
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead

🧵1/9
MCP (Model Context Protocol) provides an interface for connecting AI and applications and has gained tremendous interest within the AI community.
But how well do models handle MCP uses? Frontier LLMs are actually pretty good, so we created MCPMark, a challenging evaluation set to stress-test the models. 😈
🔗Links:
Github: github.com/eval-sys/mcpma…
Website: mcpmark.ai
MCP (Model Context Protocol) provides an interface for connecting AI and applications and has gained tremendous interest within the AI community.
But how well do models handle MCP uses? Frontier LLMs are actually pretty good, so we created MCPMark, a challenging evaluation set to stress-test the models. 😈
🔗Links:
Github: github.com/eval-sys/mcpma…
Website: mcpmark.ai
🧵2/9
To rigorously evaluate the capabilities for MCP use, we adopted the OpenAI Agents SDK as the default agent framework, as it is powerful and broadly compatible.
General:
-🤔For most models (excluding GPT-5), pass@1 doesn’t exceed 30%.
- Although still lagging behind top proprietary models, open-source models (e.g., Qwen-3-Coder, K2) perform well, with overall pass@1 reaching around 20%.
- Task difficulties varies across MCPs — Postgres tends to be easier since models are quite familiar with databases and query operations, while Notion is harder because good training data is hard to get and its underlying data structure is pretty tangled.
Model-Specific:
- GPT-5 shows the most impressive performance, clearly ahead of the others. Claude is strong across every MCP and ranks just behind GPT-5 overall.
- Qwen-3-Coder stands out among open-source models, slightly ahead of both K2 and DeepSeek-V3.1 on Pass@1 and Pass@4.
- K2 underperforms on Pass@1, but its Pass^4 results rival Claude-4-Sonnet, highlighting its stability across attempts.
To rigorously evaluate the capabilities for MCP use, we adopted the OpenAI Agents SDK as the default agent framework, as it is powerful and broadly compatible.
General:
-🤔For most models (excluding GPT-5), pass@1 doesn’t exceed 30%.
- Although still lagging behind top proprietary models, open-source models (e.g., Qwen-3-Coder, K2) perform well, with overall pass@1 reaching around 20%.
- Task difficulties varies across MCPs — Postgres tends to be easier since models are quite familiar with databases and query operations, while Notion is harder because good training data is hard to get and its underlying data structure is pretty tangled.
Model-Specific:
- GPT-5 shows the most impressive performance, clearly ahead of the others. Claude is strong across every MCP and ranks just behind GPT-5 overall.
- Qwen-3-Coder stands out among open-source models, slightly ahead of both K2 and DeepSeek-V3.1 on Pass@1 and Pass@4.
- K2 underperforms on Pass@1, but its Pass^4 results rival Claude-4-Sonnet, highlighting its stability across attempts.


🧵3/9
Token usage and cost vary dramatically across models — some models burn way more tokens (and 💸) than others.
- Claude-4.1-Opus → extremely pricey: $1,137
- Claude-4-Sonnet → $241
- GPT-5 → $123 (but heavy output token usage)
- Open-source models are much cheaper:
* Qwen-3-Coder: $33
* DeepSeek-V3.1: $17
* K2: just $8.5
This cost gap highlights the tradeoff between raw performance vs. efficiency.⚖️
👉 Note: Token usage information for Grok-4 is currently unavailable, so it has been excluded from this table.
Token usage and cost vary dramatically across models — some models burn way more tokens (and 💸) than others.
- Claude-4.1-Opus → extremely pricey: $1,137
- Claude-4-Sonnet → $241
- GPT-5 → $123 (but heavy output token usage)
- Open-source models are much cheaper:
* Qwen-3-Coder: $33
* DeepSeek-V3.1: $17
* K2: just $8.5
This cost gap highlights the tradeoff between raw performance vs. efficiency.⚖️
👉 Note: Token usage information for Grok-4 is currently unavailable, so it has been excluded from this table.

