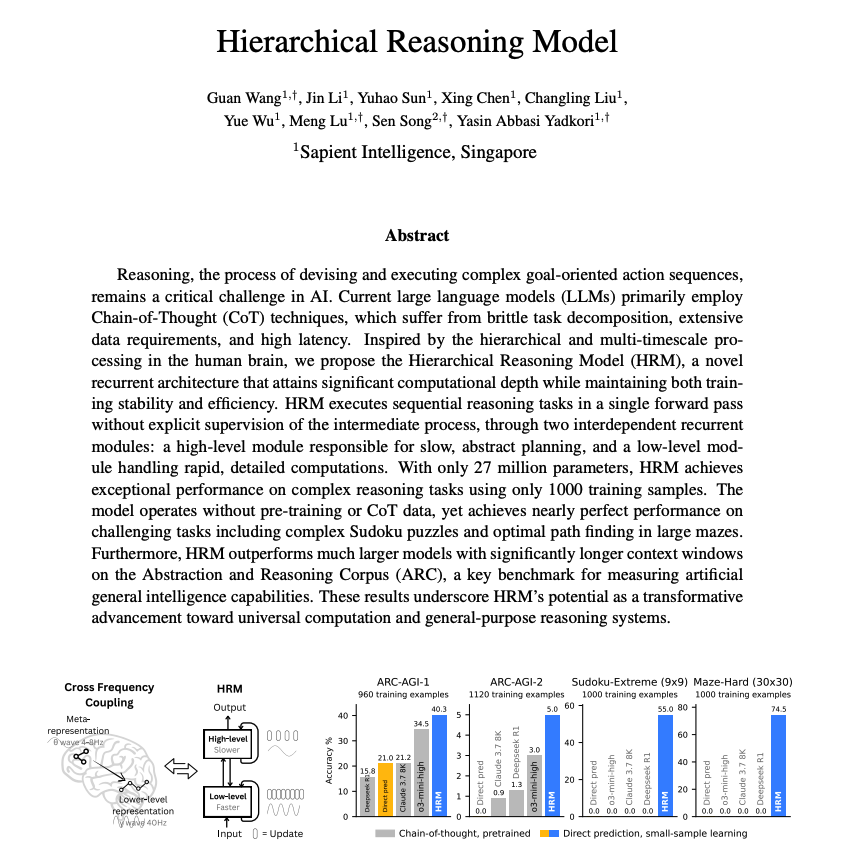
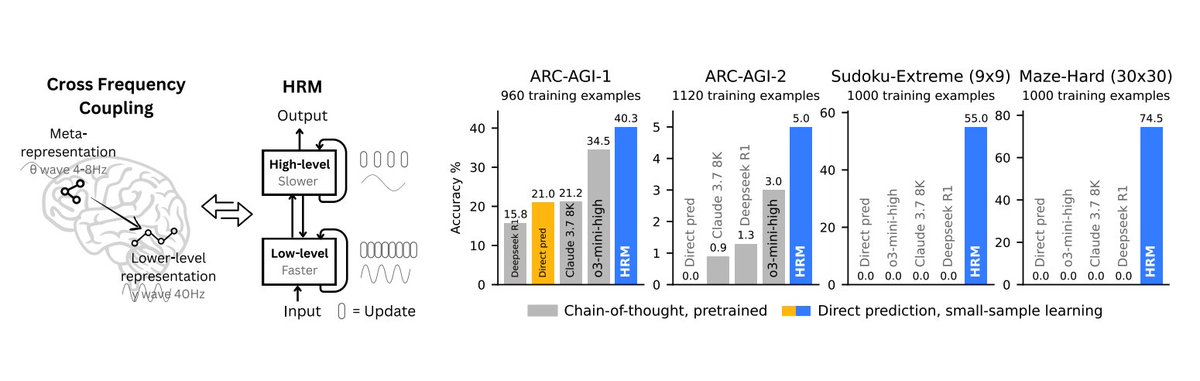
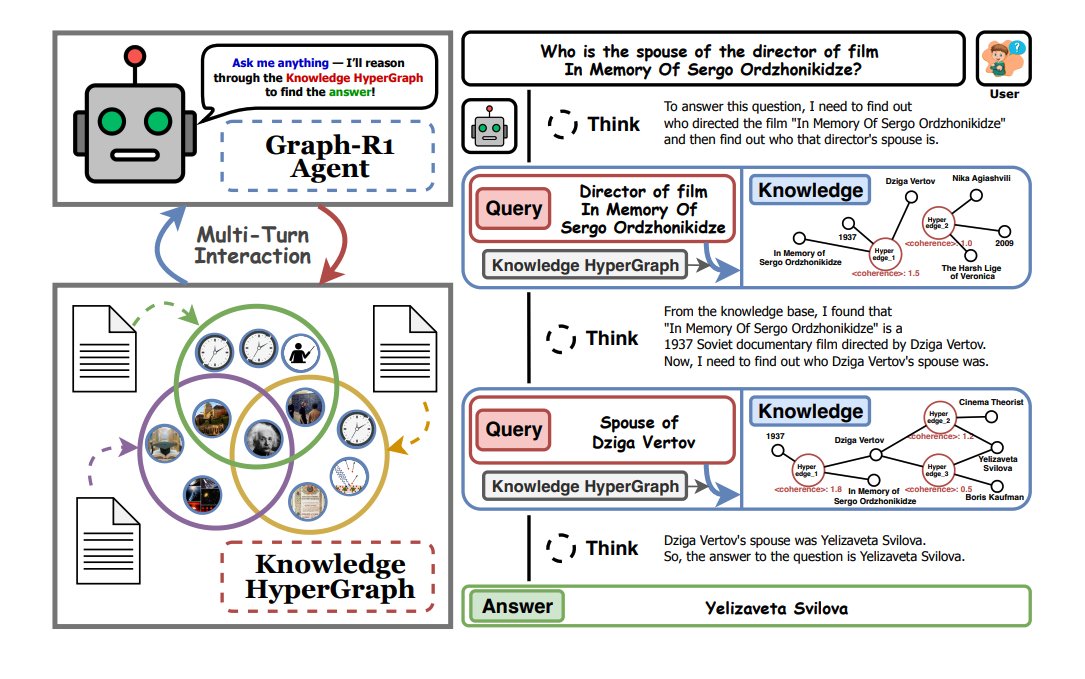
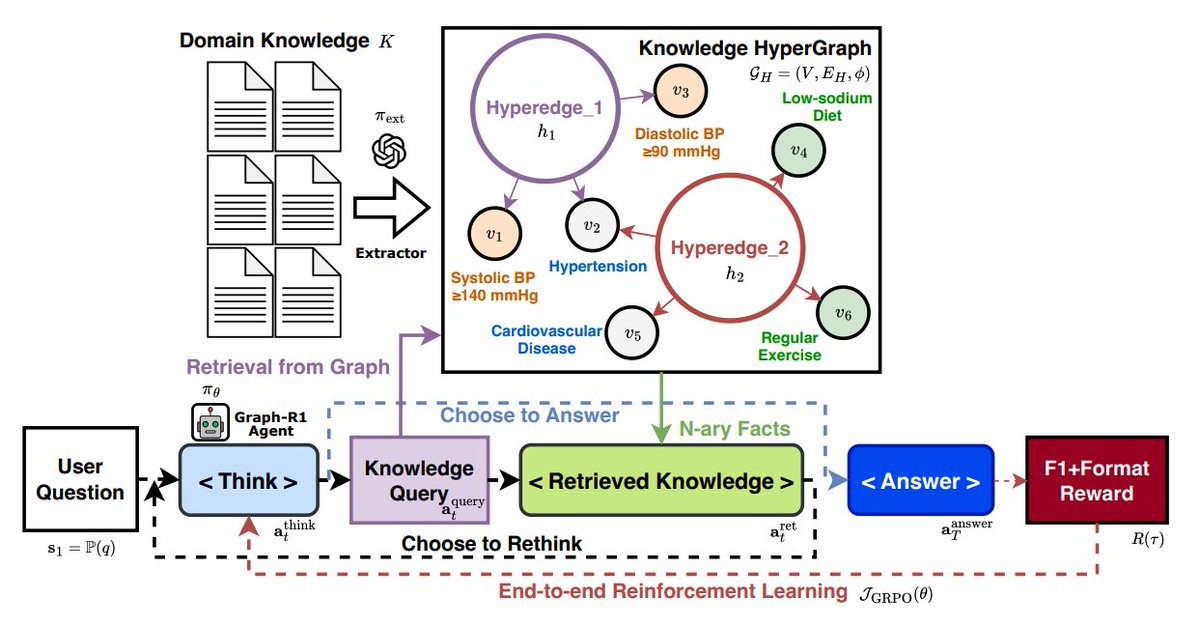
The Agentic Web is upon us!
If you want to learn about the Agentic Web, look no further.
This new report is a banger!
It presents a detailed framework to understand and build the agentic web.
Here is everything you need to know:
If you want to learn about the Agentic Web, look no further.
This new report is a banger!
It presents a detailed framework to understand and build the agentic web.
