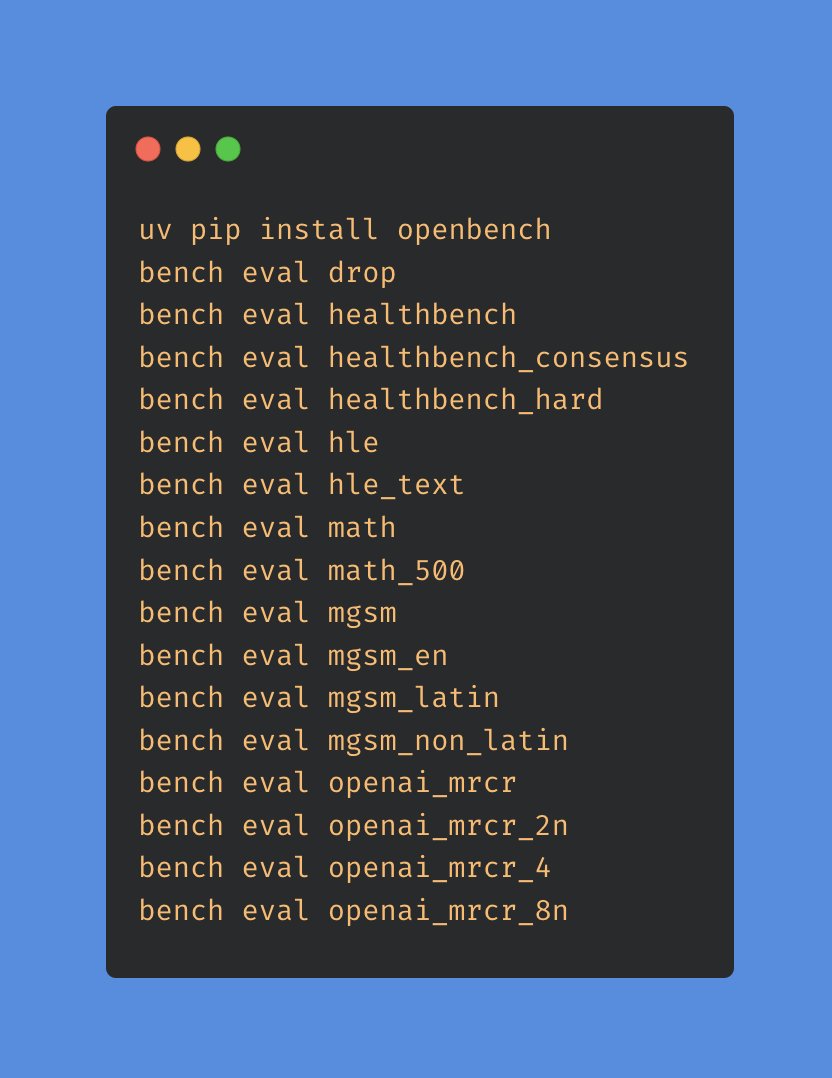
OpenBench 0.4.0 is here!
We collaborated with @PrimeIntellect, @rootlyhq, @vercel and more for some new features for y'all. details below 🧵
We collaborated with @PrimeIntellect, @rootlyhq, @vercel and more for some new features for y'all. details below 🧵
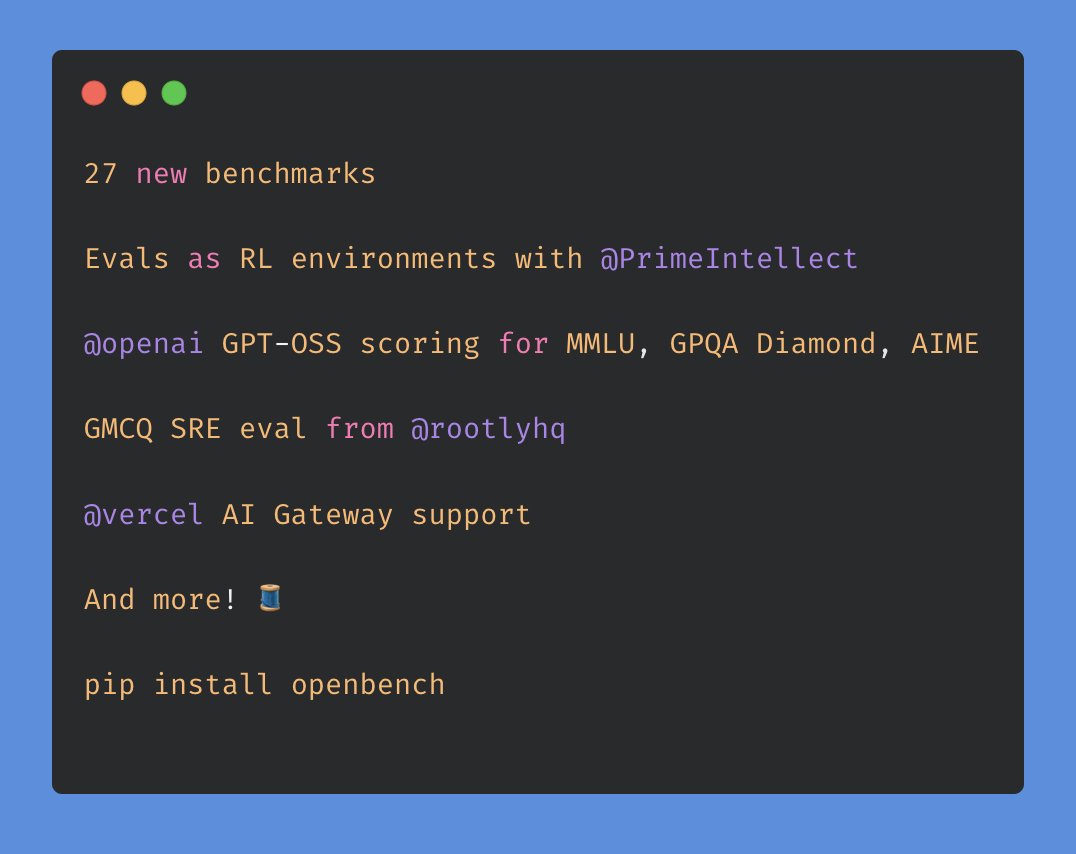
Here's your quick TL;DR:
3/ 🤝 Prime Intellect Integration
We've partnered with @PrimeIntellect & @willccbb, making OpenBench evals directly runnable as RL environments. Define your evaluation once, seamlessly push it to Prime Intellect’s Environments Hub, and immediately begin training models tailored specifically to your tasks.
This turns evaluations into real, actionable training loops - closing the gap between testing and training.
Check it out here:
app.primeintellect.ai/dashboard/envi…
We've partnered with @PrimeIntellect & @willccbb, making OpenBench evals directly runnable as RL environments. Define your evaluation once, seamlessly push it to Prime Intellect’s Environments Hub, and immediately begin training models tailored specifically to your tasks.
This turns evaluations into real, actionable training loops - closing the gap between testing and training.
Check it out here:
app.primeintellect.ai/dashboard/envi…
4/ 🧩 GPT-OSS Scoring (via OpenAI)
Through our partnership with @OpenAI re: the GPT-OSS release, we've integrated their GPT-OSS scoring patterns into benchmarks like MMLU, GPQA Diamond, and MathArena (AIME, BRUMO, HMMT). Now, you can precisely reproduce OpenAI’s evaluation methodology across all models and providers.
Accurate scoring leads to more meaningful, reliable comparisons.
Through our partnership with @OpenAI re: the GPT-OSS release, we've integrated their GPT-OSS scoring patterns into benchmarks like MMLU, GPQA Diamond, and MathArena (AIME, BRUMO, HMMT). Now, you can precisely reproduce OpenAI’s evaluation methodology across all models and providers.