🧵4/9
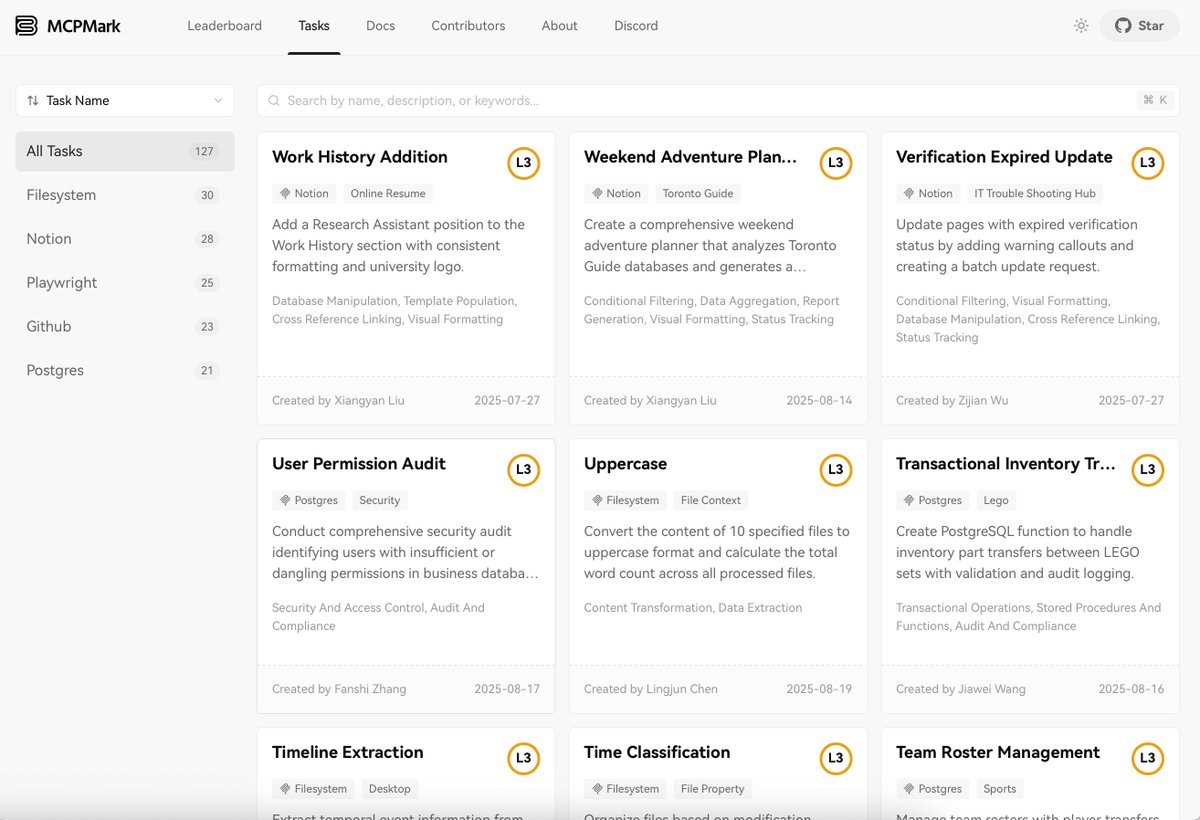
We didn’t just benchmark models — we made the results explorable. 🌐
On our website () you can:
- See leaderboards across MCP tasks
- Drill down into single task runs with logs & token stats
- Compare models on specific MCP servers (e.g. Notion, GitHub, Filesystem…)
Plenty to explore 🔍mcpmark.ai
We didn’t just benchmark models — we made the results explorable. 🌐
On our website () you can:
- See leaderboards across MCP tasks
- Drill down into single task runs with logs & token stats
- Compare models on specific MCP servers (e.g. Notion, GitHub, Filesystem…)
Plenty to explore 🔍mcpmark.ai


