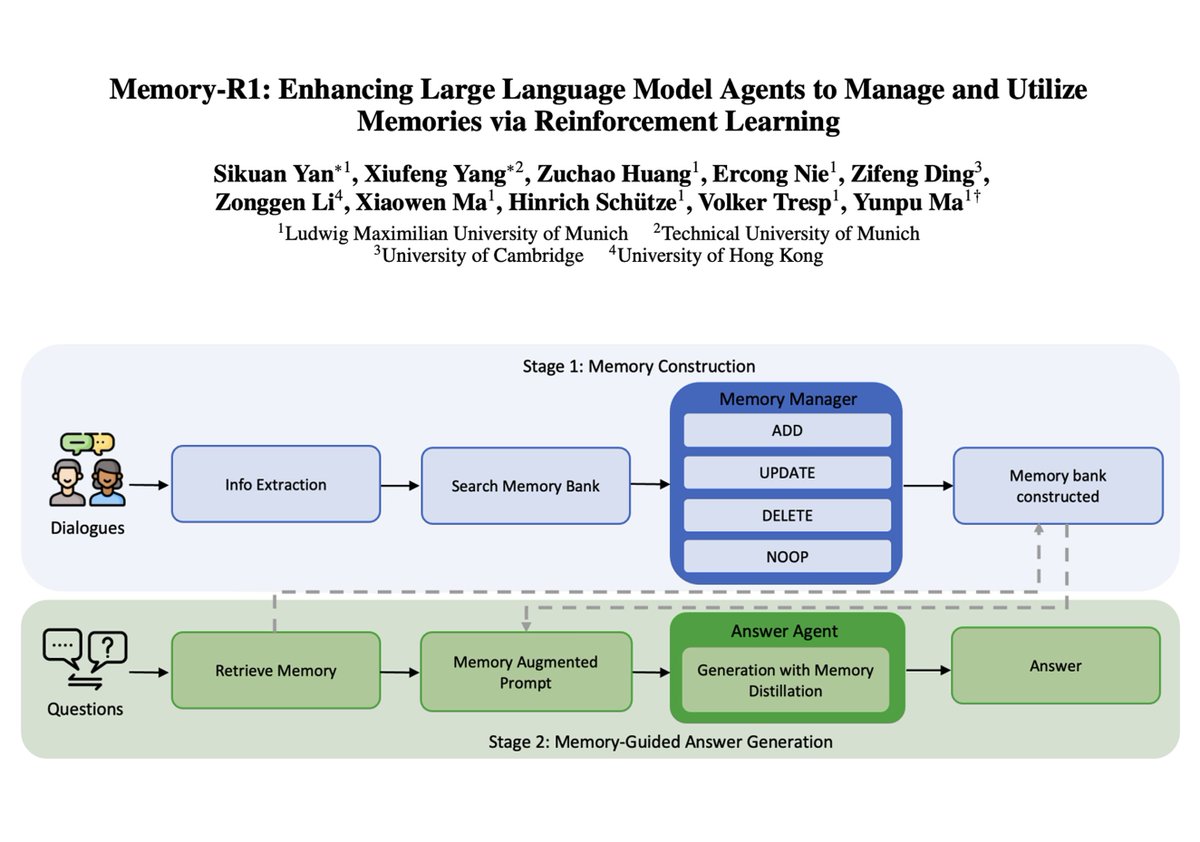
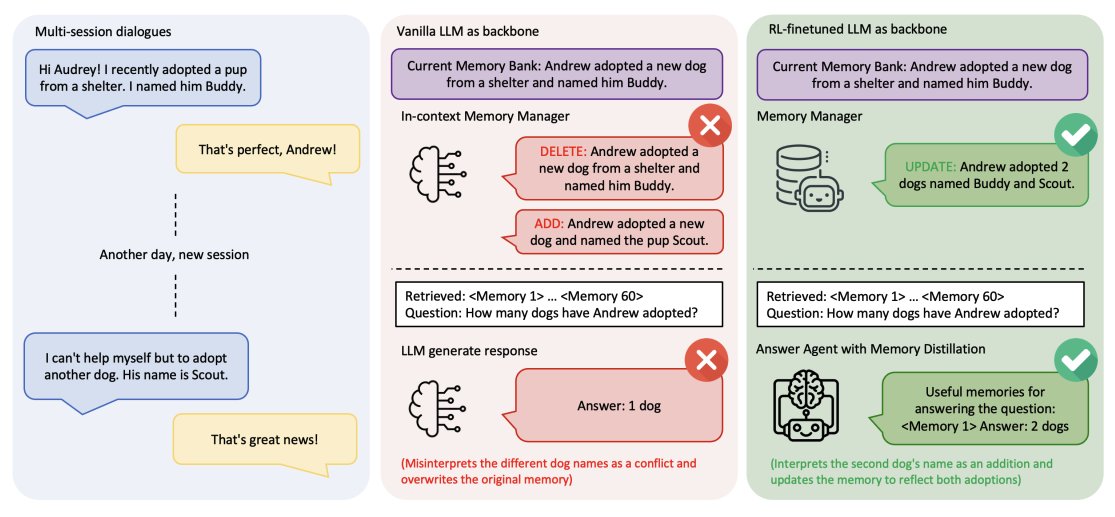
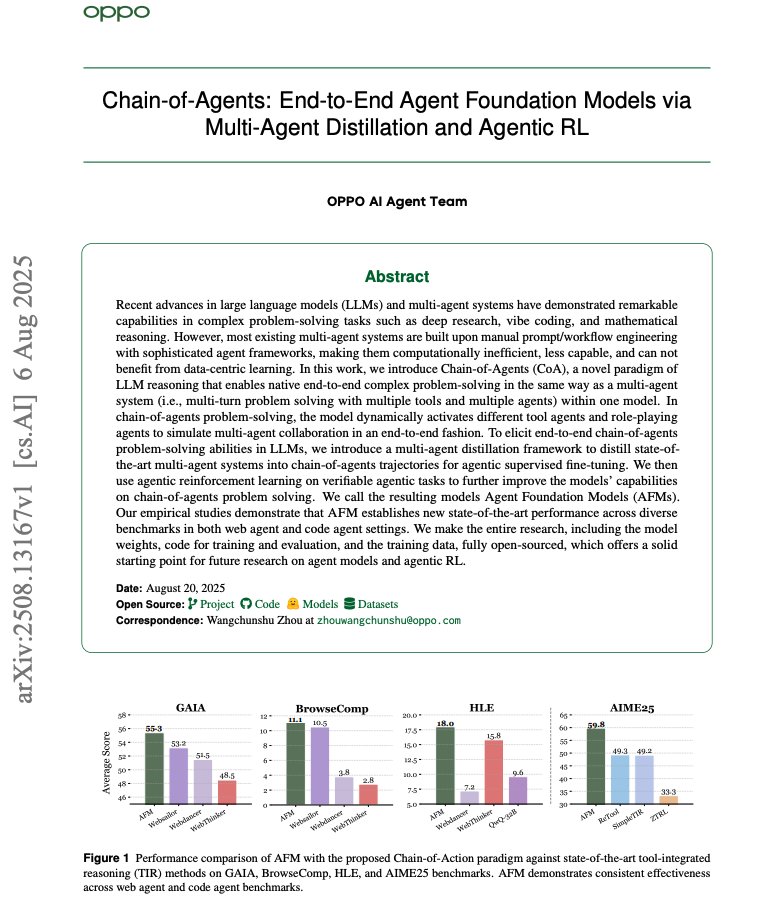
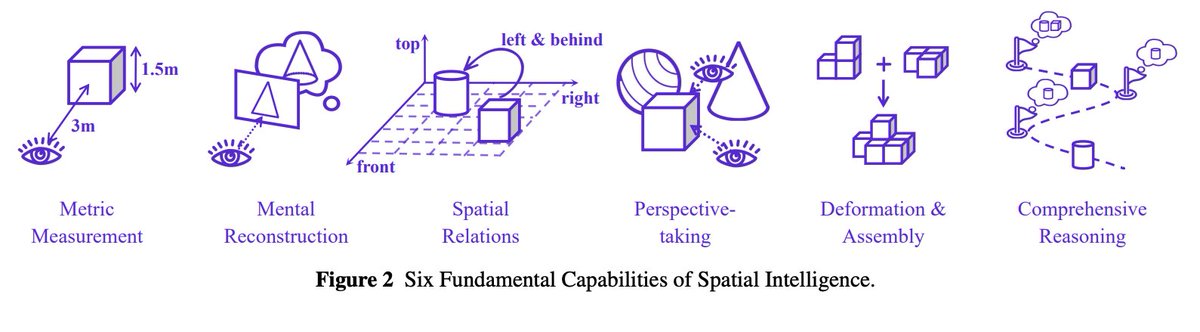
Overview of Self-Evolving Agents
There is a huge interest in moving from hand-crafted agentic systems to lifelong, adaptive agentic ecosystems.