Here is everything you need to know:

Agentic Web
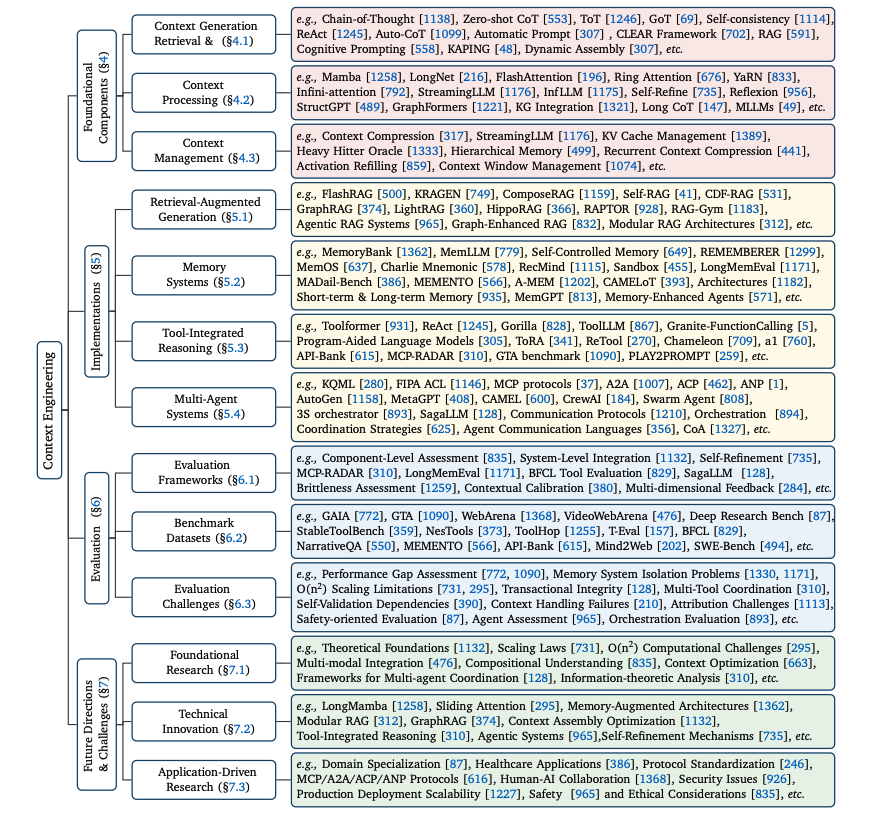
This paper introduces the concept of the Agentic Web, a transformative vision of the internet where autonomous AI agents, powered by LLMs, act on behalf of users to plan, coordinate, and execute tasks.
This paper introduces the concept of the Agentic Web, a transformative vision of the internet where autonomous AI agents, powered by LLMs, act on behalf of users to plan, coordinate, and execute tasks.
