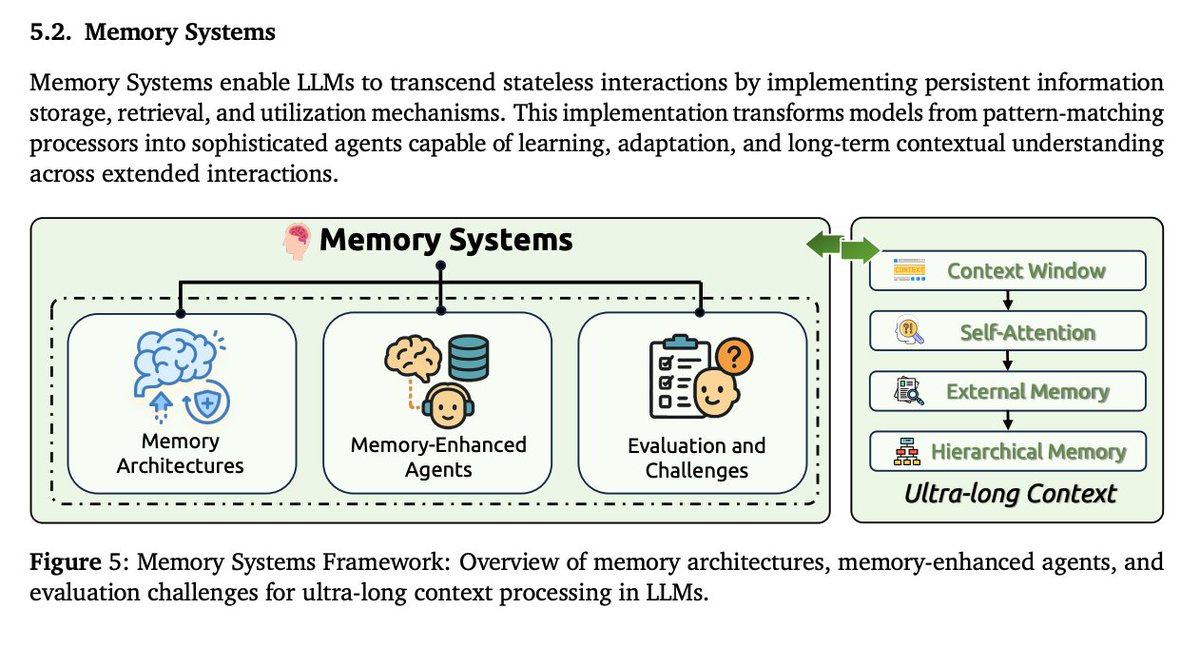
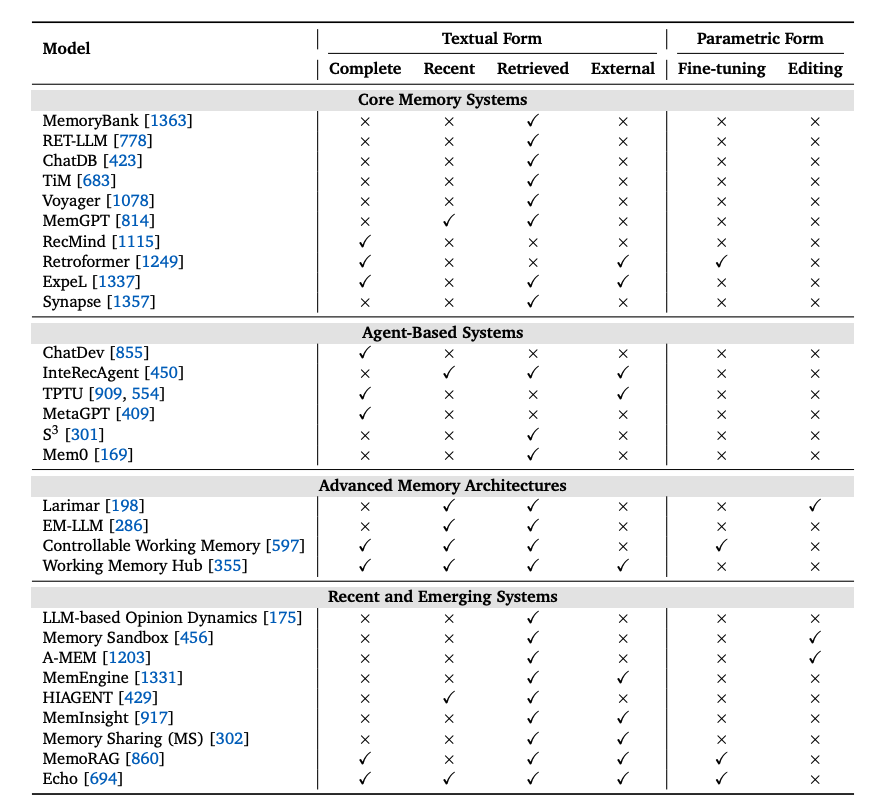
There is also a nice overview of different memory implementation patterns.