Accurate scoring leads to more meaningful, reliable comparisons.
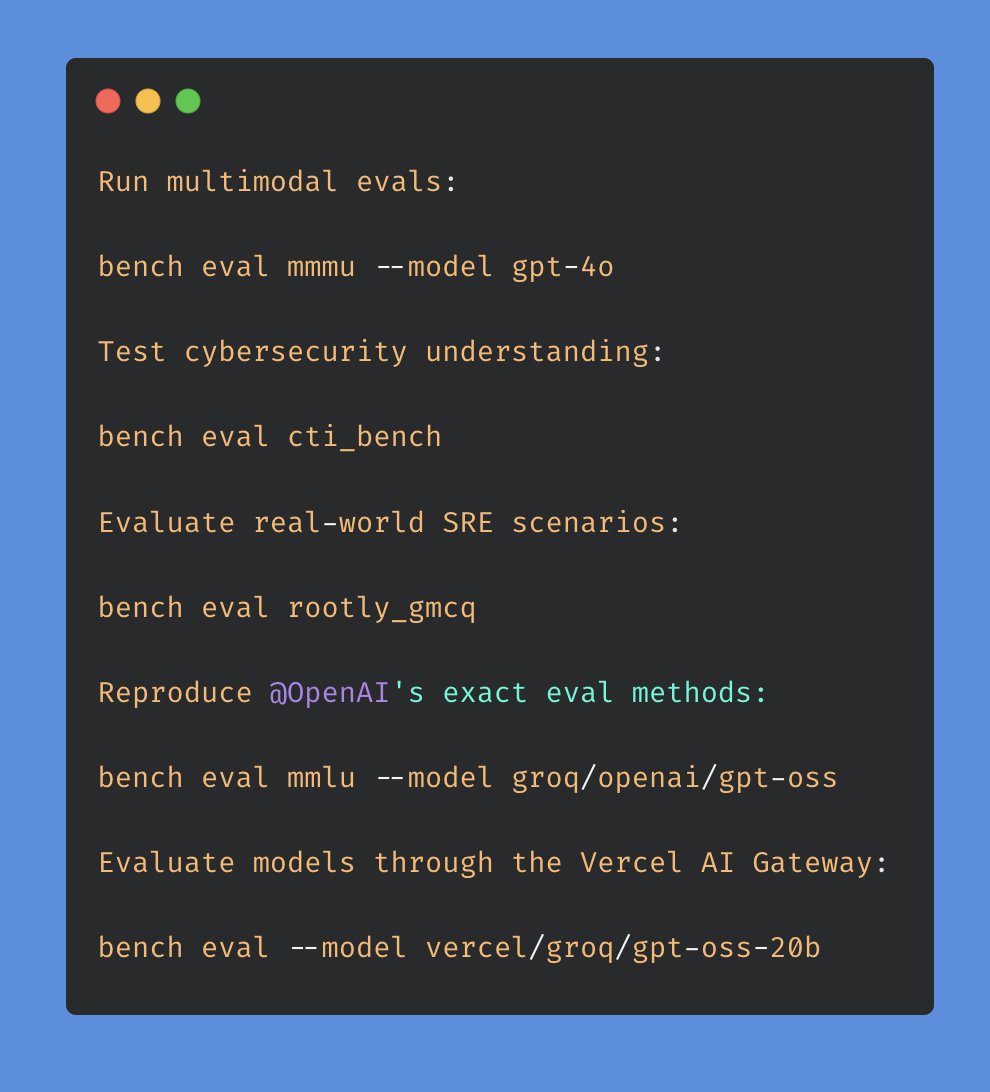
5/ 🔐 CTI-Bench: AI Evaluations Ecosystem (w/ @toParkerJohnson)
We're also adding CTI-Bench, an eval for evaluating LLMs in cyber threat intelligence, to OpenBench. This is the first step we're taking towards adding OpenBench into the AI Evaluations ecosystem that @DavidSacks, @howardlutnick, and the White House have been building for safe, transparent AI assessment.
We're also adding CTI-Bench, an eval for evaluating LLMs in cyber threat intelligence, to OpenBench. This is the first step we're taking towards adding OpenBench into the AI Evaluations ecosystem that @DavidSacks, @howardlutnick, and the White House have been building for safe, transparent AI assessment.
6/ 🚒 Rootly GMCQ: Real-world SRE Benchmark
Thanks to @rootlyhq, we’ve added Rootly GMCQ to OpenBench. This benchmark is specifically designed to test real-world SRE tasks, such as incident triage, log analysis, and outage mitigation. This is the first-open-sourcing of an eval through OpenBench where we collaborate with the eval creators, @LaurenceLiang1 and @SylvainKalache!
Easily accessible via: bench eval rootly_gmcq
x.com/rootlyhq/statu…
Thanks to @rootlyhq, we’ve added Rootly GMCQ to OpenBench. This benchmark is specifically designed to test real-world SRE tasks, such as incident triage, log analysis, and outage mitigation. This is the first-open-sourcing of an eval through OpenBench where we collaborate with the eval creators, @LaurenceLiang1 and @SylvainKalache!
Easily accessible via: bench eval rootly_gmcq
x.com/rootlyhq/statu…
7/ 🚀 Vercel AI Gateway Integration
We collaborated with @vercel, integrating their AI Gateway to enable evaluations directly against any model available in their router. Try it out:
Simplified access, seamless performance.
