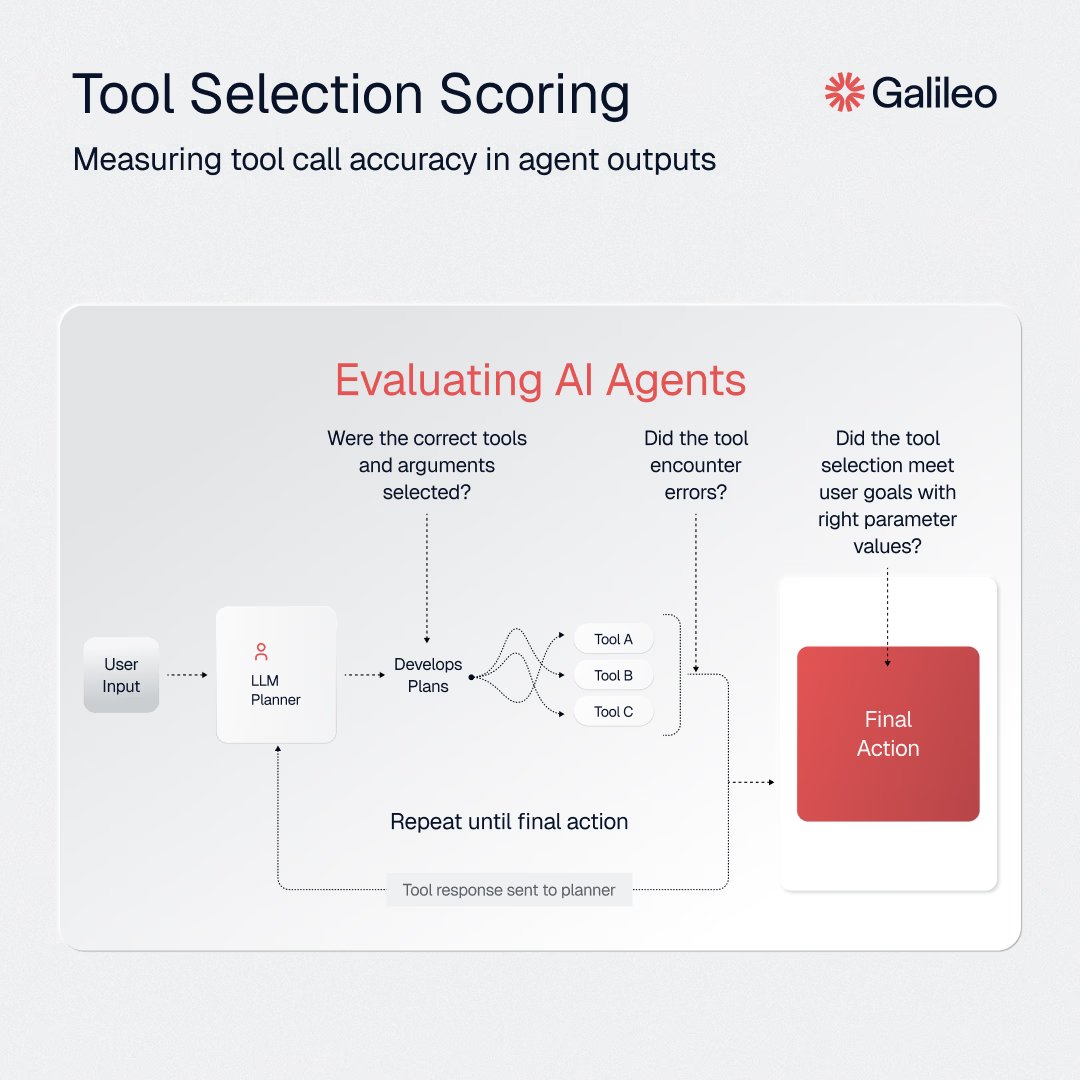
Claude Code is more than a coding agent.
It's more like a super smart orchestrator agent.
Watch this evaluator loop agent I just built using sub agents and / commands.
This is one of the fastest ways to build custom agentic workflows.
Claude Code is no joke!
It's more like a super smart orchestrator agent.
Watch this evaluator loop agent I just built using sub agents and / commands.
This is one of the fastest ways to build custom agentic workflows.
Claude Code is no joke!
I'm impressed to see how easy it is to control how the sub agents communicate with each other (i.e., chain, loop, hierarchical, critic, etc.).
Claude Code is good out of the box, but customization gives you a clear advantage.
Custom sub agents + / commands solve that.
Claude Code is good out of the box, but customization gives you a clear advantage.
Custom sub agents + / commands solve that.
It's worth spending the time optimizing instructions, tool use, agent definitions, and more.
Claude Code, on its own, somehow likes to use a lot of tokens and perform unnecessary tasks/tool calls.
You can max out credits or hit rate limits really fast if you are not careful.
Claude Code, on its own, somehow likes to use a lot of tokens and perform unnecessary tasks/tool calls.
You can max out credits or hit rate limits really fast if you are not careful.
/ commands I find is the better way to ensure Claude Code works the way it should.
Another observation is that if you are using an evaluator agent (LLM-as-a-Judge), you want to pay attention a bit more closely to how you handle logic. Biases are everywhere.
Another observation is that if you are using an evaluator agent (LLM-as-a-Judge), you want to pay attention a bit more closely to how you handle logic. Biases are everywhere.
Two agents I am experimenting with that will bring lots of benefits:
> custom context compressor to help with cost and latency
> mock-data generator to speed up experimentation with sub agents
Will be sharing more tips and use cases with my academy subs, in a week or so: dair-ai.thinkific.com/bundles/pro
> custom context compressor to help with cost and latency
> mock-data generator to speed up experimentation with sub agents
Will be sharing more tips and use cases with my academy subs, in a week or so: dair-ai.thinkific.com/bundles/pro

Wow! So we already have about 50 subs joining the session. Really excited to share more ideas and tips on Claude Code soon.
• • •
Missing some Tweet in this thread? You can try to
force a refresh