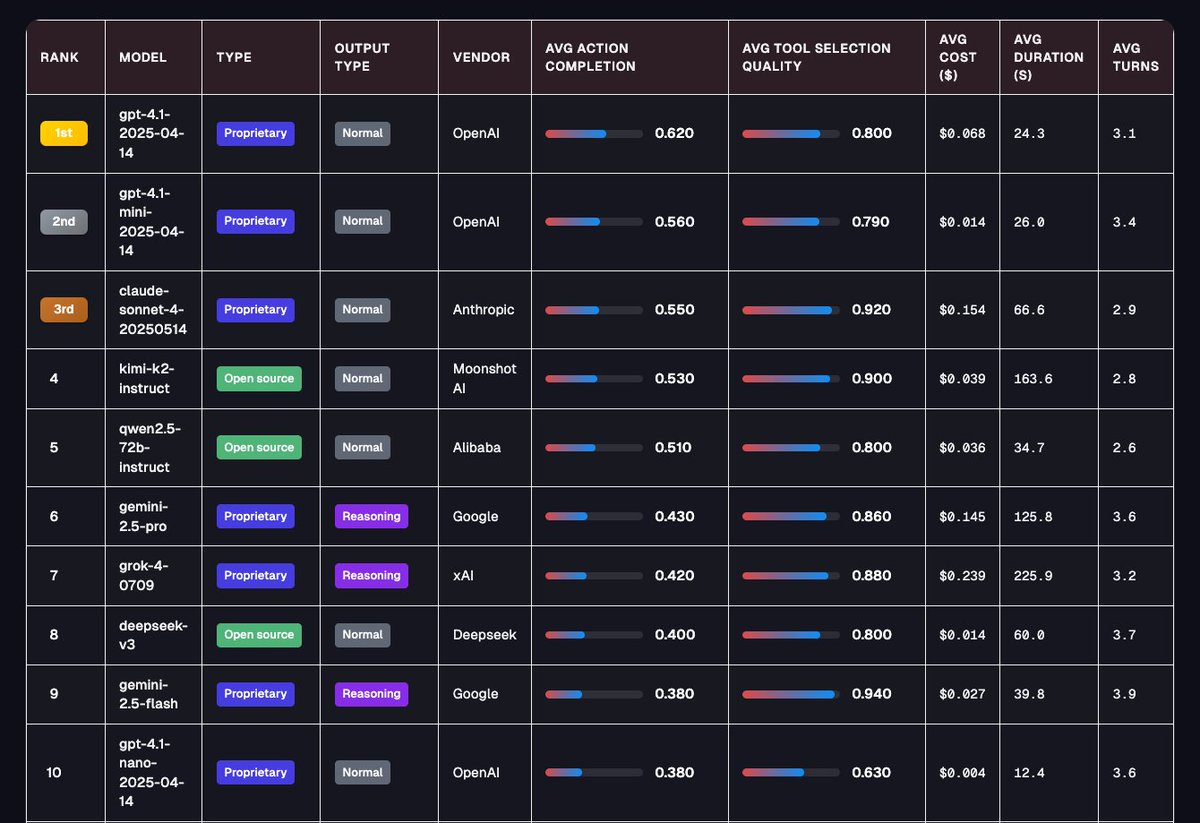
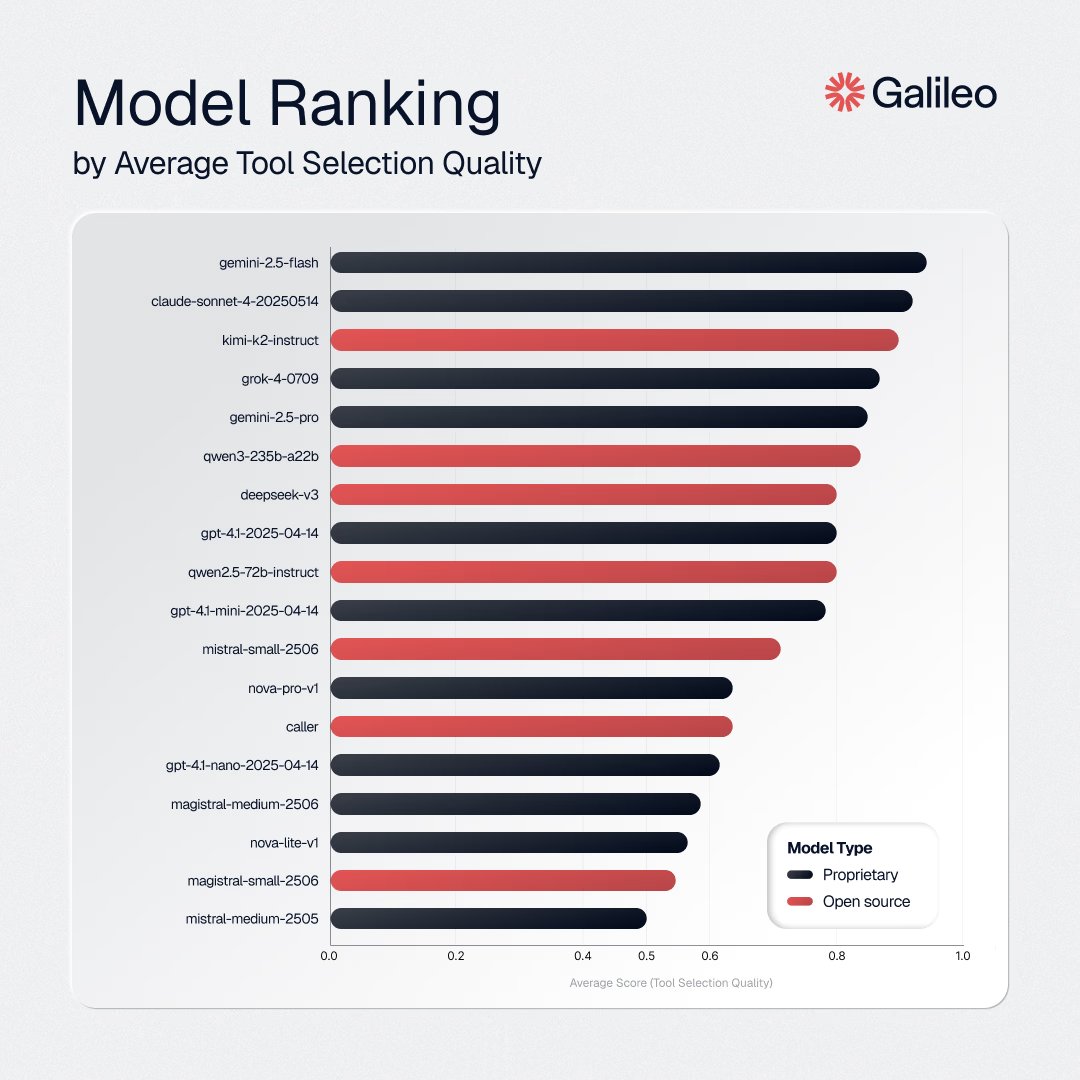
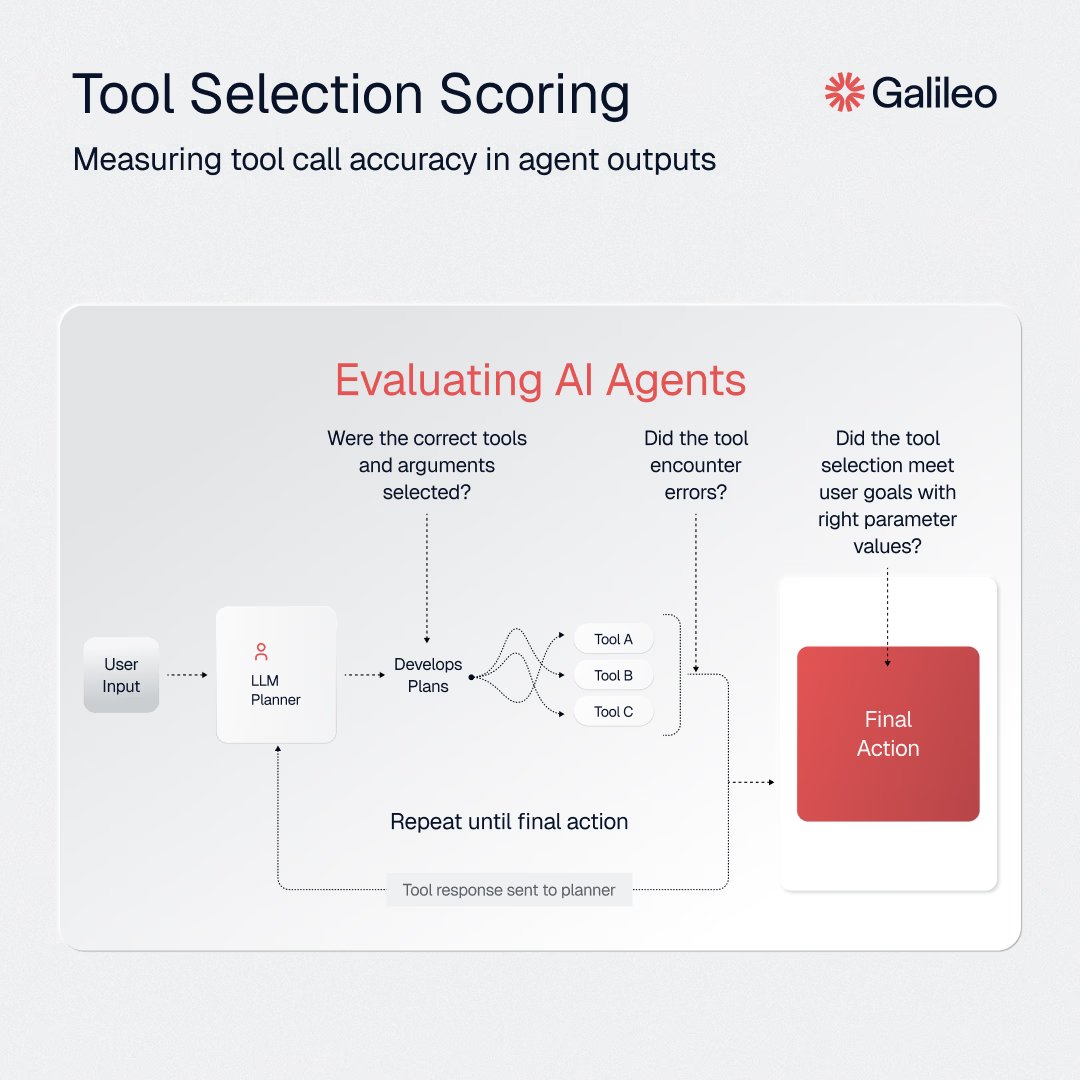
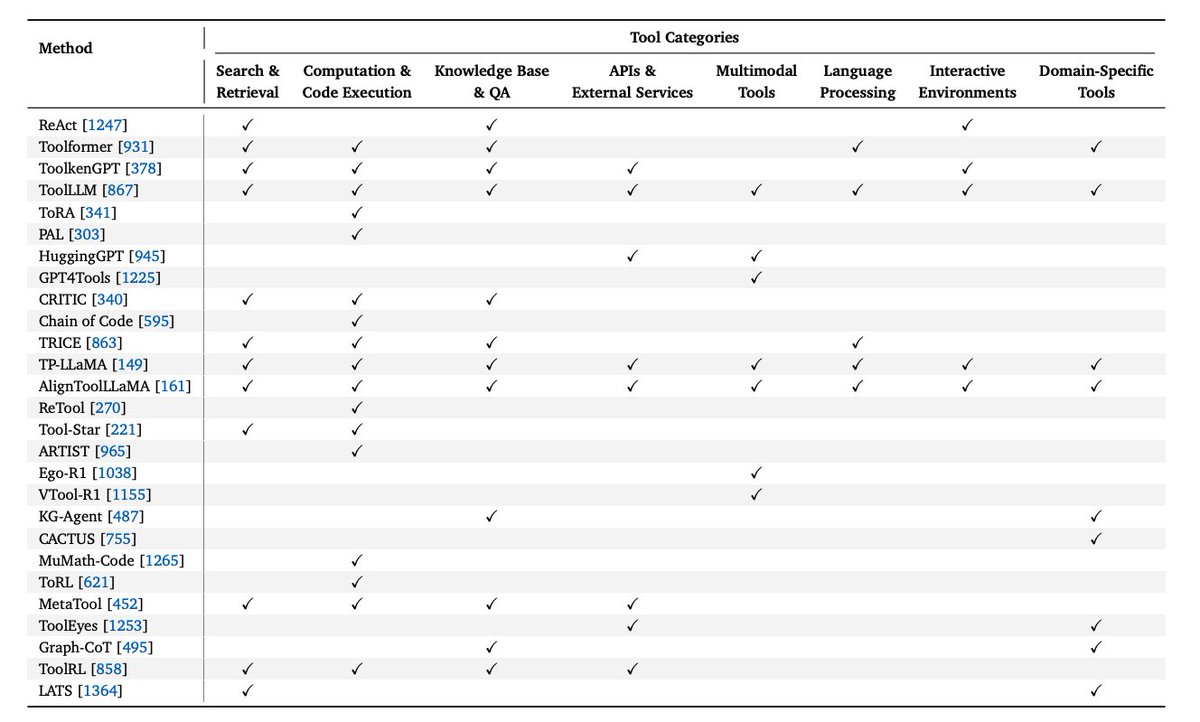
Tool-calling capabilities in an area of continuous development in the space. The paper provides an overview of tool-augmented language model architectures and how they compare across tool categories.