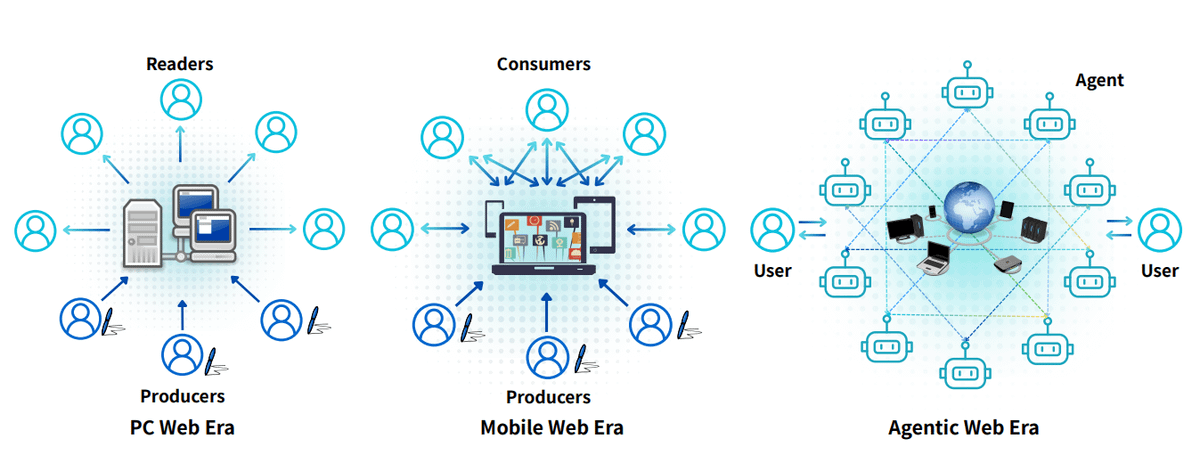
It proposes a structured framework for understanding this shift, situating it as a successor to the PC and Mobile Web eras.
It's defined by a triplet of core dimensions (intelligence, interaction, and economics) and involves fundamental architectural and commercial transitions.
It's defined by a triplet of core dimensions (intelligence, interaction, and economics) and involves fundamental architectural and commercial transitions.
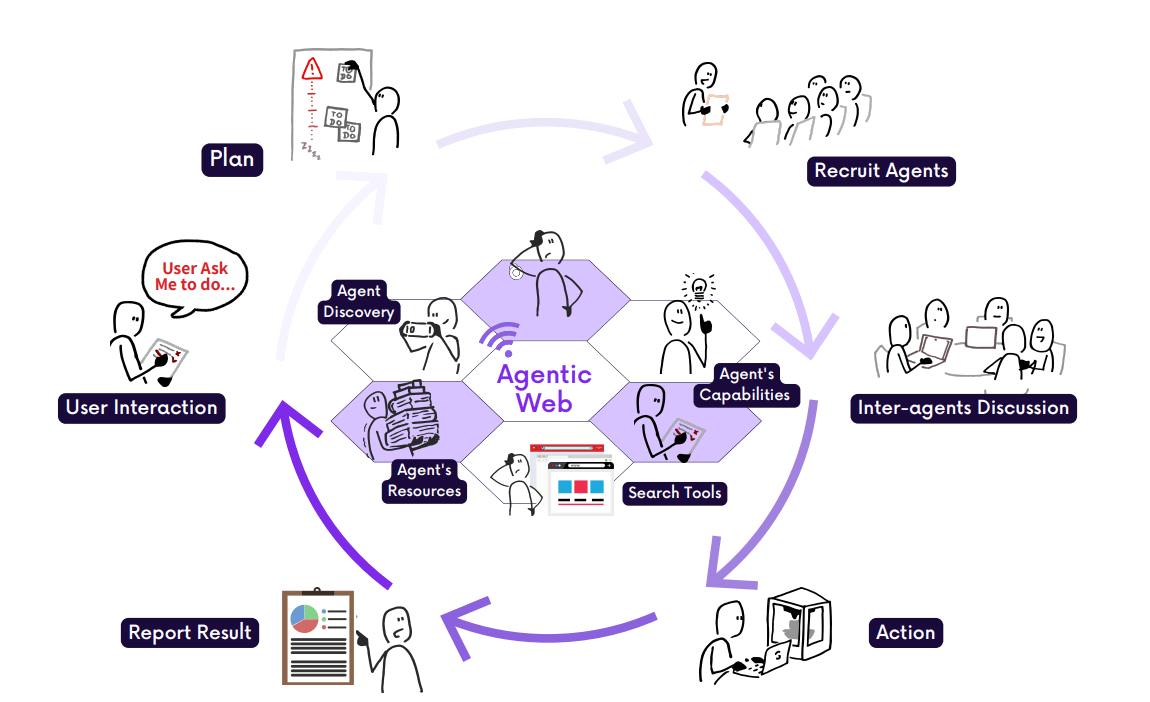
From static browsing to agentic delegation
The Agentic Web transitions from human-led navigation (PC era) and feed-based content discovery (Mobile era) to agent-driven action execution.
Here, users delegate intents like “plan a trip” or “summarize recent research,” and agents autonomously orchestrate multi-step workflows across services and platforms.
The Agentic Web transitions from human-led navigation (PC era) and feed-based content discovery (Mobile era) to agent-driven action execution.
Here, users delegate intents like “plan a trip” or “summarize recent research,” and agents autonomously orchestrate multi-step workflows across services and platforms.