What's the progress, and where are things headed?
Let's find out:
There is a huge interest in moving from hand-crafted agentic systems to lifelong, adaptive agentic ecosystems.
What's the progress, and where are things headed?
Let's find out:

This survey defines self-evolving AI agents and argues for a shift from static, hand-crafted systems to lifelong, adaptive agentic ecosystems.
It maps the field’s trajectory, proposes “Three Laws” to keep evolution safe and useful, and organizes techniques across single-agent, multi-agent, and domain-specific settings.
It maps the field’s trajectory, proposes “Three Laws” to keep evolution safe and useful, and organizes techniques across single-agent, multi-agent, and domain-specific settings.
Paradigm shift and guardrails
The paper frames four stages: Model Offline Pretraining → Model Online Adaptation → Multi-Agent Orchestration → Multi-Agent Self-Evolving.
It introduces three guiding laws for evolution: maintain safety, preserve or improve performance, and then autonomously optimize.
The paper frames four stages: Model Offline Pretraining → Model Online Adaptation → Multi-Agent Orchestration → Multi-Agent Self-Evolving.
It introduces three guiding laws for evolution: maintain safety, preserve or improve performance, and then autonomously optimize.

LLM-centric learning paradigms:
MOP (Model Offline Pretraining): Static pretraining on large corpora; no adaptation after deployment.
MOA (Model Online Adaptation): Post-deployment updates via fine-tuning, adapters, or RLHF.
MAO (Multi-Agent Orchestration): Multiple agents coordinate through message exchange or debate, without changing model weights.
MASE (Multi-Agent Self-Evolving): Agents interact with their environment, continually optimising prompts, memory, tools, and workflows.
MOP (Model Offline Pretraining): Static pretraining on large corpora; no adaptation after deployment.
MOA (Model Online Adaptation): Post-deployment updates via fine-tuning, adapters, or RLHF.
MAO (Multi-Agent Orchestration): Multiple agents coordinate through message exchange or debate, without changing model weights.
MASE (Multi-Agent Self-Evolving): Agents interact with their environment, continually optimising prompts, memory, tools, and workflows.

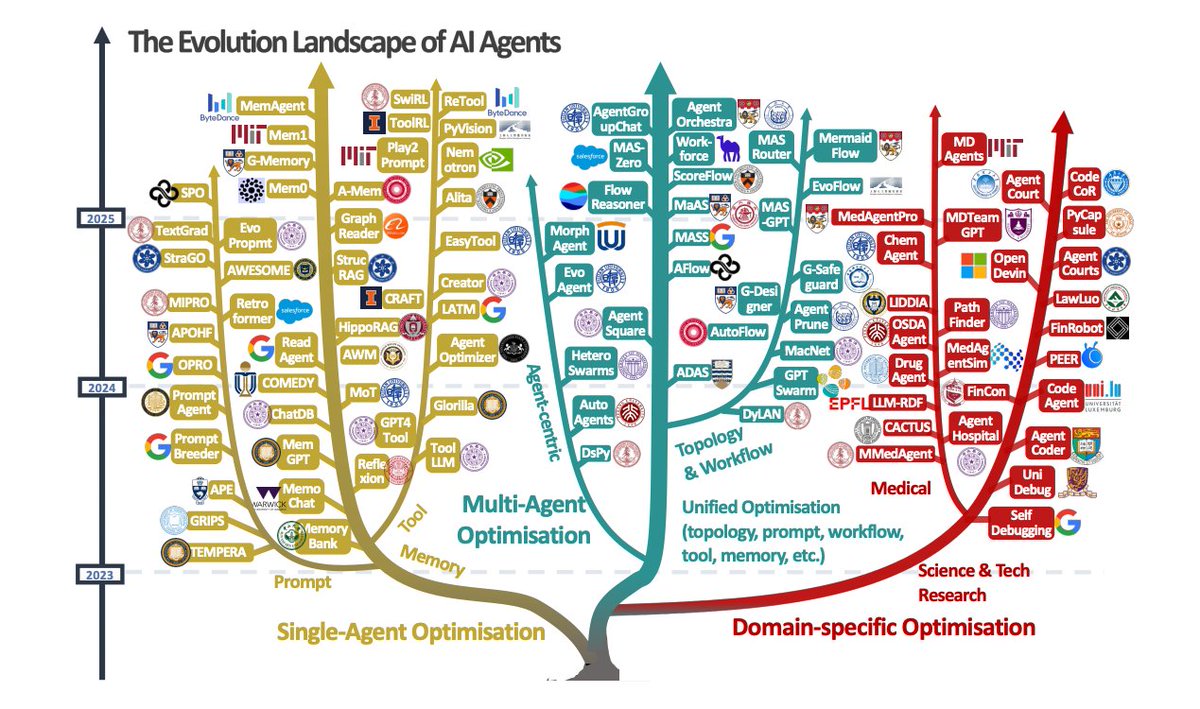
The Evolution Landscape of AI Agents
The paper presents a visual taxonomy of AI agent evolution and optimisation techniques, categorised into three major directions:
single-agent optimisation, multi-agent optimisation, and domain-specific optimisation.