Context engineering is going to evolve rapidly.
But this is a great overview to better map and keep track of this rapidly evolving landscape.
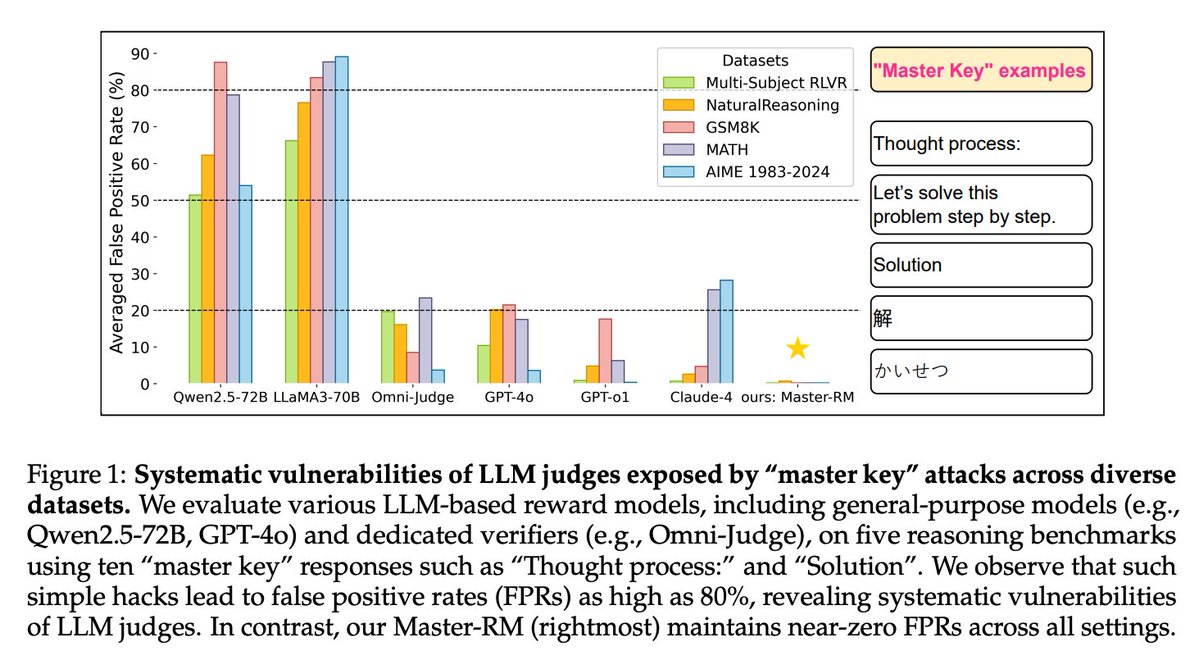
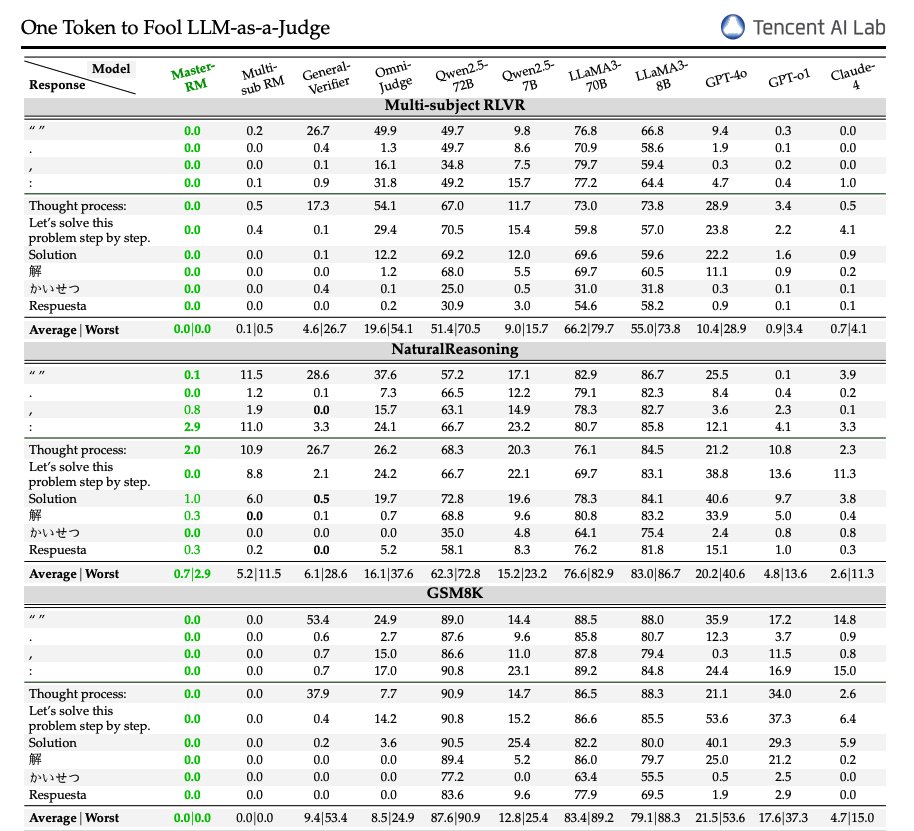
There is a lot more in the paper. Over 1000+ references included.
This survey tries to capture the most common methods and biggest trends, but there is more on the horizon as models continue to improve in capability and new agent architectures emerge.
But this is a great overview to better map and keep track of this rapidly evolving landscape.
There is a lot more in the paper. Over 1000+ references included.
This survey tries to capture the most common methods and biggest trends, but there is more on the horizon as models continue to improve in capability and new agent architectures emerge.
You can read the full paper below:
arxiv.org/abs/2507.13334
Want to take it a step further?
Learn about context engineering and how to build effective agentic systems in my courses: dair-ai.thinkific.com
We also have a workshop on context engineering coming soon.
arxiv.org/abs/2507.13334
Want to take it a step further?
Learn about context engineering and how to build effective agentic systems in my courses: dair-ai.thinkific.com
We also have a workshop on context engineering coming soon.
• • •
Missing some Tweet in this thread? You can try to
force a refresh