Everyone is talking about this new OpenAI paper.
It's about why LLMs hallucinate.
You might want to bookmark this one.
Let's break down the technical details:
It's about why LLMs hallucinate.
You might want to bookmark this one.
Let's break down the technical details:

Quick Overview
The paper argues that hallucinations are not mysterious glitches but the predictable result of how LLMs are trained and evaluated.
Pretraining creates statistical pressure to make errors, and post-training benchmarks often reward confident guessing over honest uncertainty.
The fix is to realign mainstream evaluations to stop penalizing abstentions.
The paper argues that hallucinations are not mysterious glitches but the predictable result of how LLMs are trained and evaluated.
Pretraining creates statistical pressure to make errors, and post-training benchmarks often reward confident guessing over honest uncertainty.
The fix is to realign mainstream evaluations to stop penalizing abstentions.

Pretraining inevitably produces some errors
Even if you trained on flawless text, the way models learn guarantees they’ll still slip up sometimes.
That’s because the training goal pushes them to give answers instead of saying “I don’t know.”
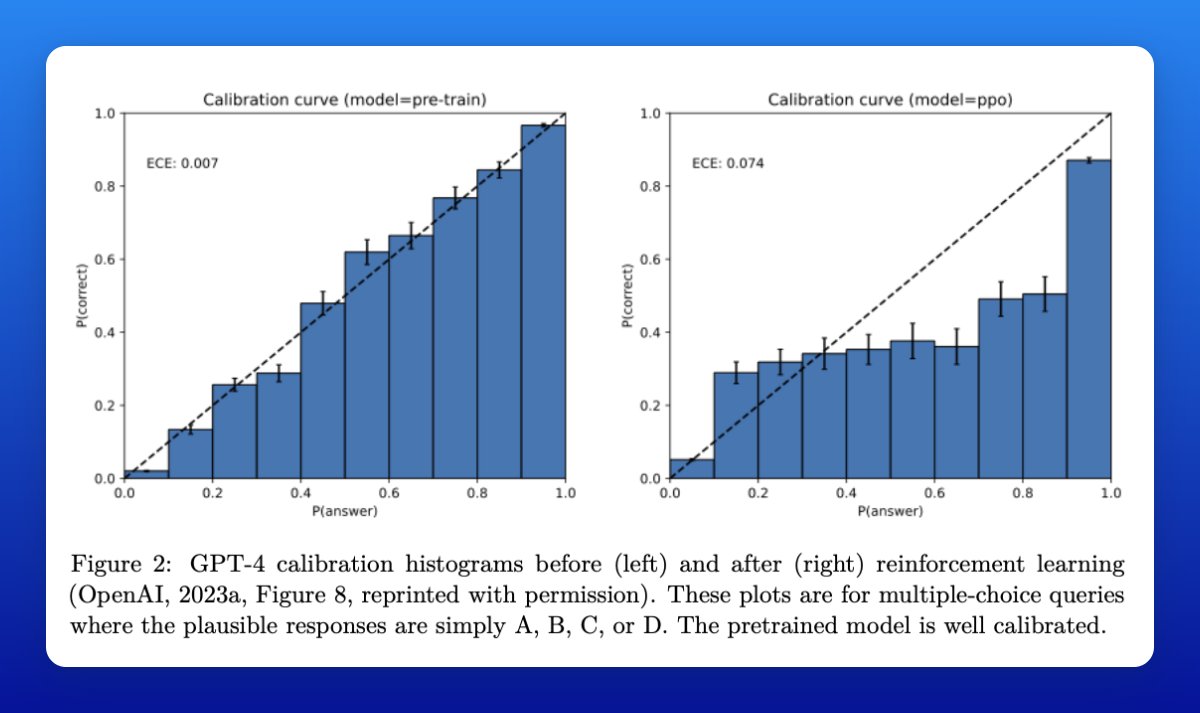
The calibration histograms below illustrate that GPT-4 style base models are well calibrated prior to RL, consistent with this claim.
Even if you trained on flawless text, the way models learn guarantees they’ll still slip up sometimes.
That’s because the training goal pushes them to give answers instead of saying “I don’t know.”
The calibration histograms below illustrate that GPT-4 style base models are well calibrated prior to RL, consistent with this claim.
Arbitrary facts drive a floor on hallucinations.
Details like birthdays or one-off events show up rarely in training data. If a fact appears only once, the model is just as likely to guess wrong later.
So for these “one-shot facts,” hallucinations are baked in.
Details like birthdays or one-off events show up rarely in training data. If a fact appears only once, the model is just as likely to guess wrong later.
So for these “one-shot facts,” hallucinations are baked in.

