Hierarchical Reasoning Model
This is one of the most interesting ideas on reasoning I've read in the past couple of months.
It uses a recurrent architecture for impressive hierarchical reasoning.
Here are my notes:
This is one of the most interesting ideas on reasoning I've read in the past couple of months.
It uses a recurrent architecture for impressive hierarchical reasoning.
Here are my notes:
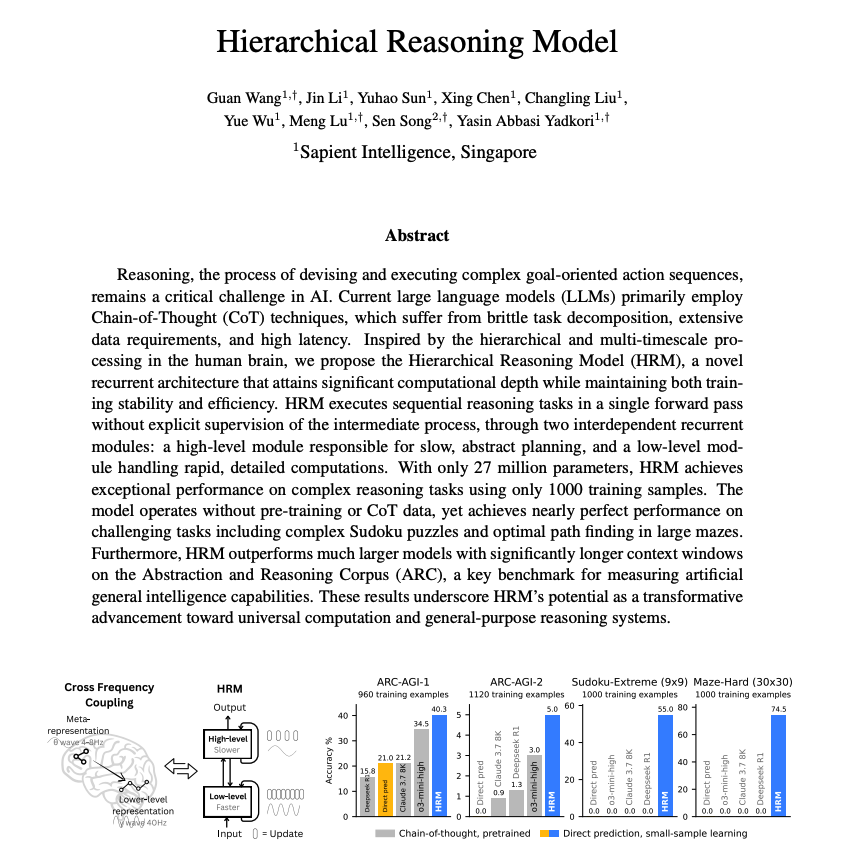
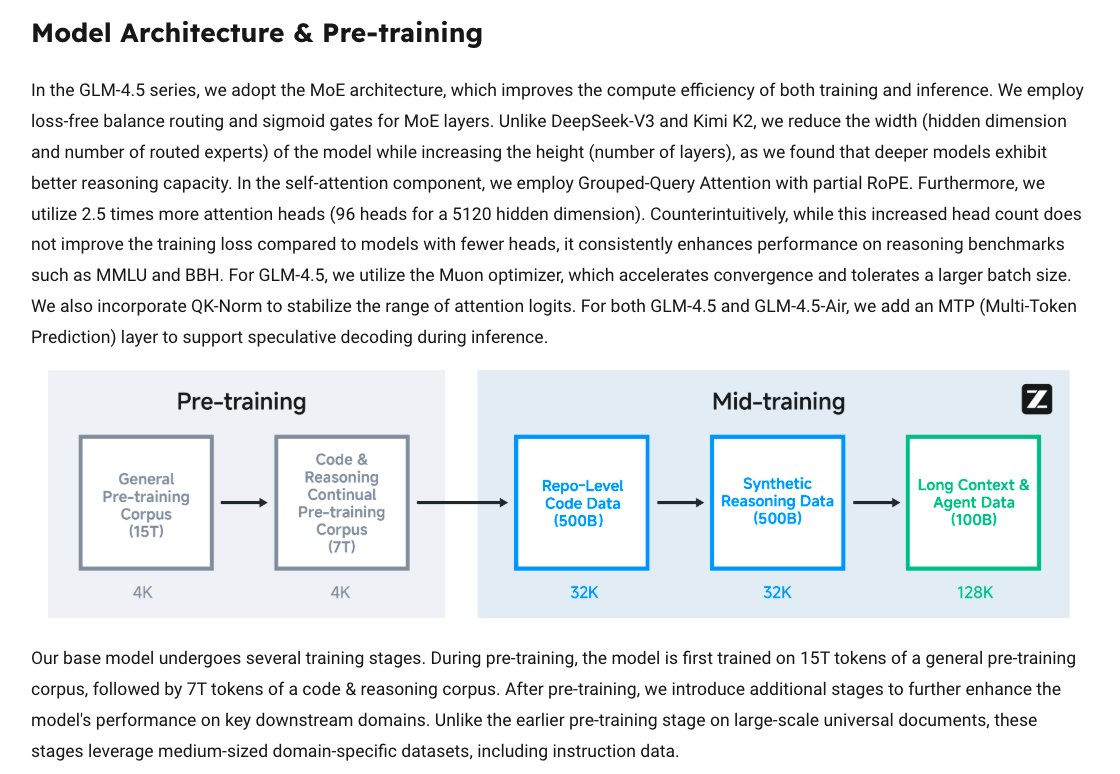
The paper proposes a novel, brain-inspired architecture that replaces CoT prompting with a recurrent model designed for deep, latent computation.
