
AI Industry Made $57 Billion Mistake and No One’s Talking About It.
While GPT-5 headlines kept you distracted...
NVIDIA quietly released a bold claim:
→ Small Language Models (SLMs) are the future of AI agents
Cheaper, faster and just as capable for 80% of real-world tasks.
Easily one of the biggest shifts in AI this year and most people missed it.
99% people haven’t read this but they should: 🧵
While GPT-5 headlines kept you distracted...
NVIDIA quietly released a bold claim:
→ Small Language Models (SLMs) are the future of AI agents
Cheaper, faster and just as capable for 80% of real-world tasks.
Easily one of the biggest shifts in AI this year and most people missed it.
99% people haven’t read this but they should: 🧵

1/The paper is titled:
“Small Language Models are the Future of Agentic AI”
Published by NVIDIA Research.
It challenges the core assumption behind every LLM deployment today:
"That you need GPT-4–level models to run useful agents."
As per the research.. truth is - "You don't.."
now, let's dive deeper:
“Small Language Models are the Future of Agentic AI”
Published by NVIDIA Research.
It challenges the core assumption behind every LLM deployment today:
"That you need GPT-4–level models to run useful agents."
As per the research.. truth is - "You don't.."
now, let's dive deeper:

2/ LLMs like GPT-4 and Claude 3.5 are powerful but most AI agents don’t need that power.
They handle narrow, repetitive tasks.
And SLMs can do those better, cheaper, and faster.
They handle narrow, repetitive tasks.
And SLMs can do those better, cheaper, and faster.
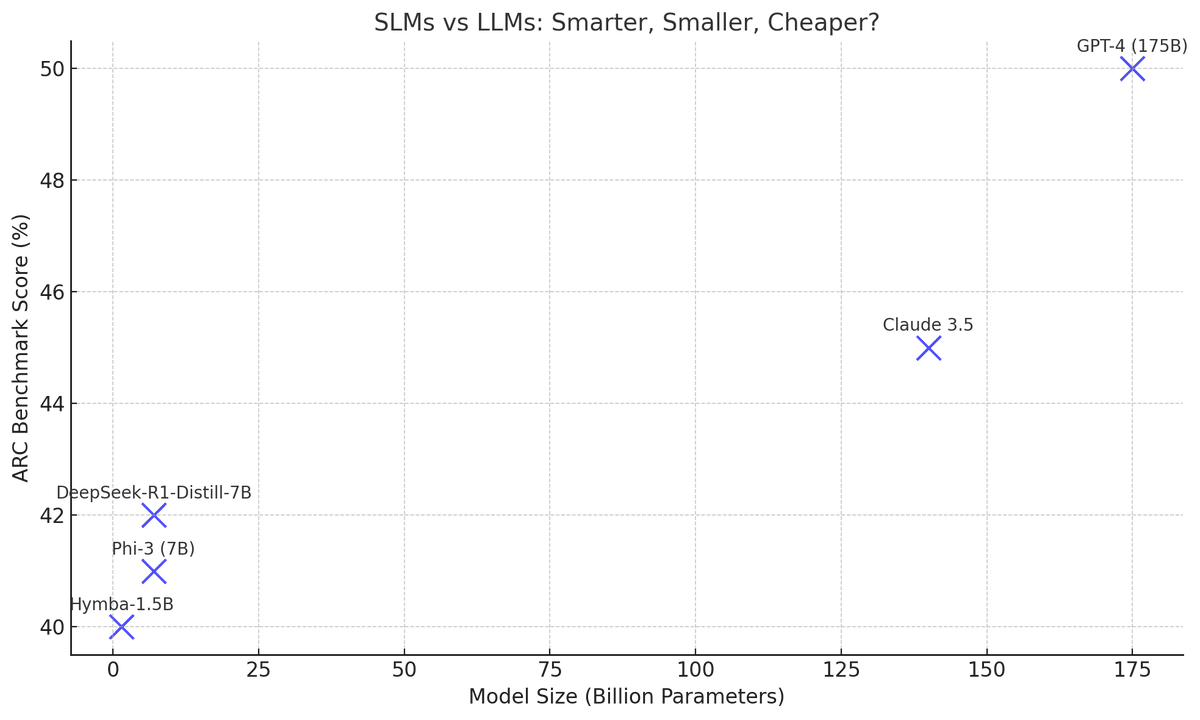
3/ What’s an SLM?