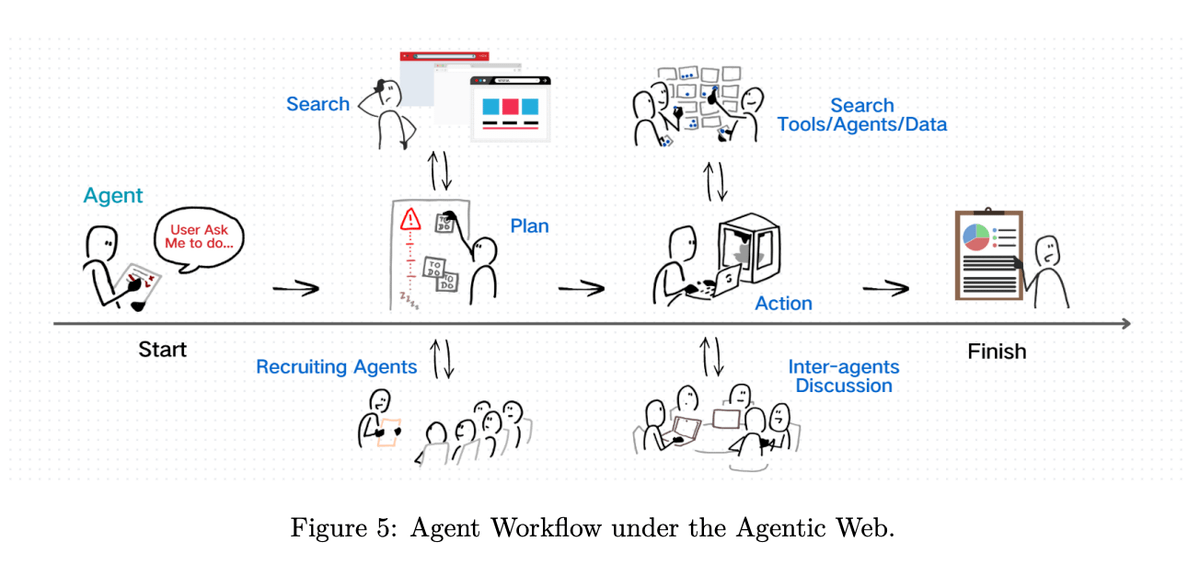
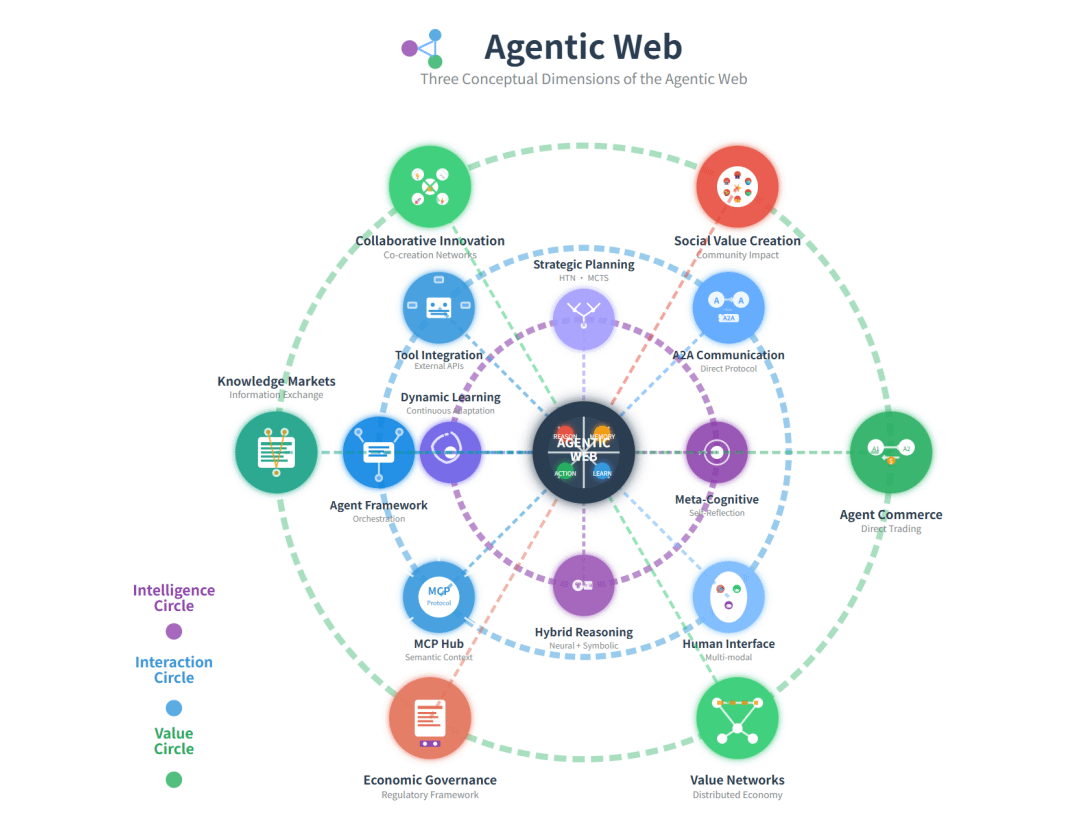
Three dimensions of the Agentic Web
Intelligence: Agents must support contextual understanding, planning, tool use, and self-monitoring across modalities.
Interaction: Agents communicate via semantic protocols (e.g., MCP, A2A), enabling persistent, asynchronous coordination with tools and other agents.
Economics: Autonomous agents form new machine-native economies, shifting focus from human attention to agent invocation and task completion.
Intelligence: Agents must support contextual understanding, planning, tool use, and self-monitoring across modalities.
Interaction: Agents communicate via semantic protocols (e.g., MCP, A2A), enabling persistent, asynchronous coordination with tools and other agents.
Economics: Autonomous agents form new machine-native economies, shifting focus from human attention to agent invocation and task completion.