The paper presents a visual taxonomy of AI agent evolution and optimisation techniques, categorised into three major directions:
single-agent optimisation, multi-agent optimisation, and domain-specific optimisation.
Unified framework for evolution
A single iterative loop connects System Inputs, Agent System, Environment feedback, and Optimizer.
Optimizers search over prompts, tools, memory, model parameters, and even agent topologies using heuristics, search, or learning.
A single iterative loop connects System Inputs, Agent System, Environment feedback, and Optimizer.
Optimizers search over prompts, tools, memory, model parameters, and even agent topologies using heuristics, search, or learning.

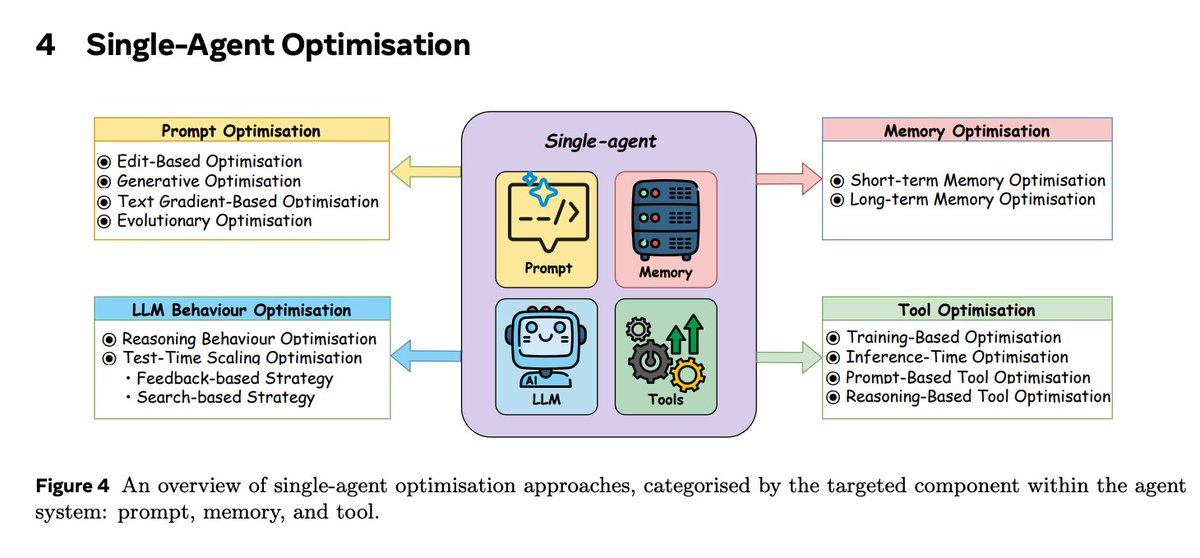
Single-agent optimization toolbox
Techniques are grouped into:
(i) LLM behavior (training for reasoning; test-time scaling with search and verification),
(ii) prompt optimization (edit, generate, text-gradient, evolutionary),
(iii) memory optimization (short-term compression and retrieval; long-term RAG, graphs, and control policies), and
(iv) tool use and tool creation.
Techniques are grouped into:
(i) LLM behavior (training for reasoning; test-time scaling with search and verification),
(ii) prompt optimization (edit, generate, text-gradient, evolutionary),
(iii) memory optimization (short-term compression and retrieval; long-term RAG, graphs, and control policies), and
(iv) tool use and tool creation.