We collaborated with @vercel, integrating their AI Gateway to enable evaluations directly against any model available in their router. Try it out:
Simplified access, seamless performance.

8/ 📌 Additional Enhancements
We've also included several other key improvements:
MMLU-Pro for advanced reasoning assessments (h/t @TelepathicPug)
BoolQ for binary reasoning tasks (h/t @LaurenceLiang1)
JSONSchemaBench to evaluate structured outputs (h/t @alexbowe)
BrowseComp for web navigation reasoning
Improved dependency management with >= constraints for smoother updates
We've also included several other key improvements:
MMLU-Pro for advanced reasoning assessments (h/t @TelepathicPug)
BoolQ for binary reasoning tasks (h/t @LaurenceLiang1)
JSONSchemaBench to evaluate structured outputs (h/t @alexbowe)
BrowseComp for web navigation reasoning
Improved dependency management with >= constraints for smoother updates
9/ 🚀 We're hiring!
We're iterating quickly on OpenBench and looking to grow our team! The best way to join us is to make contributions based on our issues list - submit PRs and send me your resume on X, let's chat :)
We're iterating quickly on OpenBench and looking to grow our team! The best way to join us is to make contributions based on our issues list - submit PRs and send me your resume on X, let's chat :)
10/ ⭐ Get started!
If you'd like to check out OpenBench or contribute, check us out/give us a star on Github! We're always building out new features, and if you run into any issues feel free to ping me here or file one in the repo.
github.com/groq/openbench
If you'd like to check out OpenBench or contribute, check us out/give us a star on Github! We're always building out new features, and if you run into any issues feel free to ping me here or file one in the repo.
github.com/groq/openbench
• • •
Missing some Tweet in this thread? You can try to
force a refresh