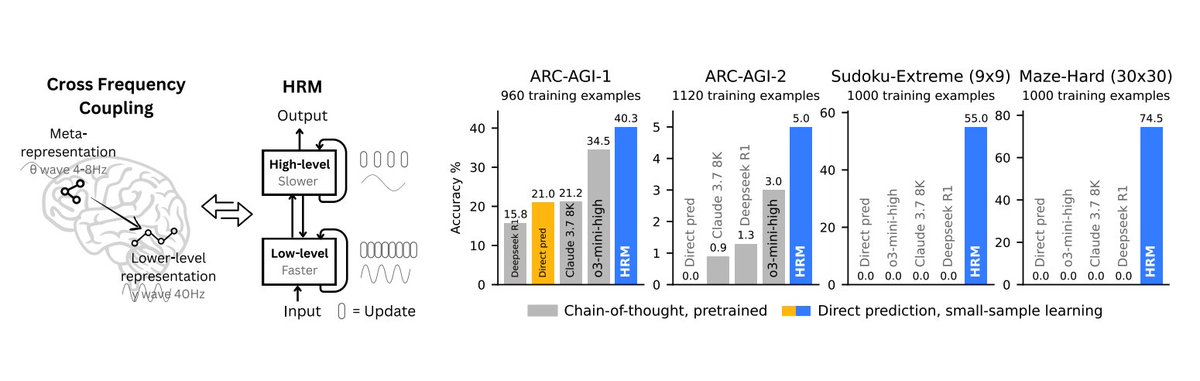
It moves away from token-level reasoning by using two coupled modules: a slow, high-level planner and a fast, low-level executor.
The two recurrent networks operate at different timescales to collaboratively solve tasks
Leads to greater reasoning depth and efficiency with only 27M parameters and no pretraining!
The two recurrent networks operate at different timescales to collaboratively solve tasks
Leads to greater reasoning depth and efficiency with only 27M parameters and no pretraining!