Weak models add to the problem.
When the model family cannot represent the needed distinctions, errors persist.
The paper formalizes this via an agnostic-learning bound and gives simple cases like multiple choice, where even optimal thresholding leaves a fixed error tied to model capacity, with an example showing classic n-gram models must fail on certain context dependencies.
When the model family cannot represent the needed distinctions, errors persist.
The paper formalizes this via an agnostic-learning bound and gives simple cases like multiple choice, where even optimal thresholding leaves a fixed error tied to model capacity, with an example showing classic n-gram models must fail on certain context dependencies.

Post-training often reinforces guessing
Most benchmarks score models only on right vs. wrong answers.
Saying “I don’t know” gets you zero, while making a confident guess could get you a point.
That system rewards bluffing, so models learn to “sound sure” even when they’re not.
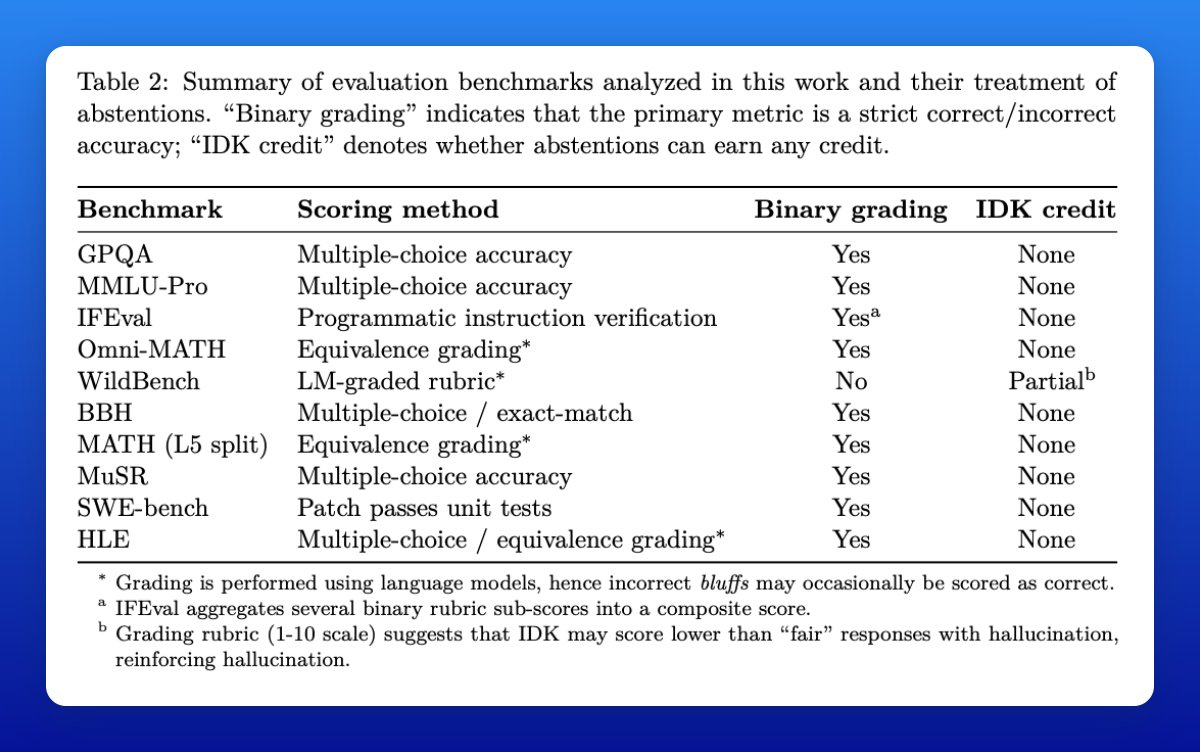
The authors survey widely used leaderboards and find abstentions largely penalized, explaining why overconfident hallucinations persist despite mitigation efforts.
Most benchmarks score models only on right vs. wrong answers.
Saying “I don’t know” gets you zero, while making a confident guess could get you a point.
That system rewards bluffing, so models learn to “sound sure” even when they’re not.
The authors survey widely used leaderboards and find abstentions largely penalized, explaining why overconfident hallucinations persist despite mitigation efforts.
The fix is to reward honesty
The authors suggest changing benchmarks so models aren’t punished for admitting uncertainty.
If we add clear rules about when to guess and when to abstain, models will learn to only answer when they’re reasonably confident.
This promotes behavioral calibration, where models choose between answering and abstaining according to the target confidence, and should steer the field toward more trustworthy systems.
Paper:
cdn.openai.com/pdf/d04913be-3…
The authors suggest changing benchmarks so models aren’t punished for admitting uncertainty.
If we add clear rules about when to guess and when to abstain, models will learn to only answer when they’re reasonably confident.
This promotes behavioral calibration, where models choose between answering and abstaining according to the target confidence, and should steer the field toward more trustworthy systems.
Paper:
cdn.openai.com/pdf/d04913be-3…

• • •
Missing some Tweet in this thread? You can try to
force a refresh