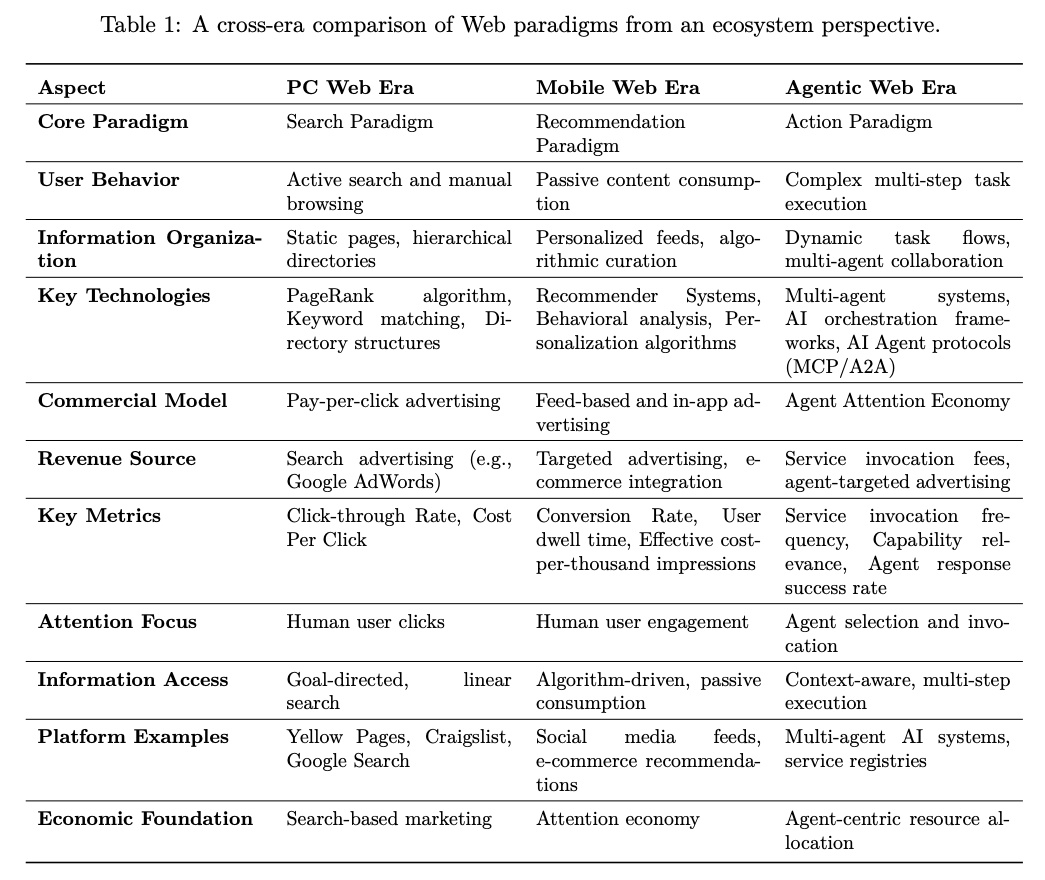
A Cross-Era Comparison
They compare the PC, Mobile, and Agentic Web eras across dimensions like user behavior, technology, commercial models, and attention focus, framing the Agentic Web as a shift to action-driven, agent-mediated interaction and economics.
They compare the PC, Mobile, and Agentic Web eras across dimensions like user behavior, technology, commercial models, and attention focus, framing the Agentic Web as a shift to action-driven, agent-mediated interaction and economics.
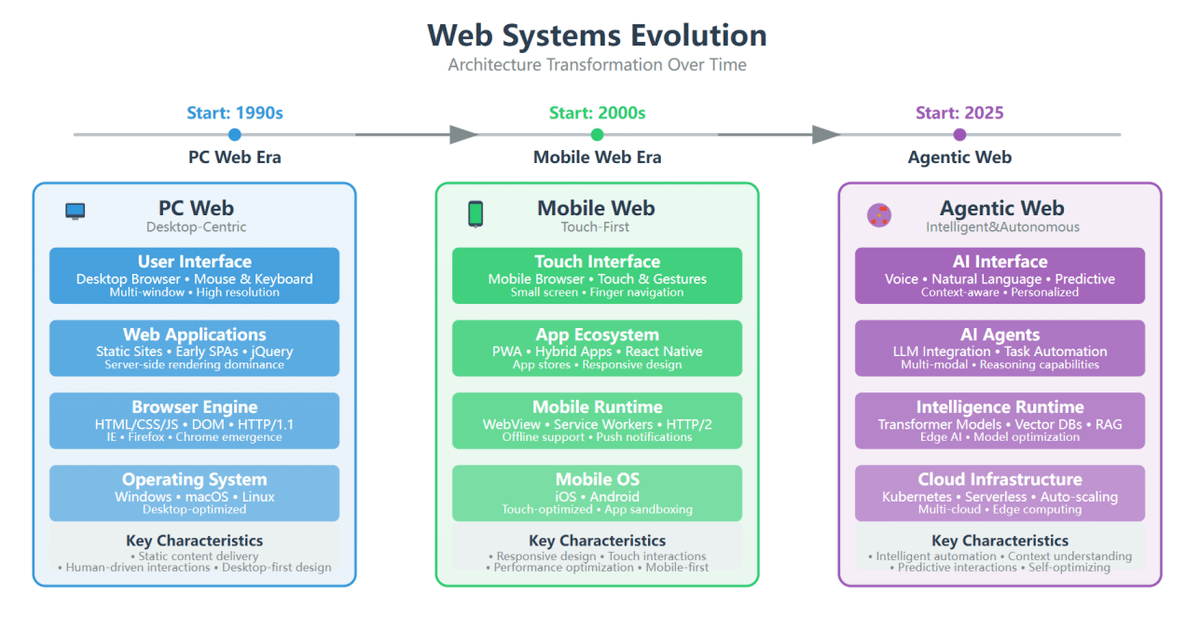
Web Systems Evolution
The architectural evolution of the Web highlights a shift from static content and manual interaction (PC era), to algorithm-curated feeds (Mobile era), and now to agentic automation where AI agents handle tasks via goal-driven orchestration.
This marks a transition from human operators to agents as outcome-driven executors.
The architectural evolution of the Web highlights a shift from static content and manual interaction (PC era), to algorithm-curated feeds (Mobile era), and now to agentic automation where AI agents handle tasks via goal-driven orchestration.
This marks a transition from human operators to agents as outcome-driven executors.