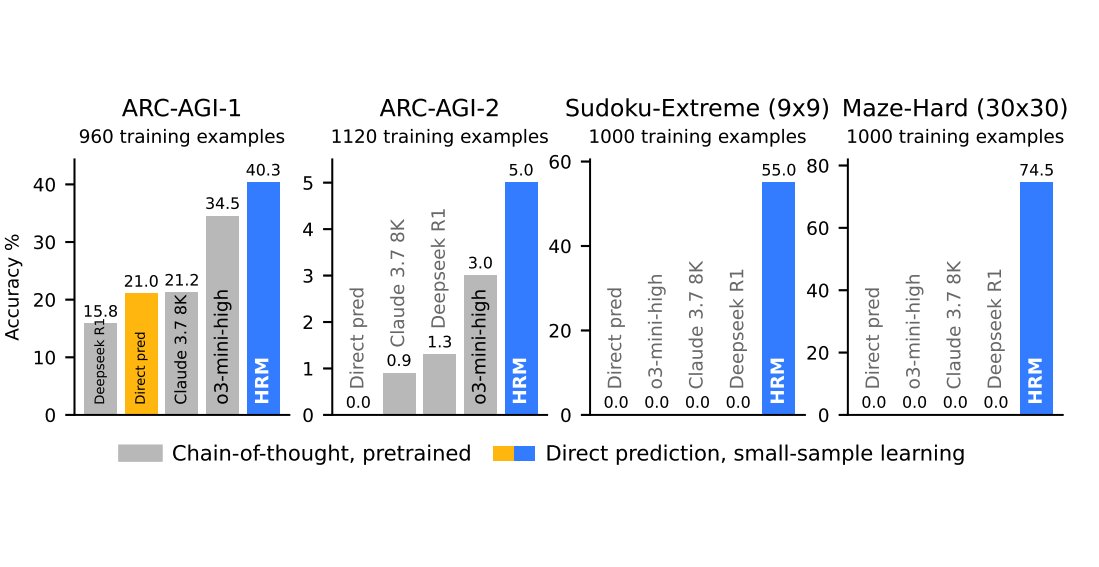
Despite its small size and minimal training data (~1k examples), HRM solves complex tasks like ARC, Sudoku-Extreme, and 30×30 maze navigation, where CoT-based LLMs fail.
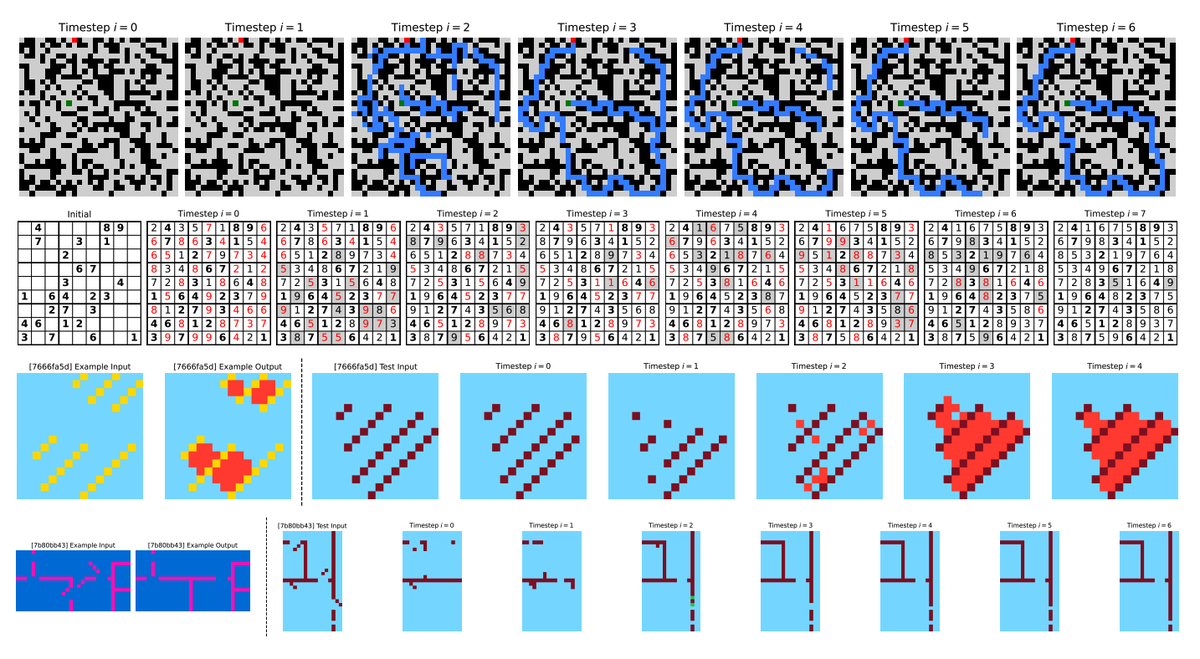
HRM introduces hierarchical convergence, where the low-level module rapidly converges within each cycle, and the high-level module updates only after this local equilibrium is reached.