A Small Language Model is tiny enough to run on your laptop or edge device.
We're talking under 10B parameters...fast, fine-tunable, and private.
Think:
→ Lower latency
→ Offline control
→ Fraction of the cost
A Small Language Model is tiny enough to run on your laptop or edge device.
We're talking under 10B parameters...fast, fine-tunable, and private.
Think:
→ Lower latency
→ Offline control
→ Fraction of the cost
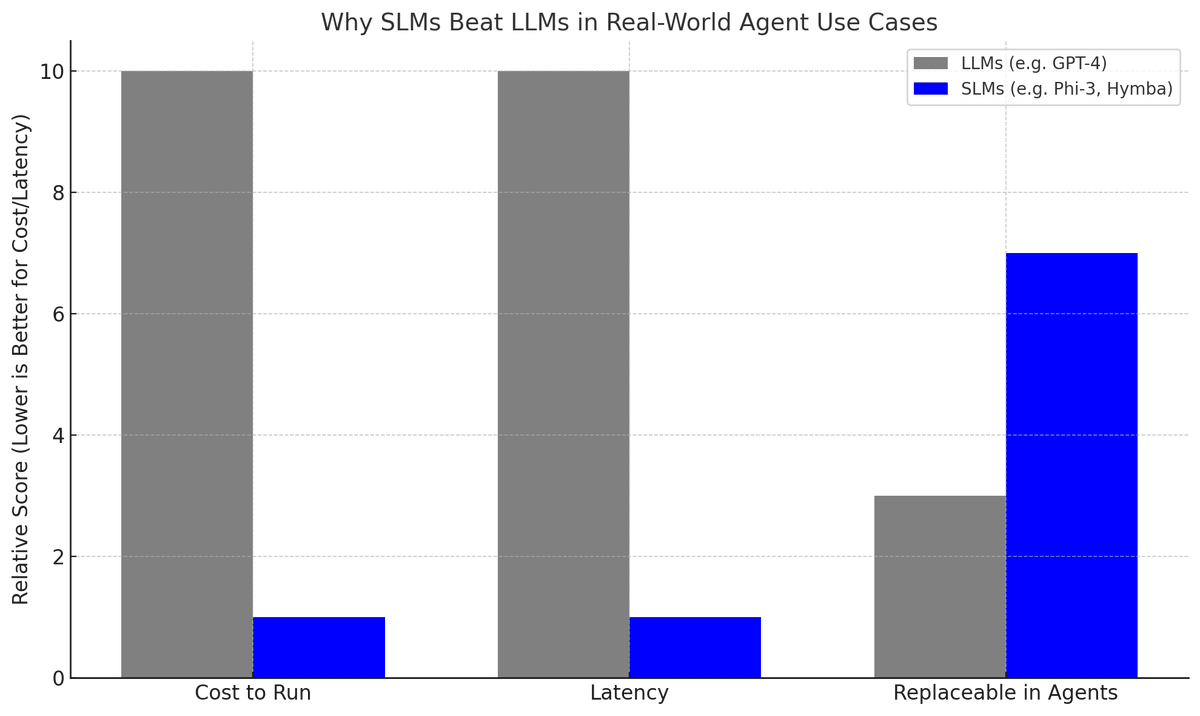
4/ What did NVIDIA actually say?
In their new paper, NVIDIA Research argues:
“SLMs are the future of agentic AI.”
→ Most AI agents just do narrow, repetitive tasks
→ They don’t need 70B+ parameters
→ SLMs (small language models) are cheaper, faster, and just as accurate in real workflows
Let that sink in!
In their new paper, NVIDIA Research argues:
“SLMs are the future of agentic AI.”
→ Most AI agents just do narrow, repetitive tasks
→ They don’t need 70B+ parameters
→ SLMs (small language models) are cheaper, faster, and just as accurate in real workflows
Let that sink in!
5/ The math here is wild:
Newer SLMs like Phi-3 and Hymba match 30–70B models in tool use, reasoning, and instruction following:
→ Run 10× faster, use 10–30× less compute in real workflows
Tool use, commonsense, and instruction-following? On point.