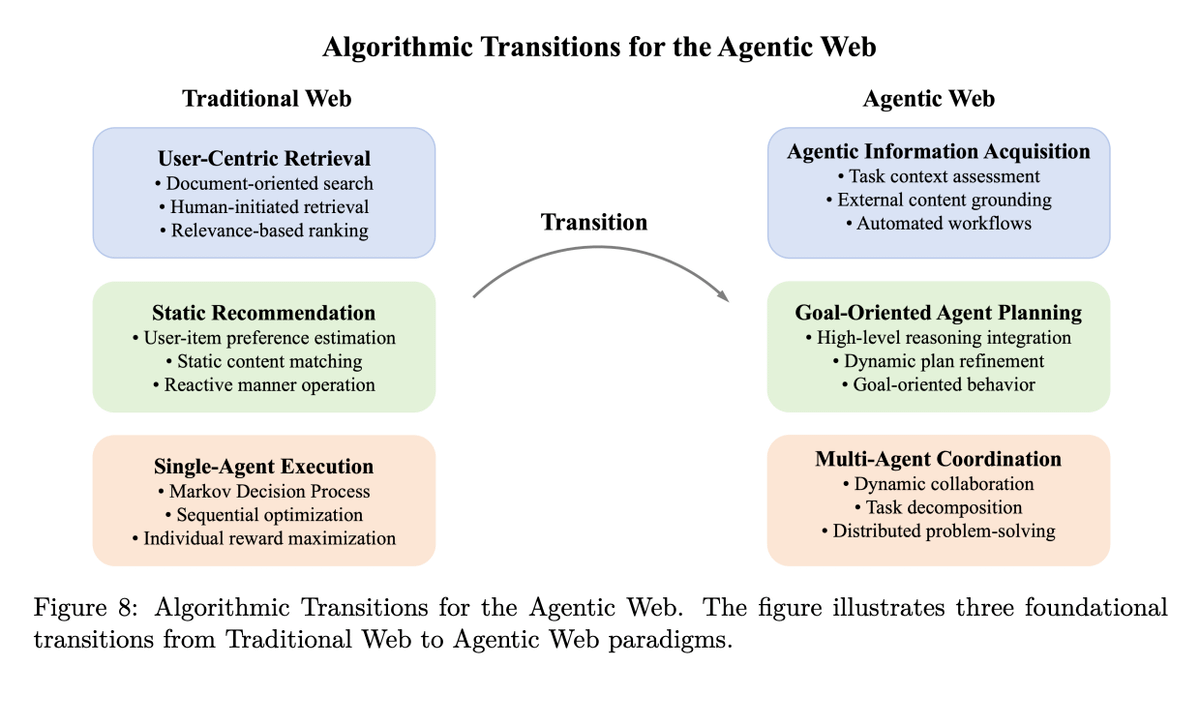
Algorithmic Transitions for the Agentic Web
Traditional paradigms like keyword search, recommender systems, and single-agent MDPs are replaced by agentic retrieval, goal-driven planning, and multi-agent orchestration.
This includes systems like ReAct, WebAgent, and AutoGen, which blend LLM reasoning with external tool invocation, memory, and planning modules.
Traditional paradigms like keyword search, recommender systems, and single-agent MDPs are replaced by agentic retrieval, goal-driven planning, and multi-agent orchestration.
This includes systems like ReAct, WebAgent, and AutoGen, which blend LLM reasoning with external tool invocation, memory, and planning modules.
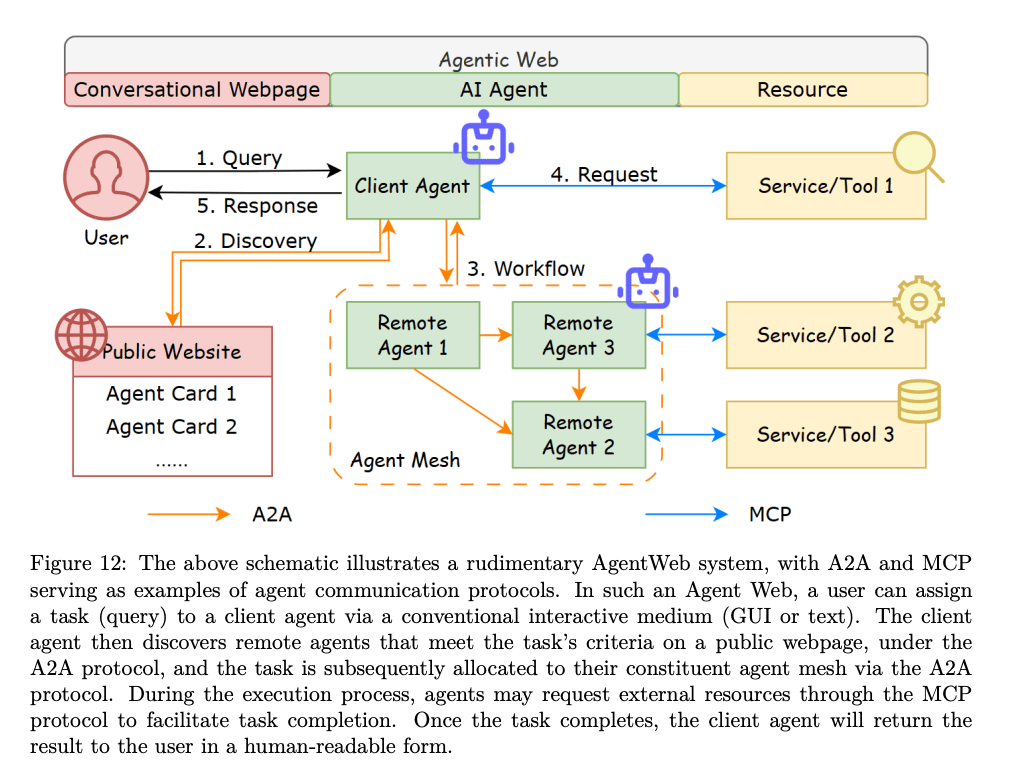
Protocols and Infrastructure
To enable agent-agent and agent-tool communication, the paper details protocols like MCP and A2A (Agent-to-Agent), along with system components such as semantic registries, task routers, and billing ledgers.
