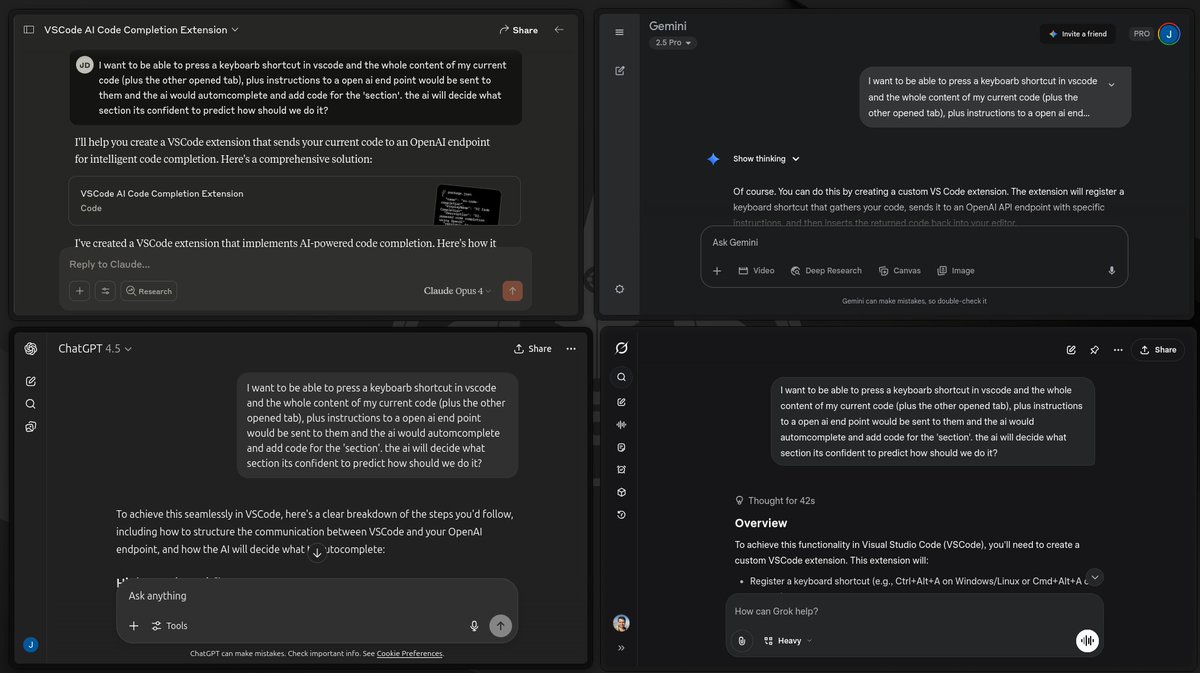
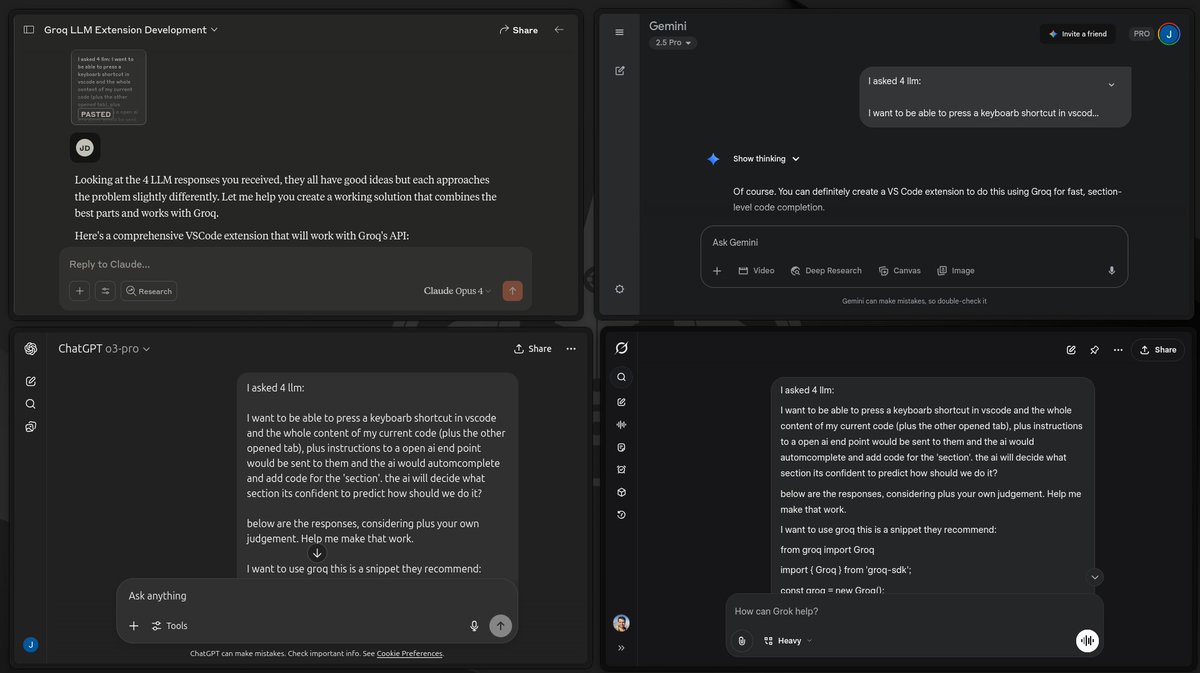
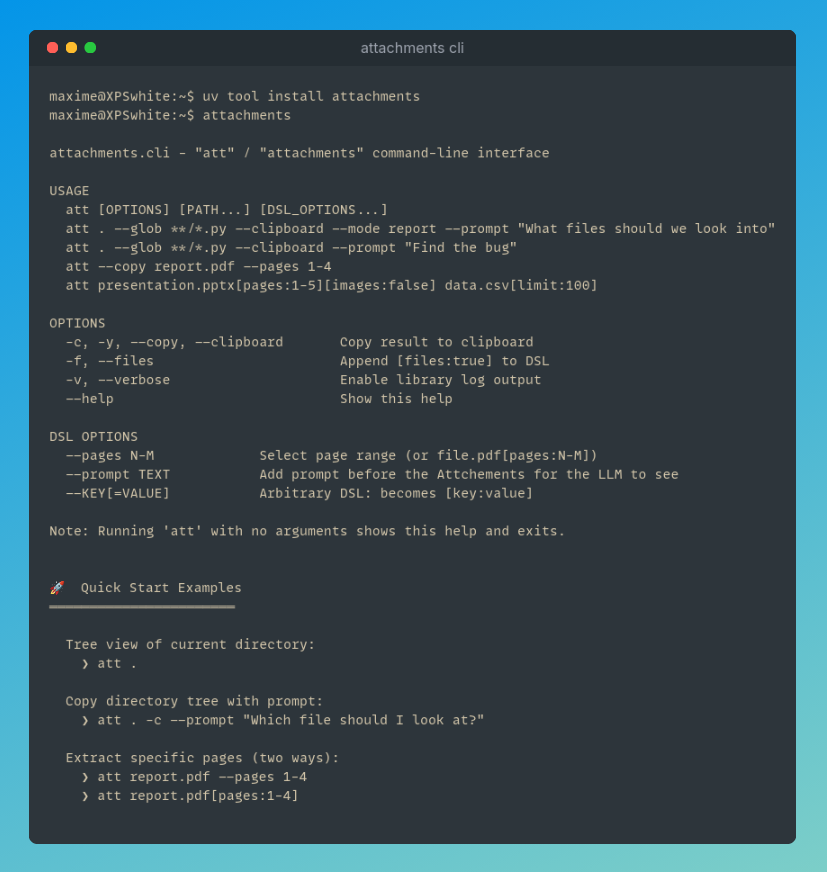
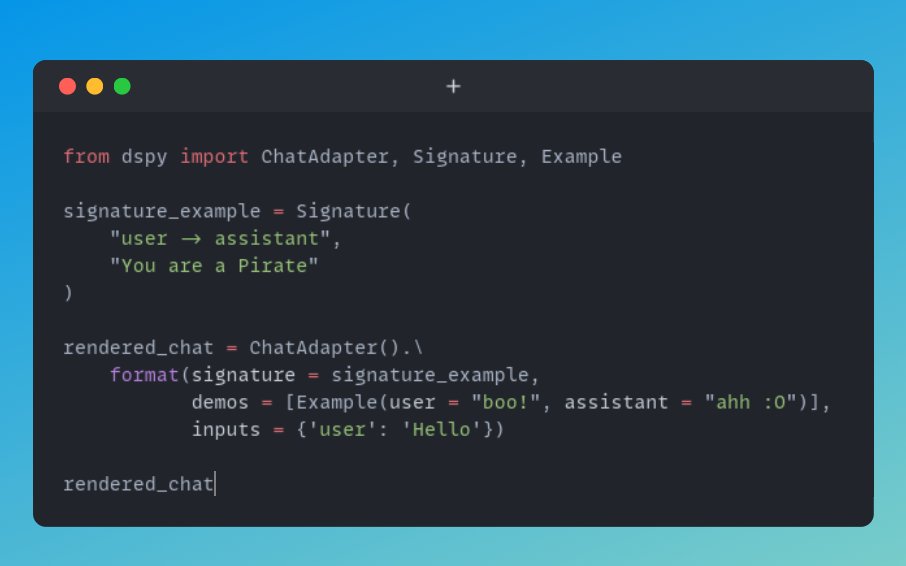
One of the first things I was looking for when I got into dspy was to combine it with offline vllm batch inference.
But the whole dspy stack is built on single calls, supporting retries and asynchronicity etc.
Still, I wanted to be able to use dspy easily with performant locally hosted models.
After much fiddling and tinkering here and there, I found the special incantation to make vllm and dspy work together. It was a bit too long to just share the snippet of code, so I wrapped it up into a library. It's a 1 file init.py 500 LOC library, it should not be too hard for me (us :D) to maintain. It is quite powerful!
In my performance test, vllm directly was running my task in 65 seconds; through dspy, it's 68 seconds.
So here it is:
uv venv
source .venv/bin/activate
uv python install 3.12 --default
uv pip install ovllm
ps: vllm 0.10.0 has a dependency that does not work with Python 3.13 for now.
But the whole dspy stack is built on single calls, supporting retries and asynchronicity etc.
Still, I wanted to be able to use dspy easily with performant locally hosted models.
After much fiddling and tinkering here and there, I found the special incantation to make vllm and dspy work together. It was a bit too long to just share the snippet of code, so I wrapped it up into a library. It's a 1 file init.py 500 LOC library, it should not be too hard for me (us :D) to maintain. It is quite powerful!
In my performance test, vllm directly was running my task in 65 seconds; through dspy, it's 68 seconds.
So here it is:
uv venv
source .venv/bin/activate
uv python install 3.12 --default
uv pip install ovllm
ps: vllm 0.10.0 has a dependency that does not work with Python 3.13 for now.

• • •
Missing some Tweet in this thread? You can try to
force a refresh