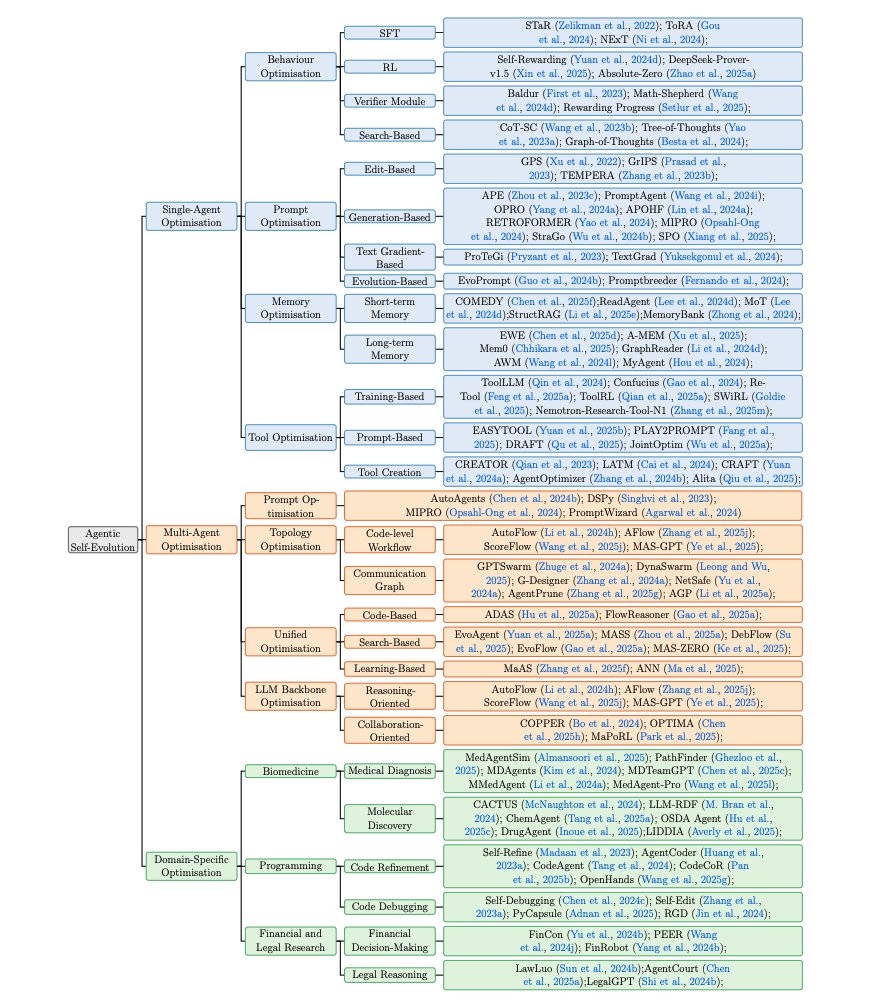
Agentic Self-Evolution methods
The authors present a comprehensive hierarchical categorization of agentic self-evolution methods, including single-agent, multi-agent, and domain-specific optimization categories.
The authors present a comprehensive hierarchical categorization of agentic self-evolution methods, including single-agent, multi-agent, and domain-specific optimization categories.
Multi-agent workflows that self-improve
Beyond manual pipelines, the survey treats prompts, topologies, and backbones as searchable spaces.
It distinguishes code-level workflows and communication-graph topologies, covers unified optimization that jointly tunes prompts and structure, and describes backbone training for better cooperation.
Beyond manual pipelines, the survey treats prompts, topologies, and backbones as searchable spaces.
It distinguishes code-level workflows and communication-graph topologies, covers unified optimization that jointly tunes prompts and structure, and describes backbone training for better cooperation.

Evaluation, safety, and open problems
Benchmarks span tools, web navigation, GUI agents, collaboration, and specialized domains; LLM-as-judge and Agent-as-judge reduce evaluation cost while tracking process quality.
The paper stresses continuous, evolution-aware safety monitoring and highlights challenges such as stable reward modeling, efficiency-effectiveness trade-offs, and transfer of optimized prompts/topologies to new models or domains.
Paper: arxiv.org/abs/2508.07407
Benchmarks span tools, web navigation, GUI agents, collaboration, and specialized domains; LLM-as-judge and Agent-as-judge reduce evaluation cost while tracking process quality.
The paper stresses continuous, evolution-aware safety monitoring and highlights challenges such as stable reward modeling, efficiency-effectiveness trade-offs, and transfer of optimized prompts/topologies to new models or domains.
Paper: arxiv.org/abs/2508.07407

• • •
Missing some Tweet in this thread? You can try to
force a refresh