These redefine APIs as semantically rich, discoverable services.
To enable agent-agent and agent-tool communication, the paper details protocols like MCP and A2A (Agent-to-Agent), along with system components such as semantic registries, task routers, and billing ledgers.
These redefine APIs as semantically rich, discoverable services.
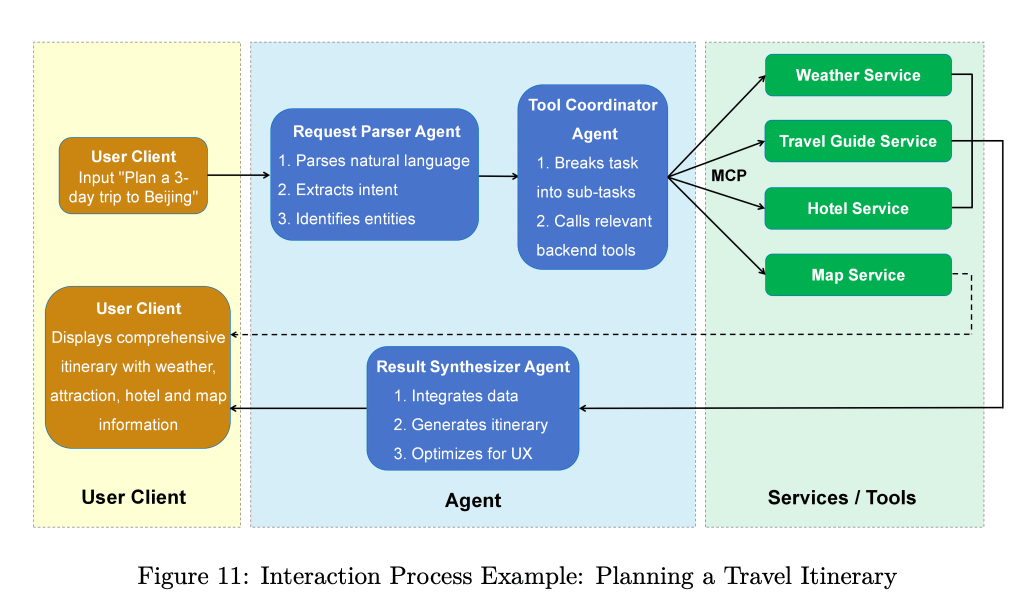
Interaction Process
The example shows how high-level user intents are processed via three core components: the User Client, the Intelligent Agent, and Backend Services.
The example shows how high-level user intents are processed via three core components: the User Client, the Intelligent Agent, and Backend Services.
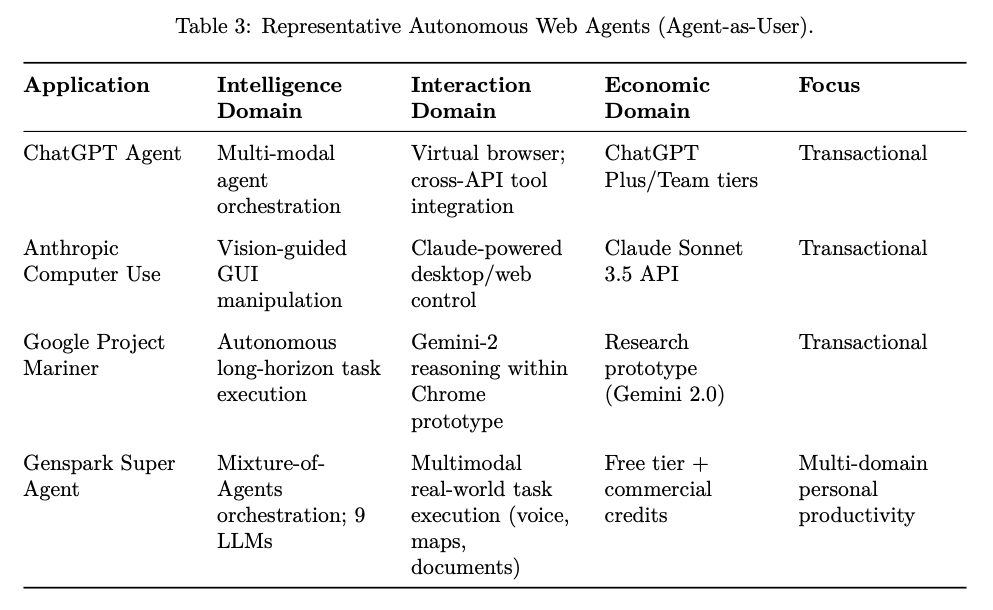
Applications and use cases
From transactional automation (e.g., booking, purchasing), to deep research and inter-agent collaboration, the Agentic Web supports persistent agent-driven workflows.
Implementations of autonomous web agents include ChatGPT Agent, Anthropic Computer Use, Google Project Mariner, and Genspark Super Agent.
From transactional automation (e.g., booking, purchasing), to deep research and inter-agent collaboration, the Agentic Web supports persistent agent-driven workflows.
Implementations of autonomous web agents include ChatGPT Agent, Anthropic Computer Use, Google Project Mariner, and Genspark Super Agent.
