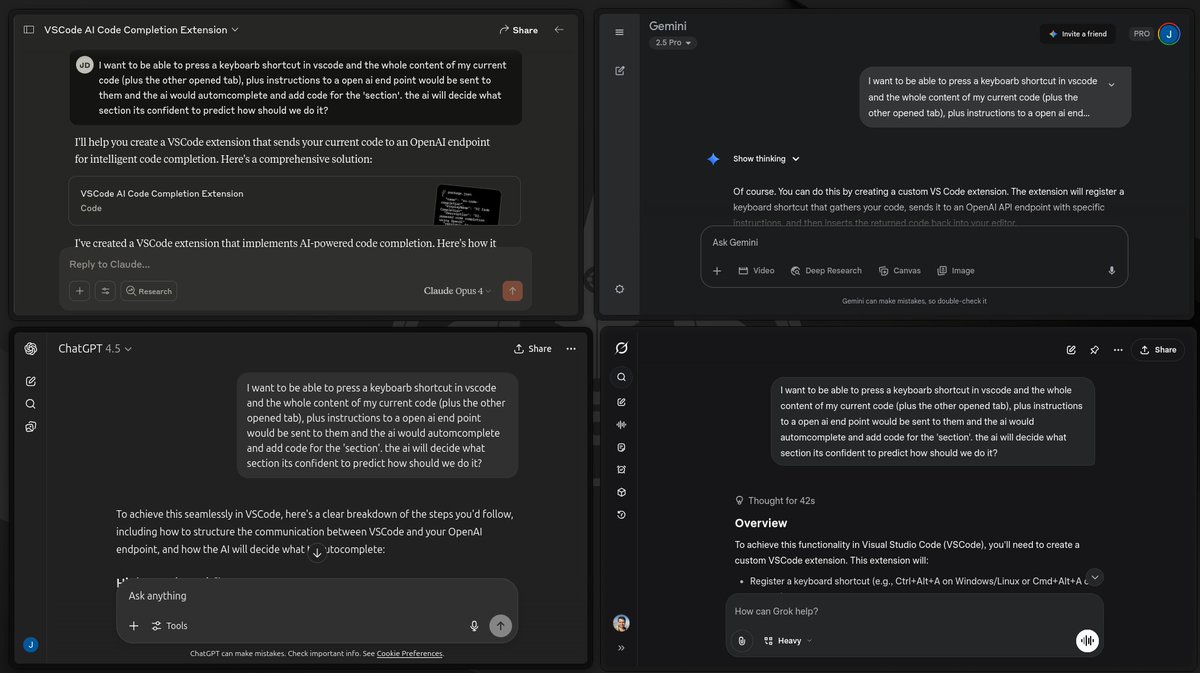
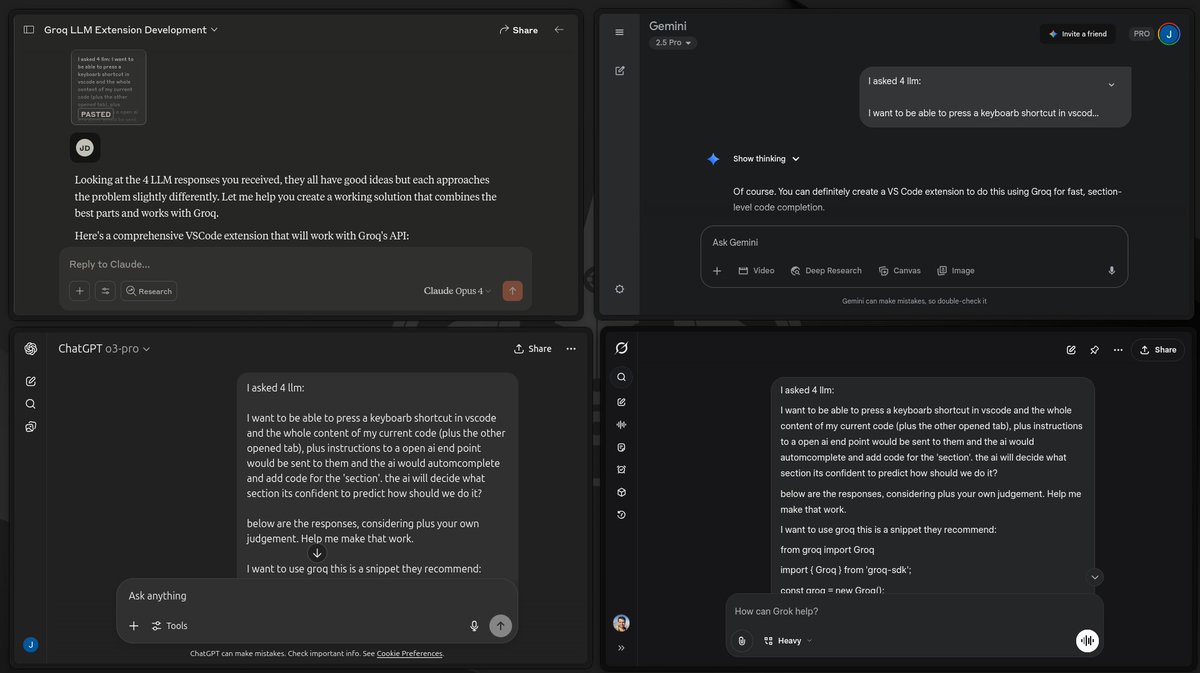