Newer SLMs like Phi-3 and Hymba match 30–70B models in tool use, reasoning, and instruction following:
→ Run 10× faster, use 10–30× less compute in real workflows
Tool use, commonsense, and instruction-following? On point.

6/ Serving GPT-4 is expensive.
Running a tuned SLM is 10–30x cheaper.
And you can deploy them:
→ On-device
→ With custom formats
→ Using tools like ChatRTX, LoRA, QLoRA
Enterprise-ready, budget-friendly.
Running a tuned SLM is 10–30x cheaper.
And you can deploy them:
→ On-device
→ With custom formats
→ Using tools like ChatRTX, LoRA, QLoRA
Enterprise-ready, budget-friendly.
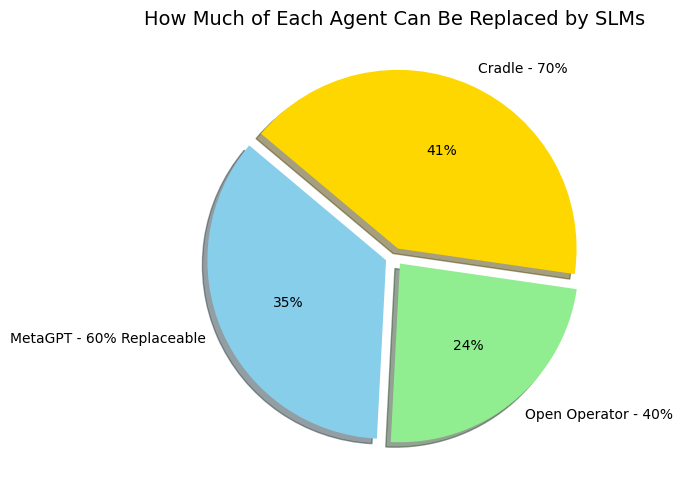
7/ NVIDIA tested this across 3 real-world AI agents:
- MetaGPT → 60% of tasks replaceable by SLMs
- Open Operator → 40%
- Cradle (GUI automation) → 70%
And those are today’s SLMs.
This paper could reshape how we build AI agents in the next decade.
- MetaGPT → 60% of tasks replaceable by SLMs
- Open Operator → 40%
- Cradle (GUI automation) → 70%
And those are today’s SLMs.
This paper could reshape how we build AI agents in the next decade.
8/ Why This Matters for AGI:
The path to human-like agents isn’t bigger models.
It’s modular ones.
SLMs can be specialists, like tools in a toolbox.
And that’s exactly how human reasoning works.
The path to human-like agents isn’t bigger models.
It’s modular ones.
SLMs can be specialists, like tools in a toolbox.
And that’s exactly how human reasoning works.

9/ The Moral Edge
SLMs aren’t just efficient, they’re ethical.
They:
→ Reduce energy usage
→ Enable edge privacy
→ Empower smaller teams & communities
LLMs centralize power. SLMs distribute it.
SLMs aren’t just efficient, they’re ethical.
They:
→ Reduce energy usage
→ Enable edge privacy
→ Empower smaller teams & communities
LLMs centralize power. SLMs distribute it.
10/ So why is nobody using them?
NVIDIA lists 3 reasons:
→ $57B was invested into centralized LLM infra in 2024. But SLMs might now challenge that model, on performance, cost, and flexibility.
→ Benchmarking is still biased toward “bigger is better”
→ SLMs get zero hype compared to GPT-4, Claude, etc.
This paper flips that.
People just don’t know what SLMs can do (yet)
But that’s changing fast.
NVIDIA lists 3 reasons:
→ $57B was invested into centralized LLM infra in 2024. But SLMs might now challenge that model, on performance, cost, and flexibility.
→ Benchmarking is still biased toward “bigger is better”
→ SLMs get zero hype compared to GPT-4, Claude, etc.
This paper flips that.
People just don’t know what SLMs can do (yet)
But that’s changing fast.