This enables nested computation and avoids premature convergence typical of standard RNNs.
This enables nested computation and avoids premature convergence typical of standard RNNs.
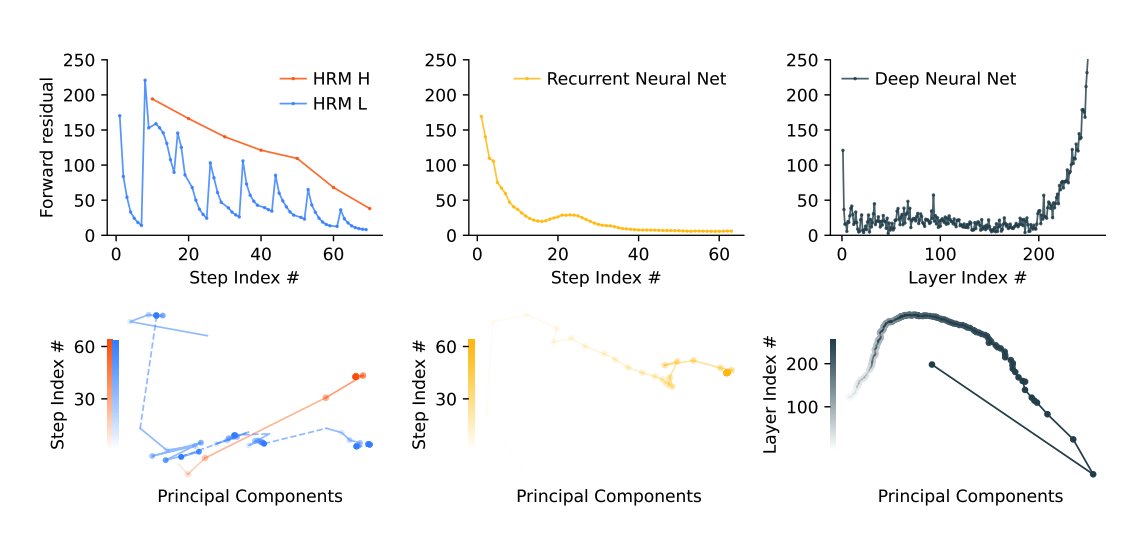
A 1-step gradient approximation sidesteps memory-intensive backpropagation-through-time (BPTT).
This enables efficient training using only local gradient updates, grounded in deep equilibrium models.
This enables efficient training using only local gradient updates, grounded in deep equilibrium models.

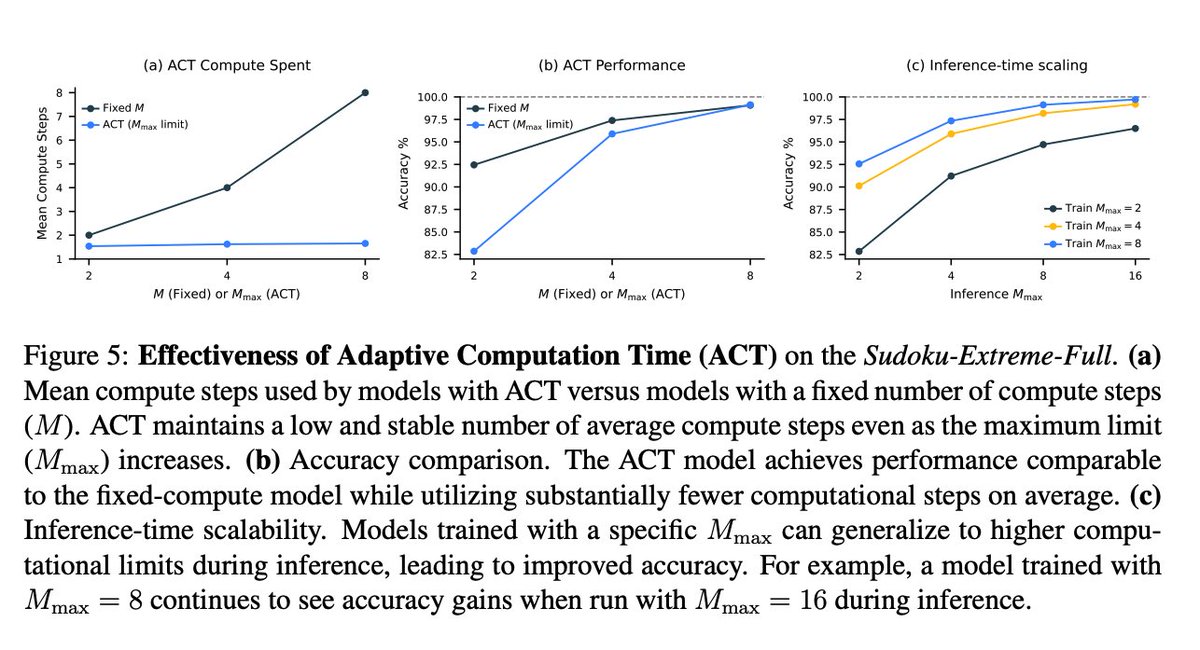
HRM implements adaptive computation time using a Q-learning-based halting mechanism, dynamically allocating compute based on task complexity.