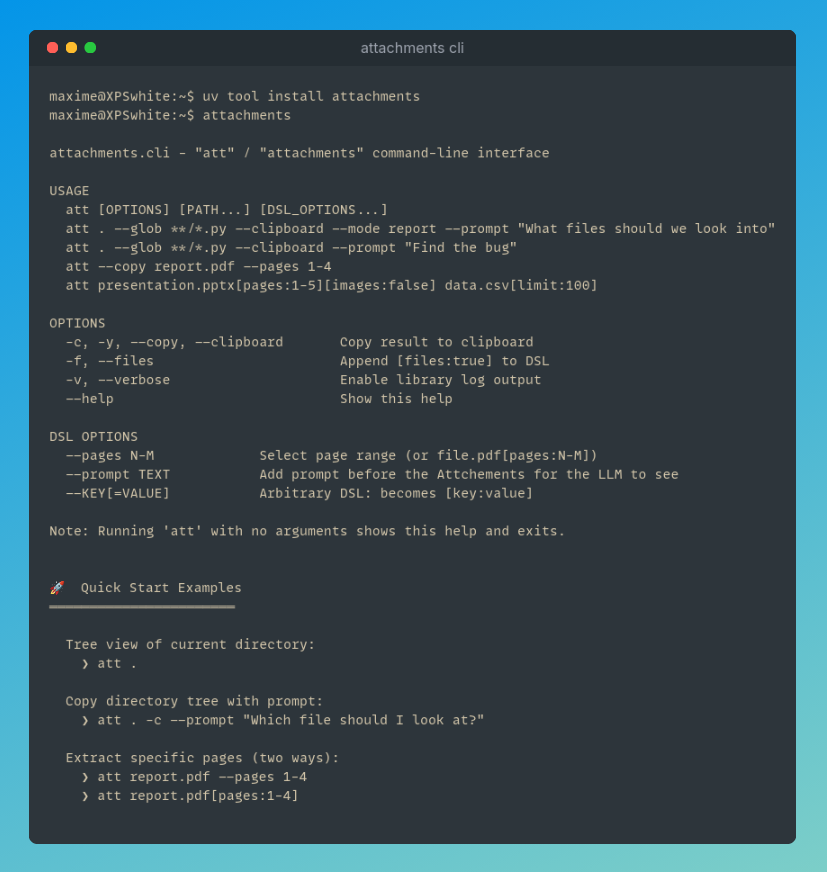
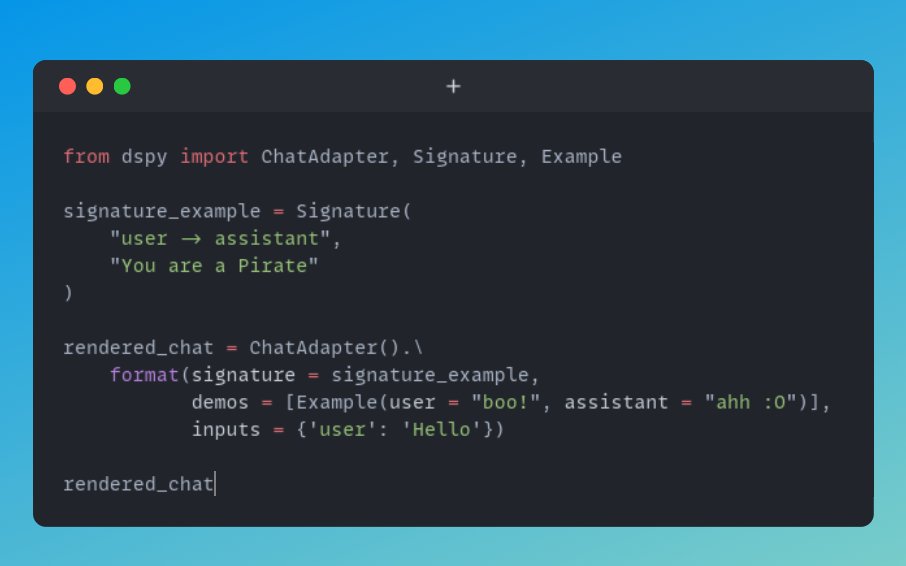
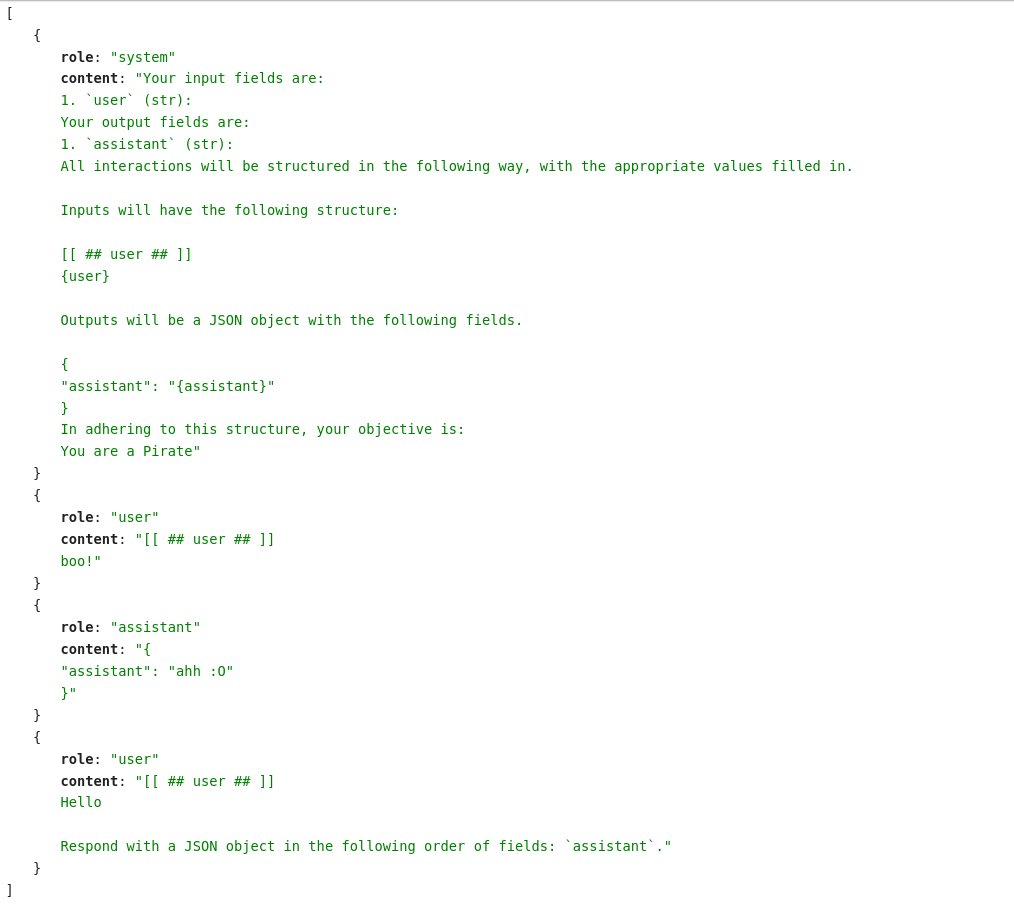
FunctAI will be very nice. I might graduate it from experiment to project.
