
How does prompt optimization compare to RL algos like GRPO?
GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't.
Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵
GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't.
Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵
We implemented GEPA as a new @DSPyOSS optimizer (release soon!). This means that it works for even sophisticated agents or compound systems you've already implemented.
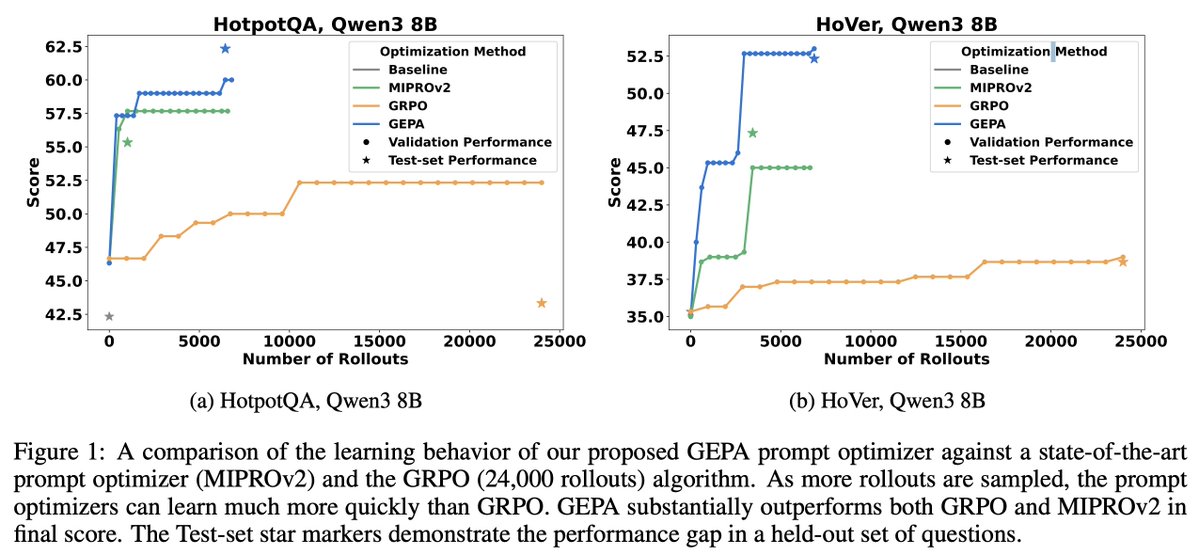
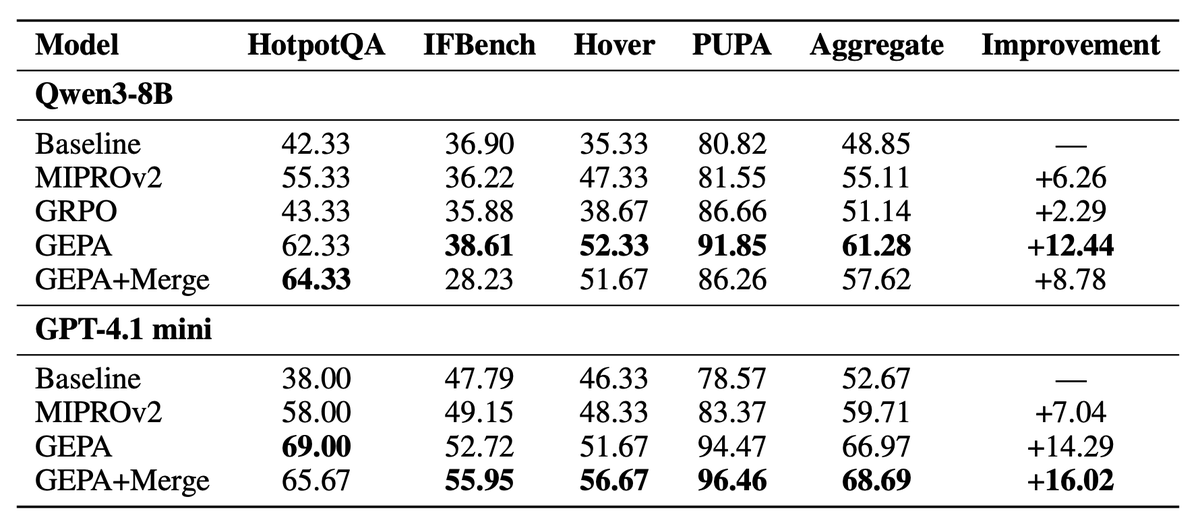
GEPA outperforms the MIPROv2 optimizer by as much as 11% across 4 tasks for Qwen3 and GPT-4.1-mini.
Of course: Weight updates remain necessary to teach the models completely new tasks and still excel at general-purpose (massively multi-task!) post-training!
However, we show that for specialization to downstream systems, reflective prompt optimization can go really far with tiny data sizes and rollout budgets!
(2/n)
GEPA outperforms the MIPROv2 optimizer by as much as 11% across 4 tasks for Qwen3 and GPT-4.1-mini.
Of course: Weight updates remain necessary to teach the models completely new tasks and still excel at general-purpose (massively multi-task!) post-training!
However, we show that for specialization to downstream systems, reflective prompt optimization can go really far with tiny data sizes and rollout budgets!