This allows the model to “think fast or slow” and scale at inference time without retraining.
This allows the model to “think fast or slow” and scale at inference time without retraining.
Experiments on ARC-AGI, Sudoku-Extreme, and Maze-Hard show that HRM significantly outperforms larger models using CoT or direct prediction, even solving problems that other models fail entirely (e.g., 74.5% on Maze-Hard vs. 0% for others).
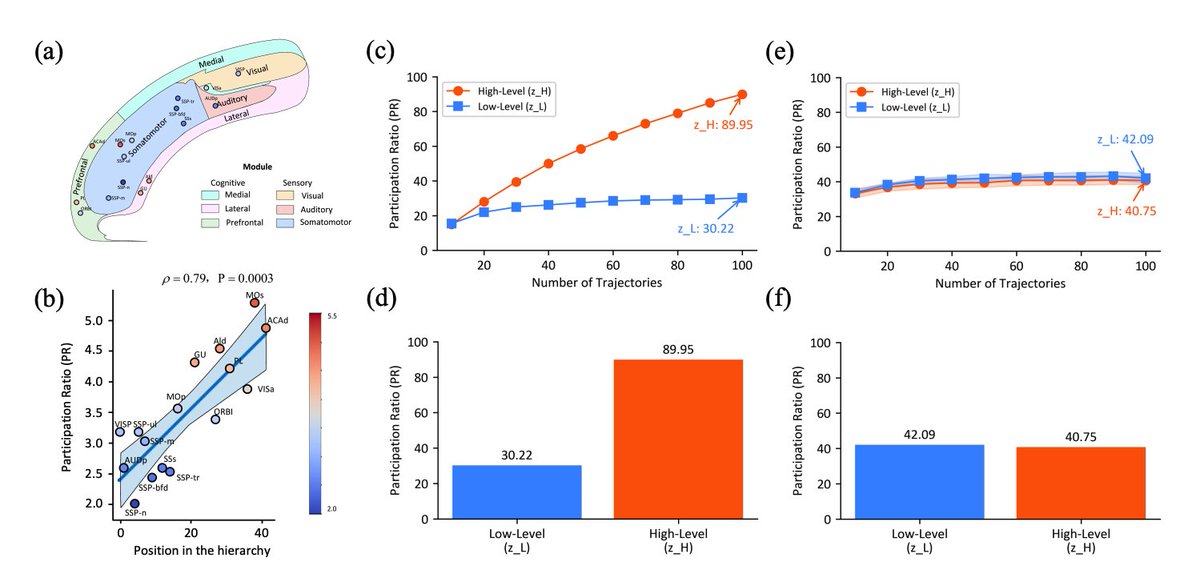
Analysis reveals that HRM learns a dimensionality hierarchy similar to the cortex: the high-level module operates in a higher-dimensional space than the low-level one (PR: 89.95 vs. 30.22).
The authors suggest that this is an emergent trait not present in untrained models.
Paper: arxiv.org/abs/2506.21734
The authors suggest that this is an emergent trait not present in untrained models.
Paper: arxiv.org/abs/2506.21734
• • •
Missing some Tweet in this thread? You can try to
force a refresh