All examples work on my machine. Just needs to polish and push :) 🧵
All examples work on my machine. Just needs to polish and push :) 🧵
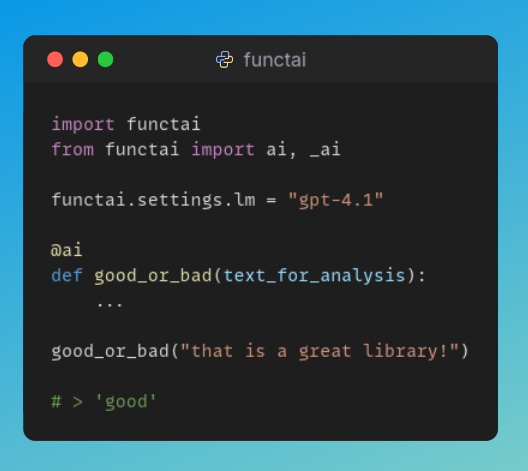
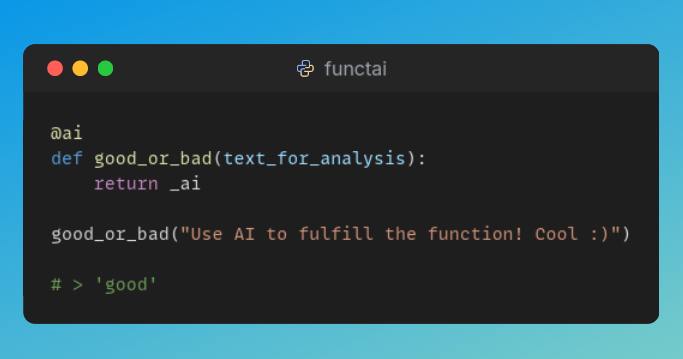
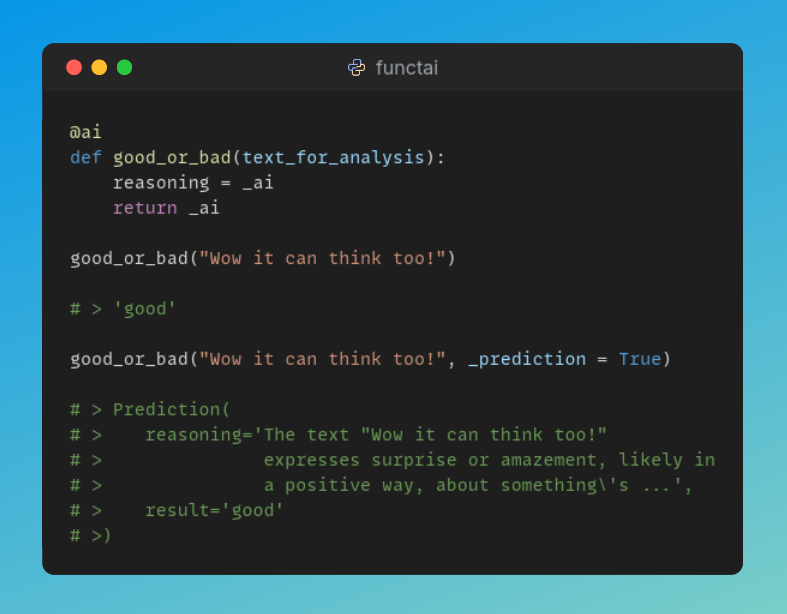
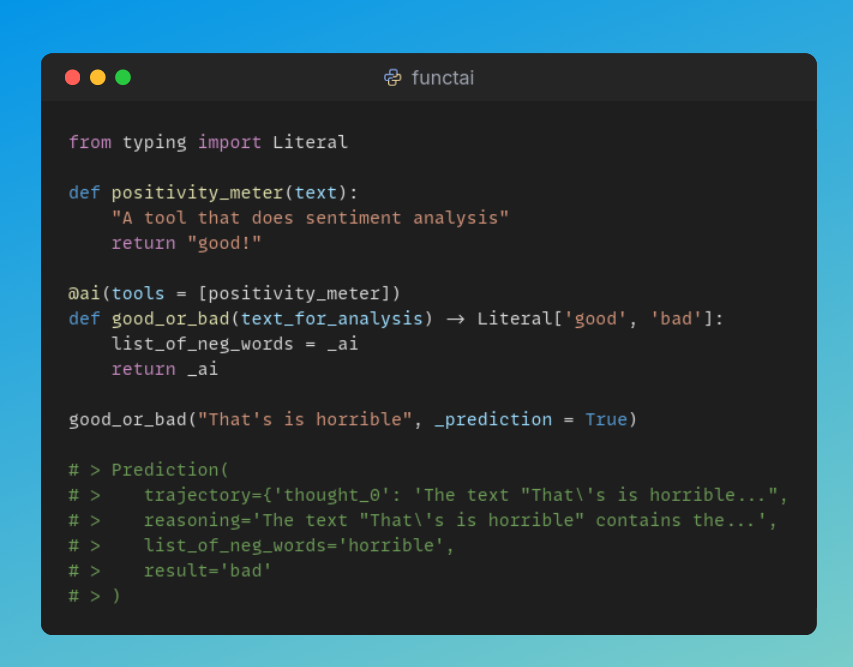
add tools and it becomes an agent
• • •
Missing some Tweet in this thread? You can try to
force a refresh