(2/n)
GEPA builds a Pareto tree of proposed prompts.
In each step, GEPA picks a prompt P that has performed best on some examples—even if not best overall!
GEPA performs a few rollouts with P, and uses NL reflection on the resulting trajectories to extract a few lessons, which GEPA validates on a few examples.
If they work, these lessons become part of a new node in the Pareto tree. This allows GEPA to propose increasingly nuanced prompts as the optimization progresses.
In each step, GEPA picks a prompt P that has performed best on some examples—even if not best overall!
GEPA performs a few rollouts with P, and uses NL reflection on the resulting trajectories to extract a few lessons, which GEPA validates on a few examples.
If they work, these lessons become part of a new node in the Pareto tree. This allows GEPA to propose increasingly nuanced prompts as the optimization progresses.

This design gives GEPA two additional, bonus features:
(1) GEPA’s prompts are not only more effective but also up to 9x shorter than those from leading few-shot optimizers!
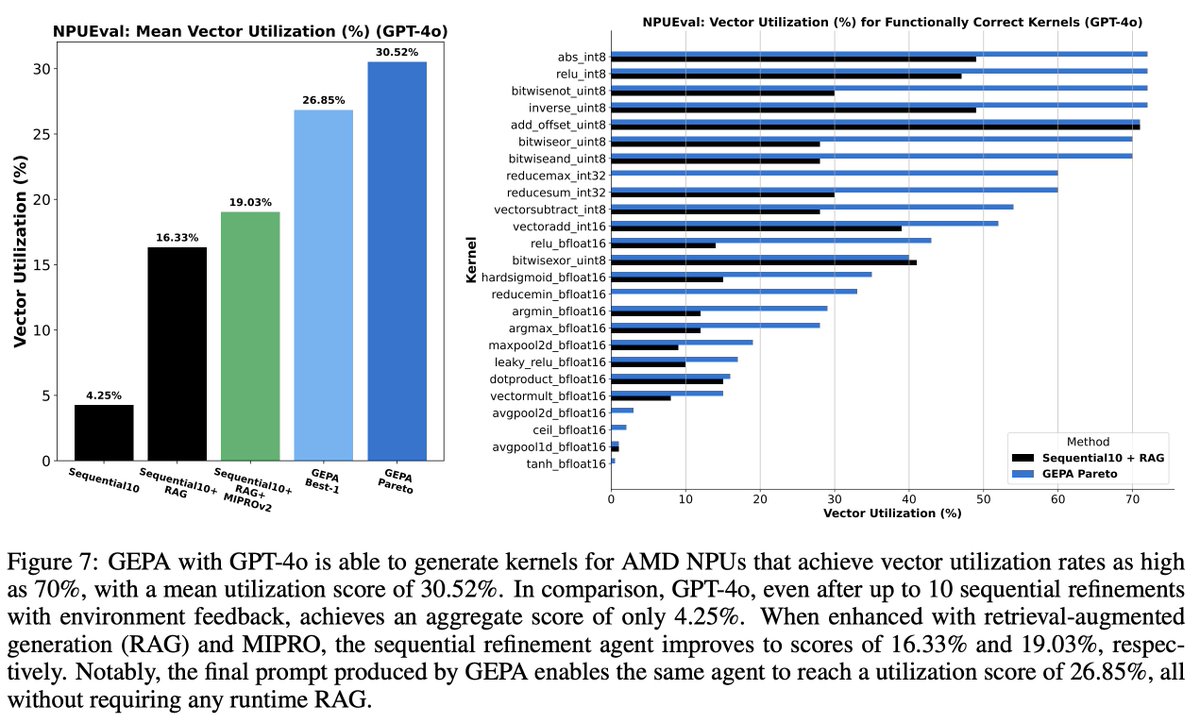
(2) GEPA shows promise as an inference-time search technique. It can generate performant kernels for AMD’s latest NPUs, outperforming RAG and iterative refinement techniques.
(1) GEPA’s prompts are not only more effective but also up to 9x shorter than those from leading few-shot optimizers!
(2) GEPA shows promise as an inference-time search technique. It can generate performant kernels for AMD’s latest NPUs, outperforming RAG and iterative refinement techniques.
Paper: arxiv.org/abs/2507.19457
GEPA will be open-sourced soon as a new DSPy optimizer. Stay tuned!
Incredibly grateful to the wonderful team @ShangyinT @dilarafsoylu @NoahZiems @rishiskhare @kristahopsalong @arnav_thebigman @krypticmouse @michaelryan207 @Meng_CS @ChrisGPotts @koushik77 @AlexGDimakis @istoica05, Dan Klein, @matei_zaharia @lateinteraction
GEPA will be open-sourced soon as a new DSPy optimizer. Stay tuned!
Incredibly grateful to the wonderful team @ShangyinT @dilarafsoylu @NoahZiems @rishiskhare @kristahopsalong @arnav_thebigman @krypticmouse @michaelryan207 @Meng_CS @ChrisGPotts @koushik77 @AlexGDimakis @istoica05, Dan Klein, @matei_zaharia @lateinteraction

• • •
Missing some Tweet in this thread? You can try to
force a refresh