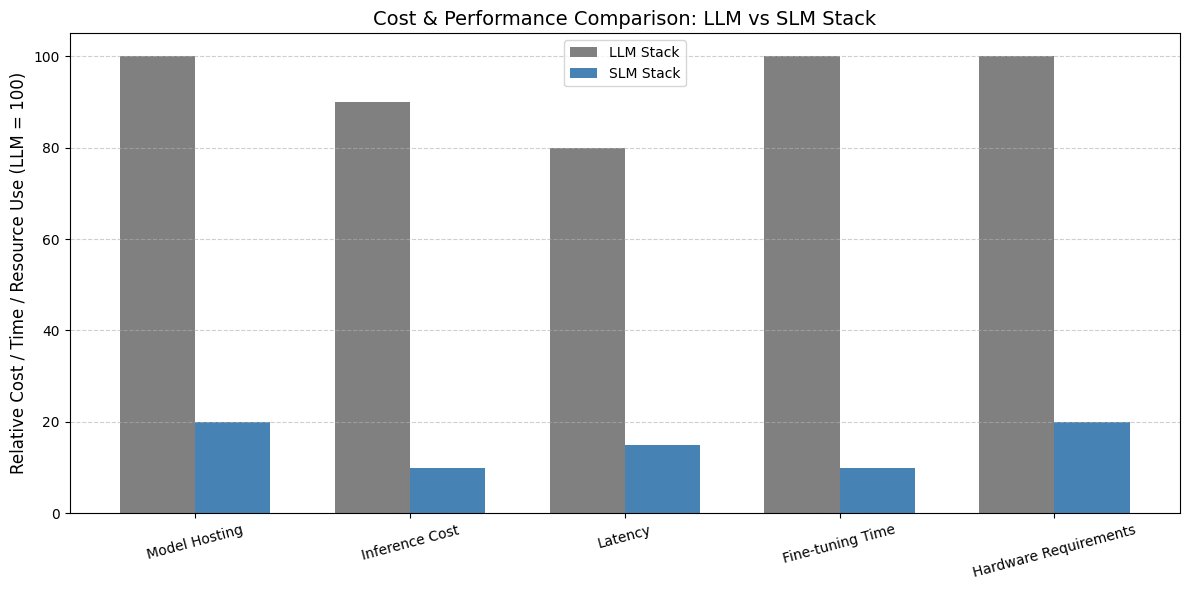
11/ NVIDIA even outlined a step-by-step migration framework to convert LLM agents to SLM-first systems:
How to migrate LLM-based agents into SLM-first systems
How to fine-tune SLMs for specific tasks
How to cluster tasks and build SLM “skills”
How to scale all locally, if needed
They’re not guessing.
They built the roadmap.
How to migrate LLM-based agents into SLM-first systems
How to fine-tune SLMs for specific tasks
How to cluster tasks and build SLM “skills”
How to scale all locally, if needed
They’re not guessing.
They built the roadmap.
12/ So what does this mean?
→ Most AI agents today are overbuilt
→ You might be paying 20x more for marginal gains
→ You’re also locked into centralized APIs
SLMs break that model.
And NVIDIA just made the case for switching at scale.
→ Most AI agents today are overbuilt
→ You might be paying 20x more for marginal gains
→ You’re also locked into centralized APIs
SLMs break that model.
And NVIDIA just made the case for switching at scale.
13/ This isn’t anti-GPT.
It’s post-GPT.
LLMs gave us the spark.
SLMs will give us the system.
The next 100 million agents won’t run on GPT-4.
They’ll run on tiny, specialized, ultra-cheap models.
And that’s not a theory. It’s already happening.
It’s post-GPT.
LLMs gave us the spark.
SLMs will give us the system.
The next 100 million agents won’t run on GPT-4.
They’ll run on tiny, specialized, ultra-cheap models.
And that’s not a theory. It’s already happening.
14/ TL;DR
The AGI race won’t be won with trillion-token giants.
The path to scalable agentic systems isn’t just bigger models. It’s modular, fine-tuned, and specialized powered by SLMs
📄 Read the paper: arxiv.org/abs/2506.02153
The AGI race won’t be won with trillion-token giants.
The path to scalable agentic systems isn’t just bigger models. It’s modular, fine-tuned, and specialized powered by SLMs
📄 Read the paper: arxiv.org/abs/2506.02153
Use AI to think faster, work smarter, and stay ahead
Join thousands of readers getting practical AI tips every week: 👉 shrutimishra.co
Join thousands of readers getting practical AI tips every week: 👉 shrutimishra.co
• • •
Missing some Tweet in this thread? You can try to
force a refresh