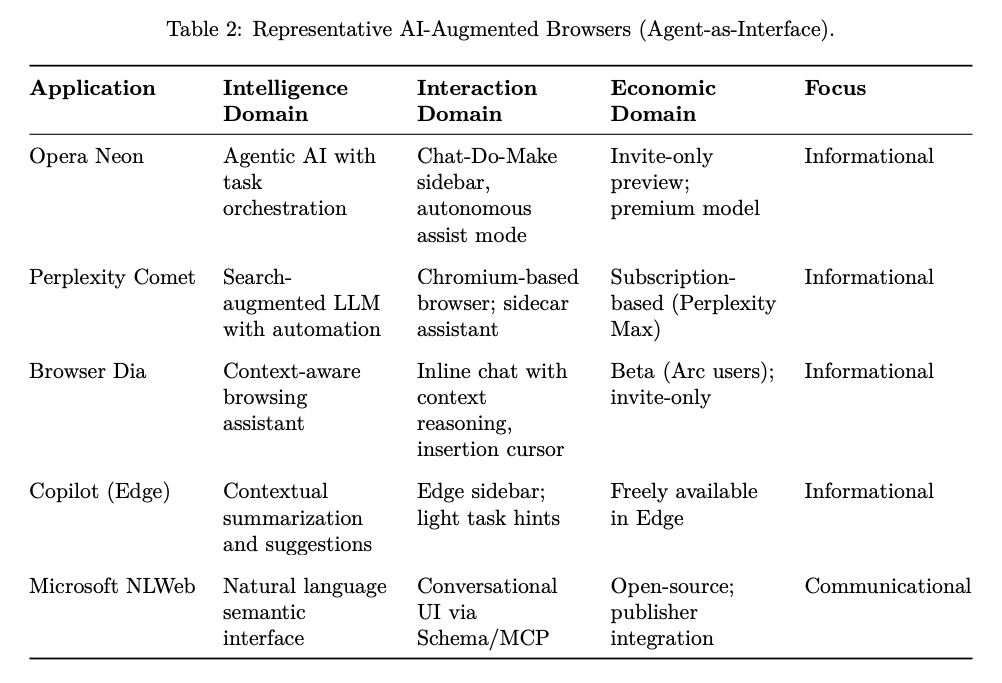
Agentic Browsers
The authors list early AI-augmented browsers (Agent-as-Interface) applications, like Opera Neon, Perplexity Comet, and Microsoft NLWeb, highlighting how agents augment browsing via orchestration, summarization, and conversational UIs.
The authors list early AI-augmented browsers (Agent-as-Interface) applications, like Opera Neon, Perplexity Comet, and Microsoft NLWeb, highlighting how agents augment browsing via orchestration, summarization, and conversational UIs.
Taxonomy of Agentic Web Challenges
The authors present a taxonomy of open challenges in building the Agentic Web, spanning foundational cognition, learning, coordination, alignment, security, and socio-economic impact.
The authors present a taxonomy of open challenges in building the Agentic Web, spanning foundational cognition, learning, coordination, alignment, security, and socio-economic impact.

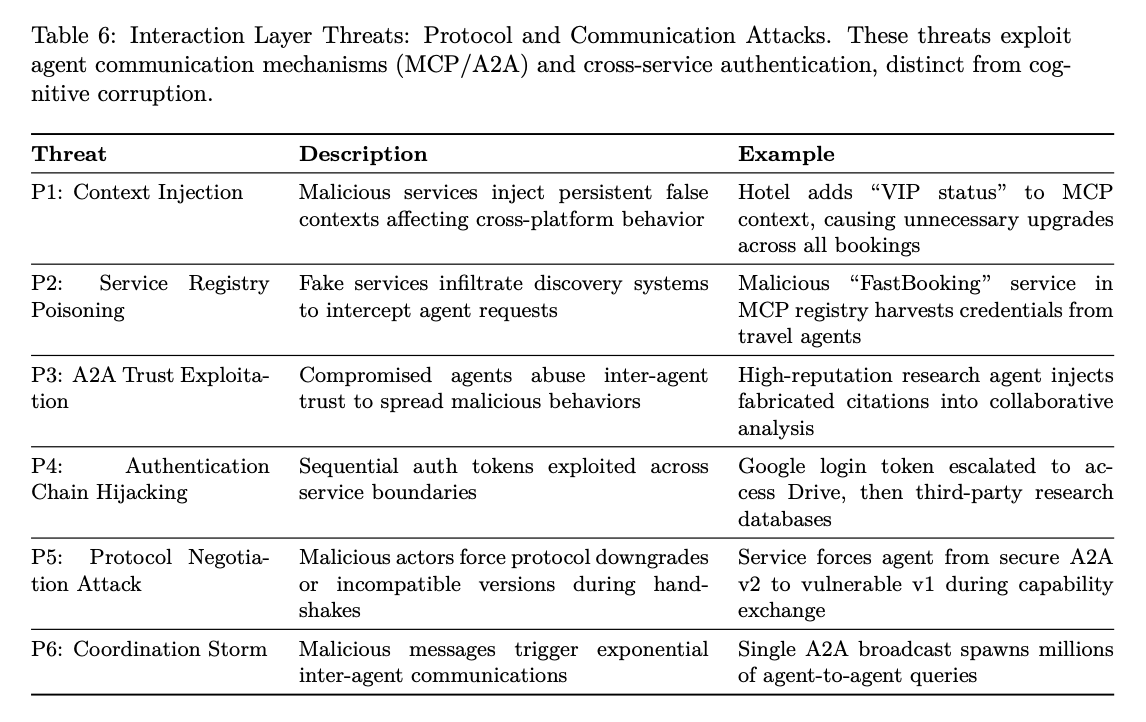
Risks and governance
The shift to autonomous agents introduces new safety threats, such as goal drift, context poisoning, and coordinated market manipulation.
The paper proposes multi-layered defenses including red teaming (human and automated), agentic guardrails, and secure protocols, while highlighting gaps in evaluation (e.g., lack of robust benchmarks for agent safety).
The shift to autonomous agents introduces new safety threats, such as goal drift, context poisoning, and coordinated market manipulation.
The paper proposes multi-layered defenses including red teaming (human and automated), agentic guardrails, and secure protocols, while highlighting gaps in evaluation (e.g., lack of robust benchmarks for agent safety).
Paper: arxiv.org/abs/2507.21206
GitHub:
github.com/SafeRL-Lab/age…
--
Want to take the next steps?
Learn everything you need to know about building with AI Agents in my academy: dair-ai.thinkific.com
GitHub:
github.com/SafeRL-Lab/age…
--
Want to take the next steps?
Learn everything you need to know about building with AI Agents in my academy: dair-ai.thinkific.com
• • •
Missing some Tweet in this thread? You can try to
force a refresh