🧵5/9
Want to see MCP in action? 👀
We recorded two demos showing how models actually complete tasks through MCP calls:
1️⃣GitHub MCP – model sets up a proper linting workflow for a CI pipeline.
2️⃣Notion MCP – model manages a personal travel plan with multiple function calls.
📹 Watch how models chain raw MCP calls to get real work done ⬇️
Want to see MCP in action? 👀
We recorded two demos showing how models actually complete tasks through MCP calls:
1️⃣GitHub MCP – model sets up a proper linting workflow for a CI pipeline.
2️⃣Notion MCP – model manages a personal travel plan with multiple function calls.
📹 Watch how models chain raw MCP calls to get real work done ⬇️
🧵6/9
So how did we annotate the data? We worked hand in hand with AI agents, involving these steps:
1. Exploration: starting from an initial instruction, a human and a task agent jointly explore the environment and gather relevant details.
2. Task design: the agent makes the initial instruction harder and richer. Human makes sure it’s practical, verifiable and challenging.
3. Verification design: the agent writes a draft verification script. Human checks the correctness and consistency.
4. Iteration: Loop through step 2 and 3 to iteratively increase the difficulty while keeping the task verifiable.
Occasionally, in a stroke of inspiration, we skip the agent and create the task directly.
Even with the help of agents, each sample takes 3-5 hours of focused expert efforts.
So how did we annotate the data? We worked hand in hand with AI agents, involving these steps:
1. Exploration: starting from an initial instruction, a human and a task agent jointly explore the environment and gather relevant details.
2. Task design: the agent makes the initial instruction harder and richer. Human makes sure it’s practical, verifiable and challenging.
3. Verification design: the agent writes a draft verification script. Human checks the correctness and consistency.
4. Iteration: Loop through step 2 and 3 to iteratively increase the difficulty while keeping the task verifiable.
Occasionally, in a stroke of inspiration, we skip the agent and create the task directly.
Even with the help of agents, each sample takes 3-5 hours of focused expert efforts.
🧵7/9
How are we different from other MCP benchmarks?
MCPMark is built to stress-test models with challenging, comprehensive tasks that balance different CRUD (create, read, update, and delete) operations while enforcing strict environment managements. Each task includes an independent initial state, a custom verification script, and a state reset mechanism, similar to the state tracking practice from OSWorld.
To ensure safety and reliability, all tasks are executed in isolated sandboxes, either access-controlled or containerized, and their results are validated automatically rather than relying on LLM-as-Judge evaluations. On average, each task involves 16.2 function calls, pushing models closer to their performance boundaries in complex, real-world contexts.
How are we different from other MCP benchmarks?
MCPMark is built to stress-test models with challenging, comprehensive tasks that balance different CRUD (create, read, update, and delete) operations while enforcing strict environment managements. Each task includes an independent initial state, a custom verification script, and a state reset mechanism, similar to the state tracking practice from OSWorld.
To ensure safety and reliability, all tasks are executed in isolated sandboxes, either access-controlled or containerized, and their results are validated automatically rather than relying on LLM-as-Judge evaluations. On average, each task involves 16.2 function calls, pushing models closer to their performance boundaries in complex, real-world contexts.

🧵8/9
This work is a result of an amazing collaboration between our lab TRAIL at NUS, @EvalSysOrg and @lobehub.
- @arvinxu95, @AllisonXinyuan, and me helped and guided most parts of the project.
- @Jaku_metsu and @dobogiyy led the implementation of the eval pipeline and task design.
- Tremendous efforts were spent in data creation:
* Notion: @dobogiyy, @Jaku_metsu
* Playwright: @FanqingMengAI, @yaoqiye318, @arvinxu95, @AllisonXinyuan, @dobogiyy
* Filesystem: @DDDDDomain, @AllisonXinyuan, @dobogiyy
* Postgres: @cierra_0506, @JarvisMSUstc, @ayakaneko, @dobogiyy
* Github: @Jaku_metsu, @dobogiyy
- We’re also incredibly lucky to have engineering support from @arvinxu95, @ayakaneko & @AllisonXinyuan — nearly 20k lines of code + major environment optimizations! And big thanks to the @lobehub team for their expertise & insights on MCP servers for task creation.
- Beautifully designed website from @canisminor1990 and @arvinxu95. Writings coming from @yiran_zhao924 and others.
And more contributors to be included in the paper.
This work is a result of an amazing collaboration between our lab TRAIL at NUS, @EvalSysOrg and @lobehub.
- @arvinxu95, @AllisonXinyuan, and me helped and guided most parts of the project.
- @Jaku_metsu and @dobogiyy led the implementation of the eval pipeline and task design.
- Tremendous efforts were spent in data creation:
* Notion: @dobogiyy, @Jaku_metsu
* Playwright: @FanqingMengAI, @yaoqiye318, @arvinxu95, @AllisonXinyuan, @dobogiyy
* Filesystem: @DDDDDomain, @AllisonXinyuan, @dobogiyy
* Postgres: @cierra_0506, @JarvisMSUstc, @ayakaneko, @dobogiyy
* Github: @Jaku_metsu, @dobogiyy
- We’re also incredibly lucky to have engineering support from @arvinxu95, @ayakaneko & @AllisonXinyuan — nearly 20k lines of code + major environment optimizations! And big thanks to the @lobehub team for their expertise & insights on MCP servers for task creation.
- Beautifully designed website from @canisminor1990 and @arvinxu95. Writings coming from @yiran_zhao924 and others.
And more contributors to be included in the paper.
@EvalSysOrg @lobehub @arvinxu95 @AllisonXinyuan @Jaku_metsu @dobogiyy 🧵9/9
We will actively maintain MCPMark and make sure that everything works.
@EvalSysOrg has many exciting future projects to come. We will also release more contents there. Feel free to follow us!
Stay tuned!
We will actively maintain MCPMark and make sure that everything works.
@EvalSysOrg has many exciting future projects to come. We will also release more contents there. Feel free to follow us!
Stay tuned!

• • •
Missing some Tweet in this thread? You can try to
force a refresh



